Метод используется в случае, когда функция задана аналитически (в виде формулы). График функции вписывают в прямоугольник (см. рис. 24.4). На ось Y подают случайное равномерно распределенное число из ГСЧ. На ось X подают случайное равномерно распределенное число из ГСЧ. Если точка в пересечении этих двух координат лежит ниже кривой плотности вероятности, то событие X произошло, иначе нет.
Недостатком метода является то, что те точки, которые оказались выше кривой распределения плотности вероятности, отбрасываются как ненужные, и время, затраченное на их вычисление, оказывается напрасным. Метод применим только для аналитических функций плотности вероятности.
Рис. 24.4. Иллюстрация метода усечения
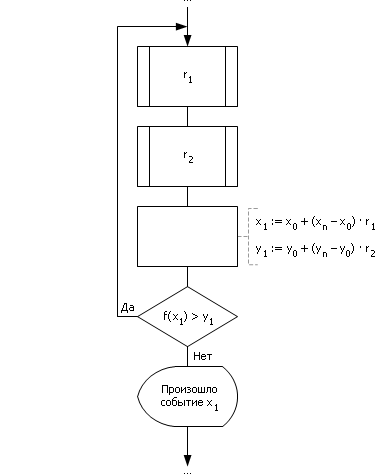
На рис. 24.5 показан алгоритм, реализующий метод усечения. В цикле генерируется два случайных числа из диапазона от 0 до 1. Числа масштабируются в шкалу X и Y и проверяется попадание точки со сгенерированными координатами под график заданной функции Y = f(X). Если точка находится под графиком функции, то событие X произошло с вероятностью Y, иначе точка отбрасывается.
Рис. 24.5. Блок-схема алгоритма, реализующего метод усечения
Допустим, что нам задан интегральный закон распределения вероятности F(x), где f(x) — функция плотности вероятности и
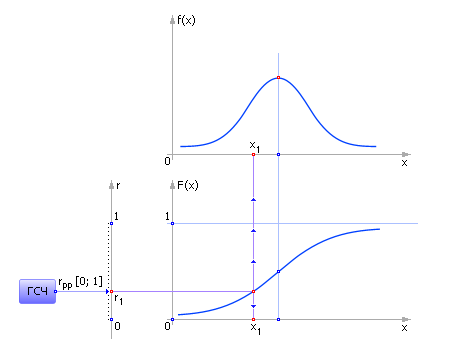
Тогда достаточно разыграть случайное число, равномерно распределенное в интервале от 0 до 1. Поскольку функция F тоже изменяется в данном интервале, то случайное событие x можно определить взятием обратной функции по графику или аналитически: x = F–1(r). Здесь r — число, генерируемое эталонным ГСЧ в интервале от 0 до 1, x1 — сгенерированная в итоге случайная величина. Графически суть метода изображена на рис. 24.6.
Рис. 24.6. Иллюстрация метода обратной функции для генерации случайных событий x, значения которых распределены непрерывно. На рисунке показаны графики плотности вероятности и интегральной плотности вероятности от х
Данным методом особенно удобно пользоваться в случае, когда интегральный закон распределения вероятности задан аналитически и возможно аналитическое взятие обратной функции от него, как это и показано на следующем примере.
Пример 1. Примем к рассмотрению экспоненциальный закон распределения вероятности случайных событий f(x) = λ · e–λx. Тогда интегральный закон распределения плотности вероятности имеет вид: F(x) = 1 – e–λx.
Так как r и F в данном методе предполагаются аналогичными и расположены в одном интервале, то, заменяя F на случайное число r, имеем: r = 1 – e–λx.
Выражая искомую величину x из этого выражения (то есть, обращая функцию exp()), получаем: x = –1/λ · ln(1 – r).
Так как в статическом смысле (1 – r) и r — это одно и тоже, то x = –1/λ · ln(r).
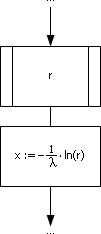
На рис. 24.7 показан фрагмент алгоритма, реализующего метод обратной функции для экспоненциального закона.
Рис. 24.7. Фрагмент блок-схемы алгоритма, реализующей метод обратной функции для экспоненциального закона
Нормальный закон распределения встречается в природе весьма часто, поэтому для него разработаны отдельные эффективные методы моделирования. Формула распределения вероятности значений случайной величины x по нормальному закону имеет вид:
Как видно, нормальное распределение имеет два параметра: математическое ожидание mx и среднеквадратичное отклонение σx величины x от этого математического ожидания.
x — случайная величина;
y(x) — вероятность принятия случайной величиной значения x;
mx — математическое ожидание;
σx — среднее квадратичное отклонение.
Нормализованным нормальным распределением называется такое нормальное распределение, у которого mx = 0 и σx = 1. Из нормализованного распределения можно получить любое другое нормальное распределение с заданными mx и σx по формуле: z = mx + x · σx.
Рассматривая последнюю формулу, вспомните формулы компьютерной графики: операция масштабирования выражается в математической модели через умножение (это соответствует изменению разброса величины, растягиванию геометрического образа), операция смещения выражается через сложение (это соответствует изменению значения наиболее вероятной величины, смещению геометрического образа).
Функция нормального распределения имеет вид колокола. На рис. 25.1 показано нормализованное нормальное распределение.
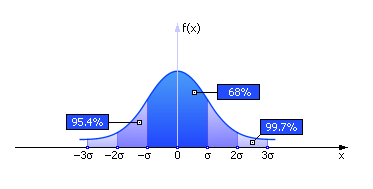
Рис. 25.1. Графический вид нормального закона распределения случайной величины х с параметрами mx = 0 и σx = 1 (распределение нормализовано)
График на рис. 25.1 показывает, что в области –σ < x < σ на графике сосредоточено 68% площади распределения, в области –2σ < x < 2σ на графике сосредоточено 95.4% площади распределения, в области –3σ < x < 3σ на графике сосредоточено 99.7% площади распределения («правило трех сигм»). Вспомните, пожалуйста, рис. 2.7 из лекции 02.
Пример. По нормальному распределению распределен рост людей, находящихся одновременно в большой аудитории. А именно: достаточно мало людей очень большого роста, и столь же мала вероятность встретить людей очень малого роста. В основном, легче встретить людей среднего роста — и вероятность этого велика.
Например, средний рост людей составляет, в основном, 170 см, то есть mx = 170. Известно также, что σx = 20. На рис. 25.1 показано, что доля людей с ростом от 150 до 190 (170 – 20 < 170 < 170 + 20) составляет в обществе 68%. Доля людей от 130 см до 210 см (170 – 2 · 20 < 170 < 170 + 2 · 20) составляет в обществе 95.4%. Доля людей от 110 см до 230 (170 – 3 · 20 < 170 < 170 + 3 · 20) составляет в обществе 99.7%. Например, вероятность того, что человек окажется ростом меньше 110 см или больше 230 см составляет всего 3 человека на 1000.