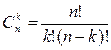Задача кодирования информации представляется как некоторое преобразование числовых данных в заданной системе счисления. В частном случае эта операция может быть сведена к группированию символов (представление в виде триад или тетрад) или представлению в виде символов (цифр) позиционной системы счисления. Так как любая позиционная система не несет в себе избыточности информации и все кодовые комбинации являются разрешенными, использовать такие системы для контроля не представляется возможным.
Систематический код - код, содержащий в себе кроме информационных контрольные разряды.
В контрольные разряды записывается некоторая информация об исходном числе. Поэтому можно говорить, что систематический код обладает избыточностью. При этом абсолютная избыточность будет выражаться количеством контрольных разрядов k, а относительная избыточность - отношением k/n , где n = m + k - общее количество разрядов в кодовом слове (m - количество информационных разрядов).
Понятие корректирующей способности кода обычно связывают с возможностью обнаружения и исправления ошибки. Количественно корректирующая способность кода определяется вероятностью обнаружения или исправления ошибки. Если имеем n-разрядный код и вероятность искажения одного символа p, то вероятность того, что искажены k символов, а остальные n - k символов не искажены, по теореме умножения вероятностей будет
w = pk(1–p)n-k
Число кодовых комбинаций, каждая из которых содержит k искаженных элементов, равна числу сочетаний из n по k:
Тогда полная вероятность искажения информации
Так как на практике p = 10-3 ...10-4, наибольший вес в сумме вероятностей имеет вероятность искажения одного символа. Следовательно, основное внимание нужно обратить на обнаружение и исправление одиночной ошибки.
Корректирующая способность кода связана также с понятием кодового расстояния.
Кодовое расстояние d(A, В) для кодовых комбинаций А и В определяется как вес третьей кодовой комбинации, которая получается поразрядным сложением исходных комбинаций по модулю 2.
Вес кодовой комбинации V(A) - количество единиц, содержащихся в кодовой комбинации.
Рис. 3. Геометрическое Рис. 4 Кодовые расстояния
представление кодов
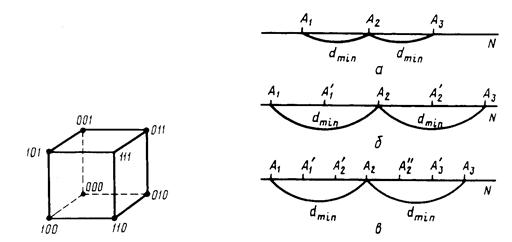
Коды можно рассматривать и как некоторые геометрические (пространственные) фигуры. Например, триаду можно представить в виде единичного куба, имеющего координаты вершин, которые отвечают двоичным символам (рис. 3.3). В этом случае кодовое расстояние воспринимается как сумма длин ребер между соответствующими вершинами куба (принято, что длина одного ребра равна 1). Оказывается, что любая позиционная система отличается тем свойством, что минимальное кодовое расстояние равно 1 (рис. 3.4, а).
В теории кодирования показано, что систематический код способен обнаружить ошибки только тогда, когда минимальное кодовое расстояние для него больше или равно 2t, т. е.
dmin³2t,
где t - кратность обнаруживаемых ошибок (в случае одиночных ошибок t = 1 и т. д.).
Это означает, что между соседними разрешенными кодовыми словами должно существовать по крайней мере одно кодовое слово (рис. 3.4, б, в).
В тех случаях, когда необходимо не только обнаружить ошибку, но и исправить ее (т. е. указать место ошибки), минимальное кодовое расстояние должно быть
dmin³2t+1,
Существуют коды, в которых невозможно выделить абсолютную избыточность. Пример таких кодов - Д-коды, где количество разрешенных комбинаций меньше количества возможных комбинаций. Неявная избыточность характерна также для кодов типа «k из n». Примером является код «2 из 5», который часто используется для представления информации. Суть его в том, что в слове из пяти разрядов только два разряда имеют единичное значение.