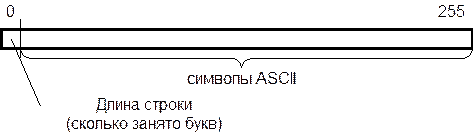Именно это правило заложено в компилятор, и, как следствие этого есть риск создать неправильно понимаемые условия.
Примеры:
If a > b then max := a;
If c = d then writeln(‘c=d’);
{Найти минимальное и максимальное значения среди двух чисел a и b}
If a<b then
If a>b then begin
Max := a;
Min := b;
end
Еlse writeln(‘Числа равны’)
Else begin
Max := b;
Min := a;
End;
Правильный вариант
If <У1> then
if <У2> then <Д1>
Else
else <Д2>;
Неправильный вариант
If <У1> then
if <У2> then <Д1>
else <Д2>;
В следующем примере ошибка, связанная с тем, что else принадлежит ближайшему незавершенному If.
При записи условий могут использоваться простые и сложные логические выражения: a > b { простое логическое выражение }
c+d*2 = a { тоже простое выражение }
Сложные логические выражения составляются при помощи логических операций and, or, not, xor(см.§ 1.5.1.).
2.3. Оператор выбора (варианта).
Оператор варианта необходим в том случае, когда в зависимости от значения какой-либо переменной надо выполнить те или иные операторы, в том числе и составные. Если вариантов два, то можно обойтись и условным оператором, а если их несколько, то лучше использовать Case. Структура оператора варианта имеет вид:
Case <Параметр выбора> of
<1-е значение параметра выбора>: <Оператор1>;
<2-е значение параметра выбора>: <Оператор2>;
...
<n-е значение параметра выбора>: <Операторn>;
...
<k-ый набор значений параметра выбора>: <Операторk>;
...
[else <Альтернативный оператор>;]
end;
Параметр выбора (переменной или выражения) должен быть строго перечислимого типа (включая типы Char и Boolean), диапазоном или целочисленным типом, все прочие типы не будут пропущены компилятором. Набор значений – это конкретные значения управляющей переменной или выражения, при которых необходимо выполнить соответствующий оператор, игнорируя остальные варианты. Если в наборе несколько значений, то они отделяются друг от друга запятой, можно указывать диапазоны значений. В записи оператора допускается необязательная часть Else, которая будет выполнена, если значение переменной выбора не совпало ни с одним из перечисленных значений.
Примеры:
{ Определить символ ]
Case ch of { ch: char }
‘.’, ’!’, ‘?’: WriteLn(‘Знаки припинания’);
‘0’..’9’: WriteLn(‘Цифры’);
‘;’: WriteLn(‘Точка с запятой’);
‘A’..’Z’,
‘А’..’Я’: begin
WriteLn(‘Заглавные буквы.’);
WriteLn(‘Русские или латинские.’);
end;
else WriteLn(‘Неопознанный символ’);
end;
{ Вычислить значение функции }
N := Trunc(x);
Case N of { N: byte }
1: y := a*Sqr(x);
2: y := a*x*x*x;
3: y := a*Sqr(Sqr(x));
4: y := a*Sqr(Sqr(x)*x;
else WriteLn(‘функция не’, ‘определена по значению’);
end;
аx2, 1 <= x < 2;
y(x) = ax3, 2 <= x < 3;
ax4, 3 <= x < 4;
ax5, 4 <= x < 5;
Оператор Case очень удобен и, как правило, более эффективен, чем несколько операторов IF того же назначения, Эффективность его в смысле скорости будет максимальной, если размещать наиболее вероятные значения (или их наборы) первыми в порядке следования.
2.4. Операторы цикла.
В практике программирования циклы – выполняющиеся повторения одних и тех же простых или составных операторов – играют очень важную роль. Существует три различных способа организации цикличных вычислений.
2.4.1. Итеративный (цикл с шагом).
Данный тип цикла является «строгим», т.е. выполняет действие заданное число раз. Синтаксис цикла с параметром следующий:
for <Параметр цикла> := <Начальное значение> to <Конечное значение> do
<Оператор>; { шаг = 1 }
for <Параметр цикла> := <Начальное значение> downto <Конечное значение> do
<Оператор>; { шаг = -1 }
На блок-схеме алгоритма цикл обозначается следующей структурой:
Оператор, представляющий тело цикла, может быть простым, составным или пустым (в этом случае после Do сразу ставится «;»).
Примеры (сколько раз выполниться цикл?):
for i := 1 to 3 do; { 7 раз i: Integer, byte, ... }
for ch := ‘a’ to ‘d’ do; { 4 раза ch: char }
for i := 5 to 5 do; { 1 раз }
for i := 7 to 1 do; { ни разу }
for i := 7 downto 1 do; { 7 раз }
for i := -7 to 7 do; { 15 раз }
for i := 3.5 to 5.5 do; { Ошибка!!! Не перечислимый тип }
for i := True to False do; { ни разу }
for ch := ‘А’ to ‘Я’ do; { ? раз }
for ch := ‘а’ to ‘я’ do; { ? раз }
В двух последних строчках число повторений зависит от кодировки, установленной на компьютере.
Далее приведены основные правила, необходимые для использования оператора for:
1. Параметр цикла, начальное значение и конечное должны быть перечислимого типа.
2. Количество итераций вычисляется по формуле: <Кол-во операций> = <Конечное значение> - <Начальное значение> +(-) 1
3. Параметр цикла внутри цикла переопределять нельзя.
For i:= i+5 to n do ;
For i:= 1 to n do i := i+5;
4. Параметр цикла за пределами цикла считается неопределенным.
5. Заголовок цикла читается только один раз.
Компилятор несоблюдение правила № 2 «не замечает», но программа с приведенными заголовками не заслуживает никакого доверия.
Итеративные циклы – очень быстрые и генерируют компактный выполнимый код, но правила №1-2 ограничивают их применение.
Циклы For предполагают вложенность при условии, что никакой из вложенных циклов, наряду с другими операторами, не использует и не модифицирует переменные – параметры внешних циклов.
2.4.2. Цикл с предусловием.
Синтаксис цикла с предусловием следующий:
While <Условие входа в цикл> do <Оператор>;
На блок-схеме алгоритма цикл обозначается следующей структурой:
Оператор («тело цикла») будет выполняться до тех пор, пока выполняется логическое условие, т.е. пока значение «Условия» равно True. Само условие может быть логической константой (возможен «вечный цикл»), переменной или выражением с логическим результатом. Условие проверяется перед выполнением каждой итерации, поэтому если условие сразу не выполняется, то «тело цикла» игнорируется и оператор (простой или составной) выполняться не будет.
Основные правила, которые необходимо соблюдать для правильного использования цикла While:
1. Перед выполнением цикла всем значениям, участвующим в вычислениях, должны быть присвоены начальные значения (иначе вычисления могут быть выполнены некорректно). Это касается как переменных, участвующих в вычислении условия, так и в действии;
2. Чтобы программа не «зациклилась», действие (оператор) должно влиять на условие выполнения цикла;
3. Переменная цикла должна изменяться внутри цикла принудительно, в явной форме;
4. За пределами цикла переменная цикла сохраняет свое значение.
5. Переменная цикла может иметь любой числовой тип.
Так как цикл While допускает все, что угодно внутри себя, тело цикла может содержать другие, вложенные в него, циклы (количество уровней вложенности определяется сложностью программы.).
2.4.3. Цикл с постусловием.
Синтаксис цикла с постусловием следующий:
Repeat
<Оператор1>;
<Оператор2>;
...
<ОператорN>;
Until <Условие выхода из цикла>;
Данный цикл используется в том случае, когда по логике алгоритма необходимо проверять условие завершения вычислений после очередной итерации, поэтому тело цикла выполняется всегда хотя бы один раз. Это имеет значение лишь на первом шаге вычислений, далее цикл ведет себя точно так же, как и цикл While.
На блок-схеме алгоритма цикл обозначается следующей структурой:
Repeat
Until False; { Вечный цикл }
Замечание: В силу своей гибкости циклы While и Repeat используются для контроля ввода переменных.
Примеры:
{Вычисление значения факториала N!= 1*2*3*4*5*…*N}
Var n, i : Byte;
N_Fact:LongInt;
Begin
Write(‘Введите n<10’);
ReadLn(n);
N_Fact:=1;
i:=1;
Repeat
N_Fact:= N_Fact*i;
Inc(i);
Until i>n;
Write(‘Факториал=’, N_Fact);
end.
Var n, i : Byte;
N_Fact:LongInt;
Begin
Write(‘Введите n<10’);
ReadLn(n);
N_Fact:=1;
For i:=2 to n Do
N_Fact:= N_Fact*i;
Write(‘Факториал=’, N_Fact);
end.
Var n, i : Byte;
N_Fact:LongInt;
Begin
Write(‘Введите n<10’);
ReadLn(n);
N_Fact:=1;
i:=2;
While i<= n Do Begin
N_Fact:= N_Fact*i;
Inc(i);
End;
Write(‘Факториал=’, N_Fact);
end.
For While Repeat
При вычислениях необходимо помнить о том, чтобы правильно выбрать тип результата. Это особенно касается переменных, хранящих значения произведений (типа факториала), так как значение результата «растет» очень быстро и в результате может произойти переполнение.
В рассмотренных выше примерах вводилось ограничение на диапазон входного значения (n<10). Для того, чтобы программа корректно отработала, необходимо, чтобы контроль ввода осуществлялся в явном виде.
Для этого программист должен взять контроль «на себя» и отработать все «критические» ситуации, которые могут привести к аварийному завершению программы и досрочному ее завершению. Компилятор жестко контролирует при выполнении программы границы массивов и соответствие типов. Этим контролем можно управлять (включать или отключать при необходимости). Достаточно при этому компилятору указать, каким образом ему действовать в той или иной ситуации – задать соответствующую директиву специальным комментарием.
{$R -} – выключить контроль границ массивов;
{$R +} – включить контроль границ массивов;
{$I -} – выключить контроль ввода;
{$I +} – включить контроль ввода.
Write(‘Введите значение N<10’);
Repeat
{$I-} Readln(n); {$I+}
If IOResult=0 then
Else Write(‘неправильный ввод’);
Until IOResult=0;
Write(‘Введите значение N<10’);
{$I-} Readln(n); {$I+}
While IOResult<>0 do Begin
Write(‘неправильный ввод’);
{$I-} Readln(n); {$I+}
End;
Для проверки правильности ввода нужно использовать системную переменнуюIOResult типа Integer (Input/Output Result – результат операции ввода/вывода). IOResult=0, если ввод произведен правильно.
Добавим контроль диапазона числа:
3. Основные структурные типы языка.
При программировании реальных задач необходимым условием удачного решения является правильный выбор формы представления данных. Каждый тип данных определяет вид действий над ними. От того, насколько программное представление соответствует структуре обрабатываемых данных, зависит размер и эффективность программы.
3.1. Массивы.
3.1.1. Описание массивов.
Массив - это регулярная структура, расположенная в памяти последовательно и имеющая имя. Для объявления массивов используется специальная конструкция языка, которая имеет следующий вид:
Array [ Диапазоны индексов ] of ТипКомпонентов
Наиболее часто массивы используются для хранения дискретных последовательностей чисел (так называемых векторов или матриц). При объявлении массивов необходимо соблюдать лишь два требования:
1. Если диапазон – числовой, то он обязан «уместиться» в тип Word;
2. Произведение количества компонентов массива на размер компонента в байтах не может превышать 65520 байт (почти 64 Кбайт). Это требование является общим для всех структур данных языка Pascal.
Таким образом, массивы могут быть описаны так
Var <Имя массива>:
array [<Начальное значение индекса> ..
<Конечное значение индекса>] of <Тип элементов массива>;
Var a: array [1..10] of Real;
Так хранится в памяти одномерный массив из 10 вещественных чисел.
Примеры объявления массивов:
1).{ объявление вектора из 10 элементов типа Real }
const N_max = 10;
var a: Array [ 1 .. N_Max ] of Real;
2). (* такое объявление удобнее *)
const N_max = 10;
Type Vector = Array [ 1 .. N_max ] of Real;
var a: Vector;
b: Array [1..n] of Real;
c,d: Vector;
С точки зрения транслятора Pascal a и b разные, а cи d одинаковые и можно выполнять групповые присваивания (операции).
3). Const nmax = 10;
nmin = -2;
Type Vector = Array [ nmin .. nmax ] of Real;
{ 13 элементов }
VectorChar = array [‘a’..’z’] of char; { 26 элементов }
var a: Vector;
b: VectorChar;
Switch : Array [ Boolean ] of Byte;
Как видно из третьего примера, ничто не обязывает объявлять диапазон индексов массива числами от 1 до N_max, в качестве индексов можно использовать любые перечислимые типы, как встроенные, так и вводимые пользователем. Если диапазон соответствует всему типу, то вместо него можно записать просто имя этого перечислимого типа.
Рассмотренные массивы – одномерные, то есть такие, у которых компоненты – скаляры. Разрешено объявлять массивы массивов (матрицы).
const N_Max = 5;
M_Max = 6;
Type Matrix = array [ 1 .. N_Max , 1 .. M_max] of Real;
Type Matr_Sqr = array [ 1..N_Max, 1 .. N_Max ] of Real;
var a: Matrix; {матрица n x m}
b : Matr_Sqr; {квадратная матрица}
Другое описание двумерного массива (вектор векторов) выглядит следующим образом:
const n = 5; m = 6; {объявление матрицы размером n x m}
Type Vector = array [1..m] of Real;
Matrix = array [1..n] of Vector;
var a: Vector;
Расположение матрицы в памяти компьютера
…
1строка( m элементов) 2 строка (m элементов)
b: Matrix;
Первый вариант описания матрицы более наглядный, так как позволяет сразу определить размеры «таблицы», в которой будут храниться данные.
Замечание: рекомендуется описывать массивы, используя раздел констант и типов для быстрого изменения не только описания, но и для минимальных исправлений по дальнейшему тексту программы.
В многомерных массивах (количество измерений формально не ограничено) каждое измерение не зависит от остальных, поэтому можно объявлять массивы с разными индексами:
Var M: Array [ -10..10, ‘A’ .. ‘D’, Boolean ] of Byte;
Эквивалентная запись выглядит следующим образом:
Var M: Array [ -10..10 ] of
Array [‘A’ .. ‘D’] of
Array [Boolean] of Byte;
Тип элемента массива М зависит от числа указанных в нем индексов:
M[0] – массив-матрица типа Array [‘A’..’D’, Boolean] of Byte;
M[0,’A’] – вектор типа Array [ Boolean ] of Byte;
M[0,’A’, True] – значение типа Byte.
При таком описании массивов необходимо помнить о совместимости типов при выполнении операции присваивания.
Type ArrayBType = Array [ Boolean ] of Byte;
ArrayCType = Array [‘A’ .. ‘D’ ] of ArrayBType;
ArrayMType = Array [-10 .. 10] of ArrayCType;
Var B,А: ArrayBType;
C: ArrayCType;
M: ArrayMType;
Begin
M[0] := C;
B := M[0,’A’];
A := B;
End.
В Turbo Pascal’e разрешается записывать индексы не только через запятую, но и отдельно:
M[ 0, ’A’, True ] тождественно M[0] [’A’] [True]
В памяти компьютера массивы располагаются последовательно (первая строка, вторая строка и т.д.), быстрее всего изменяется самый «дальний» индекс, если их несколько. Для определении стартового значения массива (в разделе констант) необходимо задавать значения так, как они будут располагаться в памяти (без учета скобок):
Замечание: Тип можно формировать прямо в описании переменной, но предпочтительнее использовать введенное ранее имя этого типа.
При компиляции программы Turbo Pascal контролирует принадлежность индекса указанному диапазону (по умолчанию ключ компилятора установлен в положение {$R+}) и в случае нарушения границ диапазона программа прерывается с выдачей сообщения об ошибке 201 ( Range Check Error ). В режиме компиляции {$R-} никаких проверок не производиться и некорректное значение индекса извлечет какое-нибудь значение, не принадлежащее данному массиву. Поэтому при отладке программы необходимо использовать ключ {$R+}, а при эксплуатации {$R-}, в это несколько уменьшает размер Exe-файла и время его выполнения.
Адрес начала массива в памяти соответствует адресу его первого элемента (элемента с минимальными значениями индексов).
Замечание: Работа с элементами массива занимает больше времени, чем со скалярной переменной (необходимо вычислять местоположение элемента в памяти). Поэтому, если какой-то элемент массива используется многократно, то его лучше переписать в скалярную переменную.
3.1.2. Ввод и вывод массивов.
Ввод массивов можно организовать по-разному: для одномерных массивов (векторов) – в строку или в столбец; для двумерных ( матриц ) – по строкам или по столбцам.
{Ввод вектора в столбец }
for i = 1 to n do RealLn(a[i]); { Можно но не нужно! }
{ Лучше ввод организовать так: }
WriteLn(‘Введите элементы вектора:’);
for i := 1 to n do begin
Write(‘a[‘, i, ’] = ’);
ReadLn( a[i] );
end;
{ Вывод вектора: }
Writeln(‘Результирующий вектор: ’);
for i := 1 to n do Write(a[i], ‘_‘);
WriteLn;
{Ввод матрицы по строкам }
for i = 1 to n do Begin
for j := 1 to m do
Real(a[i,j]);
ReadLn;
End;
{ Лучше ввод матрицы организовать так: }
WriteLn(‘Введите элементы матрицы:’);
for i := 1 to n do begin
WriteLn( ‘Введите элементы ‘,i,’-ой строки матрицы’);
for j := 1 to m do Begin
Write( ‘a[‘, i, ‘,’ , j,’] = ’);
ReadLn(a[i,j]);
End;
End;
{Вывод матрицы по строкам }
Writeln(‘Результирующая матрица’);
for i := 1 to n do begin
for j := 1 to m do Write(a[i,j], ‘_‘);
WriteLn;
end;
3.1.3. Форматы вывода.
Для удобства вывода при выводе данных лучше использовать так называемый «форматный вывод», когда под каждую выводимую переменную отводится определенное количество позиций
Write( a [ :F [ :n ] ] ); { [ ] здесь означают необязательность }
F - общее число позиций, отводимое переменной (если необходимо вывести больше, то F игнорируется).
n - число знаков после десятичной точки (употребляется только для вывода действительных чисел).
Примеры:
a: real; { a = 354.78 }
Write(a); { 0.3547800000E+03 => 0.35478*103 }
Write(a:8:4); { 345.4700 }
I: Integer; { I = 371 }
Write (I:8); {_ _ _ _ _371 }
Write (I:-8); { 371 }
Write (a:6:2); { a = 15.448 }
{ _ 15.45 }
Write ( <...> ); { Просто выводит информацию на экран }
WriteLn( <...> ); { Выводит на экран и переводит курсор на следующую строку }
WriteLn; { переводит курсор на следующую строку }
Write ('сообщение пользователя': 50); {можно центрировать по ширине }
3.1.4. Базовые алгоритмы обработки векторов.
Описательная часть
var a: array [1..n] of <T>;
min, max : <T>;
Number : Byte;
1 вариант
S:=0;
For i:=1 to n do S:=S+a[i];
2 вариант
S:=a[1];
For i:=2 to n do S:=S+a[i];
1). Сумма элементов массива:
2). Найти произведение четных элементов:
p:=1;
for i:=1 to n do
if a[i] mod 2=0 then p:=p*a[i];
3). Найти минимальный элемент массива:
min:=a[i];
for i:=2 to n do
if a[i]<min then min:=a[i];
4). Найти минимальный элемент и его номер:
{1 вариант}
min:=a[1]; number:=1;
for i:=2 to n do
if a[i]<min then begin
min:=a[i];
number:=i;
end;
write(min,’ ’,number);
{2 вариант}
number:=1;
for i:=2 to n do
if a[i]<a[number] then number :=i;
write(a[number],number);
3.1.5. Алгоритмы поиска.
i := 0;
Repeat
inc(i);
Until (i >n) or (a[i] = x);
if i > n then
write(‘Такого элемента нет’)
else
write(‘Это элемент с номером’ ,i);
i:=1;
while (i<=n) and (a[i]<>x) do inc(i);
if n>i then
write(‘Такого элемента нет’)
else
write(‘Это элемент с номером’ ,i);
1). Поиск заданного элемента в неупорядоченном массиве:
i := 1;
While (a[i] <> x) and (i <= n) do
inc(i);
i := 1;
While a[i] <> x do
inc(i);
Алгоритм содержит ошибку: выход за границу массива при отсутствии элемента.
При другой реализации программы возможны скрытые ошибки (не рекомендуется изменять переменную цикла внутри цикла).
k := 0;
for i := 1 to n do
if a[i] = x then begin
k := i;
i := n; { <— Возможна ошибка }
end;
2). Найти в массиве максимальное четное число:
i:=1; {поиск первого четного элемента вектора}
while (i<=n) and (a[i] mod 2=1) do inc(i);
if i>n then write(‘Четных элементов нет’)
Else begin {четный элемент найден}
max:=a[i];
for k:=i+1 to n do
if (a[k] mod 2=0) and (a[k]>max) then max:=a[k];
Write(‘max=’, max);
end;
3). Алгоритм поиска последнего отрицательного элемента.
Правильный и наиболее оптимальный алгоритм.
i := n+1;
repeat
dec(i);
until (i < 1) or (a[i] <0);
Правильный, но не оптимальный.
k := 0;
for i := 1 to n do
if a[i] = x then k := i;
В другой вектор
For i : = 1 to n-1 Do
B[n-i+1] : = a[ i ];
Сам в себя
For j : = 1 to n div 2 Do begin
v := a[i];
a[i] := a[n-i+1];
a[n-i+1] := v;
end;
4). Инвертирование вектора.
3.1.6. Базовые алгоритмы обработки матриц.
1). Сумма элементов матрицы.
S := 0;
for i := 1 to n do
for j := 1 to m do
S := S + a[i,j];
2). Сумма элементов под главной диагональю (диагональ учитывается).
S := 0;
for i := 1 to n do
for j := 1 to i do
S := S + a[i,j];
3). Сумма элементов над главной диагональю (диагональ учитывается).
S := 0;
for i := 1 to n do
for j := i to n do
S := S + a[i,j];
4). Сумма над побочной диагональю.
S := 0;
for i := 1 to n do
for j := 1 to n-i+1 do
S := S + a[i,j];
5). Сумма под побочной диагональю.
S := 0;
for i := 1 to n do
for j := n-i+1 to n do
S := S + a[i,j];
6). Сумма элементов над главной и побочной диагоналями.
S := 0;
for i := 1 to (n+1) div 2 do
for j := 1 to n-i+1 do
S := S + a[i,j];
7). Сумма под главной и побочной диагоналями.
S := 0;
for i := n div 2 +1 to n do
for j := n-j+1 to i do
S := S + a[i,j];
8). Сумма слева от главной и побочной диагоналей.
S := 0;
for i := 1 to (n+1) div 2 do
for j := 1 to n-i+1 do
S := S + a[i,j];
9). Сумма справа от главной и побочной диагоналей.
S := 0;
for i := n div 2 +1 to n do
for j := n-j+1 to i do
S := S + a[i,j];
10). Сумма элементов главной диагонали.
S := 0;
for i := 1 to n do S := S + a[i,i];
11). Сумма элементов побочной диагонали.
S := 0;
for i := 1 to n do S := S + a[i,n-i+1];
12). Транспонирование матрицы.
var a: array [1..n,1..m] of <T>; {T – заданный тип}
b: array [1..m,1..n] of <T>;
...
Begin
for i := 1 to n do
for j := 1 to m do
b[i,j] := a[j,i];
End.
13). Транспонирование матрицы в самой себе (относительно главной диагонали).
var a: array [1..n,1..n] of <T>;
V: <T>;
...
Begin
for i := 2 to n do
for j := 1 to i-1 do begin
V := a[j,i];
a[j,i] := a[i,j];
a[i,j] := V;
end;
14). Умножение матриц ( A(n x m) x B(m x l) = C(n x l))
For i:=1 to n do
For j:=1 to m do begin
c[i,j]:=0;
For k:=1 to l do c[i,j]:=c[i,j]+a[i,k]*b[k,j]
End;
15). Поменять местами k и l строки в матрице:
Const n_max=10; m_max:=15;
Type
Matrix=array[1..n_max,1..m_max] of Real;
Var A, B, C: Matrix;
R: real; i, n, k,l : Byte;
Const n_max=10; m_max:=15;
Type vector=array[1.n_max] of Real;
Matrix=array[1..m_max] of vector;
Var A, B, C: Matrix;
R: Vector; k, l :Byte;
Begin
For i:=1 to n do Begin
R:=a[k,i]; a[k,i]:=a[l,i]; a[l,i]:=R;
End;
End.
Begin
R:=a[k];
a[k]:=a[l];
a[l]:=R;
End.
Замечание: Описание массива влияет на программную реализацию алгоритма.
3.1.7. Алгоритмы сортировки массивов.
Для упорядочивания массивов по разным признакам (по возрастанию, по убыванию, по невозрастанию, по неубыванию и т.д.) применяют алгоритмы сортировки, при которых элементы в массиве меняют свое месторасположение в зависимости от условия сортировки. Известно большое количество алгоритмов [1], но в учебных целях используются наиболее простые из них.
Для вектора из n элементов делается (n-1) просмотр, в каждом просмотре сравниваются попарно элементы, начиная с первого, если предыдущий элемент больше последующего, их меняют местами. После каждого просмотра очередной наибольший элемент встает на свое место (сортировка по возрастанию).
2). Сортировка посредством выбора.
Находится минимальный элемент массива и меняется местами с первым. Среди оставшихся элементов ( то есть начиная со второго) опять находится минимальный и меняется местами со вторым и процесс повторяется.
For i:=1 to n-1 do Begin
min:=i;
for j:=i+1 to n do
if a[j]<a[min] then min:=j;
r:=a[min]; a[min]:=a[i]; a[i]:=r;
End;
3.1.8. Совместные алгоритмы обработки матриц и векторов.
1). По матрице А(n x m) получить вектор, элементы которого равны сумме элементов строк матрицы:
For i:=1 to n do Begin
S:=0;
For i:=1 to m do S:=S+a[i,j];
b[i]:=S;
End.
2). По матрице А(n x m) получить вектор, содержащий минимальный элемент соответствующих строк матрицы:
For i:=1 to n do Begin
min:=a[i,1];
For j:=2 to m do
If a[i,j]<min then min:=a[i,j];
b[i]:=min;
End.
3.2. Множества.
3.2.1.Описание множеств.
Множество – это набор значений из некоторого скалярного (перечислимого) типа. Скалярные типы (Byte и Char) вводятся языком, они – перечислимые (все элементы можно поштучно назвать) и на их основе можно построить множество. Если же их станет мало, то всегда можно ввести свой скалярный тип, например:
Type VideoAdapterType = (MDA, CGA, EGA, VGA, Other, NoDetected);
и использовать переменную
Var VideoAdapter : VideoAdapterType;
которая может иметь только перечисленные в задании типа значения. Далее можно ввести переменную – множество из тех же значений.
В описании множества как типа используется конструкция Set of и следующее за ней указание базового типа. Способов задания множеств несколько:
Type
SetOfChar = Set Of Char; {множество символов}
SetOfByte = Set Of Byte; {множество чисел}
SetOfVideoAdapter = Set of VideoAdapterType;
{ множество из названий видеоадаптеров}
SetOfDigit = Set of 0 .. 9; {множество из цифр от 0 до 9}
SetOfDChar = Set of ‘0’ .. ‘9’; {множество из символов от ‘0’ до ‘9’}
SetOfVGA = Set Of CGA .. VGA;
{множество из названий видеоадаптеров}
Как видно из примеров, можно в задании типа «урезать» базовый тип, определяя диапазон его значений. В итоге множество может состоять только из элементов, вошедших в этот диапазон.
Разрешено описывать множество сразу в разделе переменных, но это возможно только в случае, если переменная-множество не является параметром процедуры или функции.
Var M1 : Set of …;
В Turbo Pascal’e разрешено определять множества, состоящие не более, чем из 256 элементов (столько же содержат типы Byte и Char). Каждый элемент множества имеет сопоставимый номер. Для типа Byte номер равен значению числа, для символов – определяется его ASCII-кодом. Всегда нумерация идет от 0 до 255, поэтому для множеств базовыми не являются типы ShortIn, LongInt, Word, Integer. Множества имеют весьма компактное машинное представление: на один элемент расходуется 1 бит. Поэтому для хранения 256 элементов множества понадобится всего 32 байта. Для меньшего диапазона значений понадобится еще меньше памяти.
Переменная, описанная как множество, подчиняется специальному синтаксису, элементы множества должны заключаться в квадратные скобки []:
Замечание: Порядок следования внутри скобок не имеет значения так же, как не имеет значение число повторений (элемент в множество включается только один раз).
Результатом будет множество, состоящее из элементов, которые содержатся в S1, и Х
S1:=[ ‘a ’.. ’z’ ];
X := [‘;’]
Include(S1, X);
{ [ ‘a’ ..’z’, ‘;’ ] }
Declude (S1, X)
Исключение элемента из множества
-
Результатом будет множество, состоящее из элементов, которые содержатся в S1, за исключением Х.
S1:=[ ‘a ’.. ’z’ ];
X := [‘a’]
Declude(S1, X);
{ [ ‘b’ ..’z’] }
Замечание: Операции пересечения и объединения множеств не зависят от мест операндов, но операция дополнения чувствительна к порядку следования операндов в выражении.
Результат вычислений S1-S2 не будет в общем случае равен результату S2-S1, точно также как и результат выражения S1-S2-S3 будет зависеть от порядка вычислений (слева направо и наоборот), устанавливаеимых компилятором. Обычно принято вычислять слева направо, но лучше не закладывать в программу явные особенности компилятора и вычислять «многоместные» разности через промежуточные переменные, избегая тем самым получение неправильных результатов.
Достоинства множеств очевидны:
· Гибкость представления наборов значений;
· Удобство их анализа и возможность накапливания однотипных значений или их выборок;
· Компактность кодировки.
Недостатки множеств – обратная сторона их достоинств. За компактность приходится платить невозможностью вывода их на экран (хотя содержимое множества можно посмотреть через отладчик); ввод множеств возможен только по элементам.
Пример:
{Ввод множества символов до нажатия точки или клавиши Enter}
Uses Crt; {для использования функции ReadKey}
Var SChar : Set Of Char;
Ch : Char;
Begin
SChar := []; { «обнуление значений»}
Repeat
Ch := ReadKey; {Ожидание нажатия клавиши}
If Ch = #0 Then {если управляющая клавиша, то пропускаем}
Else SChar := SChar + [Ch];
Until Ch in [‘.’, #13]; {ожидание нажатия клавиши ‘.’ или Enter}
SChar := SChar - [Ch]; {исключение последнего символа}
End.
{ Вывод элементов множества на экран }
Var SByte : Set of Byte;
X : Byte;
Begin
SByte := [23, 45, 67, 89, 123, 204, 213, 225];
{Возможно заполнение множества }
{ в режиме диалога с пользователем}
WriteLn(‘Содержимое множества Sbyte ’);
For X := 0 To 255
If X in SByte Then Write(X:4);
End.
3.2.3. Хранение множеств в памяти компьютера.
Несмотря на недостатки, множества – очень удобный инструмент для обработки данных и оптимальный для некоторых приложений способ хранения данных. Как уже говорилось п.2.1.1., каждому элементу множества соответствует бит, определяемый по номеру элемента исчисления.
S1:=[1,3,5] S2 := [3, 5, 7];
Вычитание множеств:
S:=S2-S1;
76543210
импликация
00101010
S =10000000 [7]
Объединение множеств:
S:=S1+S2;
76543210
or
10101000
S =10101010 [1,3,5,7]
Пересечение множеств:
S := S1*S2;
76543210
and
10101000
S = 00101000 [3,5]
Var Color:set of (Red, Blue, Green, Black);
{ 0 1 2 3 }
Color:=[Red,Green];
7 6 5 4 3 2 1 0
Black
Green
Blue
Red
4. Обработка символов и строк.
Язык Turbo Pascal дает возможность создавать программы с развитыми алгоритмами обработки символьной информации.
4.1. Символьный и строковый типы (Char и String).
Язык поддерживает стандартный символьный тип Char и динамические строки, описываемые типом String или String[n].
Значение типа Char – это непустой символ из алфавита компьютера, заключенный в одиночные кавычки. Кроме этой классической формы записи Turbo Pascal вводит еще два способа:
1. представление символа его кодом ASCII (American Standart Code for Interchange Information), для этого используется префикс #;
2. представление символа его клавиатурным обозначением (для управляющих символов с кодами в диапазоне от 0 до 31), для этого используется префикс ^;
Символ
Кодовое представление
Клавиатурное представление
Комментарий
‘a’
#97 = Chr (97)
-
Символ ‘а’
‘A’
#65 = Chr (65)
-
Символ ‘A’
‘ ‘
#32 = Chr (32)
-
Символ «пробел»
¬
#24 = Chr (27)
^[
Стрелка влево
#26 = Chr (24)
^X
Стрелка вверх
¨
# 4 = Chr (4)
^D
-
-
#7 = Chr (7)
^G
Звонок
-
#10 = Chr (10)
^J
Переход на следующую строку
-
#13 = Chr (13)
^M
Клавиша Enter
-
#0 = Chr (0)
-
Нулевой символ
Максимальная длина строки составляет 255 символов. Строки называются динамическими, поскольку они могут иметь различные длины в пределах объявленных границ. Тип String является базовым и совместим со всеми производными символьными типами. При попытке записать в строку длиннее, чем объявлено в описании, «лишняя часть» будет отсечена.
Тип String очень похож на массив символов Аrray [0..255] of char, но это не совсем так. В нулевом элементе строки хранится ее длина (динамическая «переменная»), которая автоматически меняется в зависимости от наполнения строки символами, чего не скажешь о символьном массиве.
Const n=10;
var a: String; { В такой строке максимум 255 символов }
b: String[n]; { В такой строке максимум 10 символов }
c: String[255]; { то же, что и String }
Значением строки может быть любая последовательность символов, заключенная в одинарные кавычки:
{«Звонок» сообщение «переход на следующую строку» сообщение «переход на следующую строку» «клавиша Enter»}
В такой записи не должно быть пробелов вне кавычек. Более общим способом включения в строку любых символов является их запись по ASCII-коду через префикс # или функцию Chr. Механизм показан ниже:
#179‘ Номер п/п ’#179’ Ф.И.О. ’ +Chr(179)+’ Должность ’#179
{то же, что и ‘| Номер п/п | Ф.И.О. | Должность |’}
#7#32#179#32#32#179 {то же, что и ^G’ | |’}
Строки различных длин совместимы между собой в операторах присваивания и сравнения, но «капризно» ведут себя при передаче параметров в процедуры и функции (если тип фактического параметра является производным от строкового, то при вызове он должен совпадать с типом формального параметра (принципы передачи параметров в подпрограммы будут обсуждаться в следующих параграфах)). Поэтому для полной совместимости типов параметры, описываемые на уровне подпрограммы, должны быть описаны исключительно типом String и компилировать программу необходимо в режиме {$V-} (режим проверки совместимости формальных и фактических параметров).
К любому символу в строке можно обратиться по его номеру, как к элементу массива, отдельный символ совместим по типу со значением типа Char, поэтому можно выполнять различные присваивания как на уровне символов строки, так и на уровне произвольных символов.
Пример:
Var Ch : Char; I : Byte; St : String[10];
Begin
St := ‘Example ’; {длина 8 символов}
For i := 1 to 4 Do Write (St[i]); {‘Exam’}
Ch:=’1’;
St := St + Ch; {‘Example 1’, длина 9 символов}
St[9]:=’2’; Write(St); {St = ‘ Example 2’}
St[10]:=Ch; Write(St); {St = ‘ Example 21’}
End.
Как уже говорилось выше, каждая строка «знает», сколько символов в ней содержится в текущий момент времени. Символ St[0] содержит код, равный числу символов в строке St, т.е. длина строки всегда равна Ord(St[0]). Об этой особенности необходимо помнить при заполнении строки одинаковыми символами. Проблему заполнения решает встроенная процедура FillChar :
St[0] := Chr(50); { устанавливаем заданную длину строки }
End.
FillChar(St, SizeOf(St), 0); { Обнуление строки }
Замечание: Не рекомендуется принудительно изменять длину строки, т.е. символ St[0], за исключением рассмотренной ситуации.
В рассмотренной ситуации принудительное установление длины строки необходимо, так как сама процедура FillChar не устанавливает заданную длину. При работе с указанной процедурой всегда есть риск «выйти» за пределы, отводимые заданной строке, и заполнить символом рабочую область памяти. Так как компилятор эту ситуацию не контролирует, то вся ответственность ложится на программиста.
4.2. Операции над символами.
Символы можно лишь присваивать друг другу и сравнивать между собой. Сравнение осуществляется на уровне ASCII-кодов (так как в памяти по существу хранятся не сами символы, а их кодовое обозначение). Символы равны, если равны их ASCII-коды, один символ больше другого, если его код имеет большее значение
1). Присваивание.
<Переменная> := <Значение>; a := ‘a’;
2). Сравнение (проводится традиционным способом по правилам лексико-графического упорядочивания (как в словаре)).
>, <, <>, =, >=, <=
‘а’ > ‘A’ – True {код 97 > кода 65}
‘a’ <> ‘A’ – True { код 97 <> коду 65}
3). Прочие.
Функция : тип
Назначение
Примеры
CHR(x: byte): char;
Возвращает символ ASCII кода, соответствующий переменной X
CHR(32) = ‘ ‘;
CHR(ORD(‘ ‘)) = ‘ ‘;
ORD(ch: char): byte;
Возвращает код из ASCII по символу Ch
ORD(‘ ‘) = 32;
ORD(CHR(32)) = 32;
PRED(ch: char): char;
Возвращает предыдущий символ для Ch из ASCII-таблицы.
PRED(‘c’) = ‘b’;
SUCC(ch: char): char;
Возвращает следующий символ из ASCII-таблицы..
PRED(‘c’) = ‘b’;
UpCase(ch: char): char;
Переводит символ Сh в верхний регистр. Действует только для латинских букв, все остальные символы, в том числе и кириллицу, возвращает в исходном виде.
Внимание !!! Следующие значения функций не определены:
PRED(#0); SUCC(#255);
4.3. Операции над строками.
Строки можно присваивать, сливать и сравнивать.
1). Ввод/Вывод строк осуществляется с помощью стандартных операторов ввода/вывода:
ReadLn(S); { ввод строки (максимальное число введенных символов 128 – определяется буфером клавиатуры (128 байт)) }
Write(S); { вывод строки (курсор остается в текущем положении) }
WriteLn(S); { вывод строки (курсор переводится в начало следующей стоки) }
Сравнение строк происходит посимвольно, начиная с первого символа в строке. Строки равны, если они равны по длине и посимвольно эквивалентны:
2). Присваивание строки.
S1 := S2;
a := ‘a’;
Empty := ‘’;
3). Сравнение строк ( если при посимвольном сравнении окажется, что один символ (его код) больше другого, то строка, его содержащая, тоже окажется большей, остаток строк при этом будет игнорироваться и длины строк уже не играют роли)
‘abcd’ = ‘abcd’ { True }
‘abcd’ = ‘ABCD’ { False, так как #65 <> #97 ‘a’ <>’A’ }
‘ abcd’ < ‘abcd’ { True, так как #32 < #65 = ‘a’ }
‘Яковлев’ > ‘Я’ { True, так как длина первой строки больше }
‘ ' <> ‘’ { True, так как #32 > ‘’ }
‘__’ = ‘_’ { False, так как длина первой строки больше }
‘__’ > ‘_’ { True, так как длина первой строки больше }
‘’ = ‘’ { True, так как обе строки пусты}
4.4. Процедуры и функции обработки строк.
Процедуры и функции
Назначение
Пример использования
Редактирование строк
Length(S: String): byte;
Функция определяет текущую длину строки.
l := Length(S);
{ S := ‘Дом’; l = 3 }
l1 := Length(‘Дом’);
{ l1 = 3 }
l2 := Length(S + ‘Дом’);
{ l2 = 6 }
Concat(S1,S2,S3, ... : String): String;
Функция проводит конкатенацию (слияние) строк. Если суммарная длина больше, чем 255 символов, то лишнее будет «обрезано».
S1 := ‘Ура! ‘; S2 := ‘6 ‘;
S3 := ‘факультету!’;
S := Concat(S1, S2, S3);
{ S = ‘Ура! 6 факультету!’ }
S := S1 + S2 + S3;
{ делает то же, что и Concat}
Copy(S: String; Start,
Len: byte): String;
Функция возвращает подстроку из строки S, начиная с позиции Start и длиною Len. Если позиция находится за пределами строки, то возвращается пустая строка. Если же начальная позиция + длина больше длины строки, то копируется все до конца строки.
Процедура удаляет из строки S подстроку с позиции Start длиной Len. Замечание: изменяет длину строки.
Если Startбольше длины строки, то строка остается без изменений. Если Start+Len больше длины строки, то удаляется подстрока с позиции Start до конца строки.
S := ‘6 факультет’;
Delete(S,2,2);
{ S = ‘6 культет’ }
Delete(S,100,3);
{ S := ‘6 факультет’ }
Delete(S,3,100);
{ S = ‘6 ’ }
Delete(‘Попробуй удали!’,3,8);
{ Ошибка! S не может быть константой }
Insert(SubS: String;
Var S: String; Start: byte);
Процедура вставляет под-строку SubS в строку S, начиная с позиции Start. Замечание: изменяет длину строки.
Если новая длина больше 255, то лишнее будет «обрезано».. Если позиция Start выходит за длину строки, то вставка будет происходить в позицию за истинной длиной строки. Если строка ограничена, то вставка будет происходить в пределах заданной длины.
S := ‘Начало - - Конец’;
SubS := ‘ Середина’;
Insert(SubS, S, 9);
{ S = ‘Начало - Середина - Конец’ }
S := ‘123’
Insert(‘abc’, S, 100);
{ S = ‘123abc’ }
Pos(SubS, S: String): byte;
Функция возвращает позицию первого вхождения подстроки SubS в строку S. Если в строке такой подстроки нет, то выдается 0.
S := ‘abc1244 a15 bc’;
Mask := ‘15’;
P := Pos(Mask,S);
{ P = 10 }
P: = Pos(‘dab’,S);
{ P = 0 }
Процедура преобразовы-вает число x в строку S. F –число символов, b –чисел после точки.
Str(3.1415:7:2, S);
{ S = ‘_ _ _ 3.14’ }
Str(P:7,S);
{ P: Word = 4433;
S = ‘_ _ _ 4433’ }
Val(S: String; var x;
Var ErrCode: Integer);
Преобразовывает строку Sв число x соответствующе-го типа. ErrCode = 0, если преобразование прошло успешно, либо это позиция первого неверного символа при преобразовании.
Write(‘Введите число: ‘);
ReadLn(S); { S: String }
val (S, x, ErrCode);
{ x: Word }
if ErrCode = 0 then
Else WriteLn(‘Ошибка! Повторите ввод.’);
4.5. Базовые алгоритмы обработки строк.
Описательная часть: Var St : String;
1). Убрать все пробелы в начале строки:
While S[1]=’ ‘ do Delete(St,1,1);
2). Убрать все пробелы в конце строки:
While St [Length(St)] =’ ‘ do Delete(St, Length(St),1);
{или}
While Copy(St, Length(St),1)=’ ‘ do Delete(St, Length(St),1);
3). Убрать все пробелы из строки:
While Pos(‘ ‘,St)>0 do Delete(St, Pos(‘ ‘,St), 1);
4). Убрать “лишние” пробелы между словами в строке:
While Pos(‘ ‘,S) > 0 do Delete(S, Pos(‘ ’,S),1);
5). Ввод чисел с контролем :
Var S:String;
R: Real; Err : Integer;
begin
. . .
repeat
Write(‘Введи число: ‘); ReadLn(S);
Val(S, R, Err);
until Err=0;
. . .
end.
6). Ввод строк с контролем допустимых символов:
S:=’’;
repeat
repeat
Ch := ReadKey;
if Ch in [‘0’..’9’,’.’,’-‘] then S := S + Ch;
until Ch=#13;
Val(S, R, Err);
until Err=0;
7). Вывод чисел на экран в графическом режиме.
X:= -37.5;
Str(X,S); {Преобразуем в строку}
OutText(S);
8). Сортировка массива строк (строки сортируются по тем же алгоритмам, что и массивы чисел).
for k:=1 to n-1 do
for i:=1 to n-k do
if a[i]>a[i+1] then begin
S := a[i]; a[i]:=a[i+1]; a[i+1]:=S;
end; {пузырек}
Список рекомендуемой литературы.
Поляков Д.Б., Круглов И.Ю. Программирование в среде Турбо Паскаль. Версия 5.5. М.: Издательство МАИ, А/О «Розвузнаука», 1992.
Фаронов В.В. Турбо Паскаль. Версия 7.0. Начальный курс. Учебное пособие. М.: Издательство Нолидж, 1997.
Епанишников А.М., Епанишников В.А. Программирование в среде Турбо Паскаль 7.0. М.: Диалог-МИФИ, 1995.
Йенсен К., Вирт Н. Паскаль. Руководство для пользователя. М.: Финансы и статистика, 1989.
Керниган Б., Плоджер Ф. Инструментальные средства программирования на языке ПАСКАЛЬ. М.: Радио и связь, 1985.








 For i:= i+5 to n do ;
For i:= i+5 to n do ; For i:= 1 to n do i := i+5;
For i:= 1 to n do i := i+5;


 Var a: array [1..10] of Real;
Var a: array [1..10] of Real;