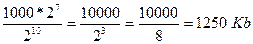Чтобы хранить также и коды национальных символов каждой страны (в нашем случае – символов кириллицы) требуется добавить еще 1 бит, что увеличит количество уникальных комбинаций из нулей и единиц вдвое, т.е. в нашем распоряжении дополнительно появится 128 свободных кодов (со 128-го по 255-й), в соответствие которым можно поставить символы русского алфавита.
Таким образом, отведя под хранение информации о коде каждого символа 8 бит, мы получим N=28=256 уникальных двоичных кодов, что достаточно, чтобы закодировать все символы, которые можно ввести с клавиатуры.
Одно время в СССР была принята кодировка КОИ-7, которая могла закодировать в своих семи разрядах … Правильно, 128 символов. Оказалась она неудобна и уступила свое место уже в современной России кодировке КОИ-8. кто был в Интернете, тот знает.
Так мы подошли к необходимости познакомиться с еще одной базовой единицей измерения – байтом.
Байт - последовательность из 8 бит.
1 байт = 23 бит = 8 бит.
На основании одного байта можно получить 28=256 уникальных двоичных кодов.
В современных кодировочных таблицах под хранение информации о коде каждого символа отводится 1 байт.
1 символ = 1 байт.
В байтах измеряется объем данных (V) при их хранении и передаче по каналам связи. Например, текст “Добрый день!” занимает объем равный 12 байтам.
Биты в байте нумеруются с конца с 0-го по 7-й. Минимальная комбинация на основании одного байта – восемь нулей, максимальная – восемь единиц. Рис. 10а.
При хранении на физическом уровне каждый байт может быть реализован, например, на базе восьми конденсаторов, каждый из которых либо разряжен (0), либо заряжен (1). Рис. 10b.
Рис. 10а. Байт: минимальная и максимальная комбинации
Рис. 10b. Байт: соответствие двоичного числа и электрического импульса.
Возвращаясь к кодировочным таблицам, заметим, что на сегодняшний день в использовании не одна, а несколько кодировочных таблиц, включающих коды кириллицы, – это стандарты, выработанные в разные годы и различными учреждениями. В этих таблицах различен порядок, в котором расположены друг за другом символы кирилличного алфавита, поэтому одному и тому же коду соответствуют разные символы. По этой причине, мы иногда сталкиваемся с текстами, которые состоят из русских букв, но в бессмысленной для нас последовательности.
Например, текст “Компьютерные вирусы”, введенный в кодировке Windows-1251 в кодировке КОИ-8 будет отображен так: ”лПНРШАФЕТОШЕ ЧЙТХУЩ”.
Несоответствие кодов символов в различных кодировках кириллицы.
Код
Windows-1251
КОИ-8
ISO
Под национальные кодировки отданы коды с 128-го по 255-й.
А
ю
Р
Б
а
С
В
б
Т
Эта проблема разрешима - на каждом компьютере найдутся все основные кодировочные таблицы, и если тест выглядит неадекватно, нужно попробовать перекодировать его, просто указав использовать другую кодировочную таблицу. Но наличие такой проблемы, конечно, вносит неудобства.
Используя 8-битную кодировочную таблицу мы не сможем адекватно увидеть на мониторе и тексты, созданные на тех языках, где используются символы, отличные от латинских и кирилличных, например символы с умляутами в немецком языке.
Теоретически давно существует решение этих проблем. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=216=65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Cyrillic (#0400 — #04FF)
Cyrillic Supplement (#0500 — #052F).
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
Поэтому сейчас на практике больше распространено представление Юникода UTF-8 (Unicode Transformation Format). UTF-8 обеспечивает наилучшую совместимость с системами, использующими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байтов. В целом, так как самые распространенные в мире символы – символы латинского алфавита - в UTF-8 по-прежнему занимают 1 байт, такое кодирование экономичнее, чем чистый Юникод.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
8000 бит;
7000 бит;
5000 бит;(правильно)
1000 бит.
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5(правильно), 3, 1.
Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения).
Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации.
Память носителей в свою очередь имеет ограниченную ёмкость, т.е. способность вместить в себе определенный объем. Ёмкость памяти электронных носителей информации, естественно, также измеряется в байтах.
Начнем с начала. Самая маленькая единица информации: 1 бит – один нолик или одна единичка. Бит (BIT) есть не что иное как аббревиатура от BInary digiT (двоичная цифра), придуманная в 1946 году выдающимся американским ученым-статистиком Джоном Тьюки. Он был советником пяти президентов США. Тьюки избрал бит для обозначения одного двоичного разряда, способного принимать значение 0 или 1.
А вот с привычным байтом не все так просто. Если быть точным, то байтом (BYTE – это сокращенное от BinarY TErm, двоичный элемент) надлежит называть последовательность длиной от 8 до 10 битов! А для обычного восьмибитного байта есть специальный термин октет (Octet). Есть еще экзотическая коротышка – четырехбитный ниббл (Nibble).
Тем не менее, мы будем называть байтом восьмибитовую последовательность символов, а мы знаем, что именно одним байтом кодируется один символ таблицы ASCII-кодов. Вот это важно:
а дальше…
Именование
Обозначение
Значение в байтах
килобайт
1 Кb
210 b
1 024 b
мегабайт
1 Mb
220 b
1 048 576 b
гигабайт
1 Gb
230 b
1 073 741 824 b
терабайт
1 Tb
240 b
1 099 511 627 776 b
петабайт
250 b
1 125 899 906 842 624
экзабайт
260 b
1 152 921 504 606 846 976
зеттабайт
270 b
1 180 591 620 717 411 303 424
йоттабайт
280 b
1 208 925 819 614 629 174 706 176
Этимология приставок не лишена интереса. Все началось в 1798 году, после Великой французской революции, с переходом на метрическую систему. Тогда появились первые приставки «кило» (kilo, k, 103) и «мега» (mega, m, 106), и их вполне хватало. В ХХ веке, после Второй мировой войны, этот ряд приставок был продолжен, и появились две следующие: «гига» (giga, G) и «тера» (tera, T) – соответственно для 109 и 1012, т.е. миллиард и триллион. В 1975 году Генеральная конференция мер и весов обогатила мир еще двумя приставками: «пета» (peta, P, 1015) и «экза» (exa, E, 1018), т.е. квадриллион и квинтиллион. На этом процесс приставок не остановился. В последнем издании Британской энциклопедии призваны права гражданства за «зетта» (zetta, Z, 1021) и «йотта» (yotta, Y, 1024), т.е. секстиллион и септиллион. Названия «зетта» и «йотта» образованы от последней и предпоследней букв латинского алфавита.
Чтобы физически представить себе, а сколько это – 1 килобайт, представим себе заполненную текстом страницу формата А4. Набрана она стандартным шрифтом размера 12 без всяких прикрас. В среднем на такой странице помещается 60 строк по 80 символов в каждой. Соответственно, символов на странице 60*80=4800, а значит и столько же байтов, поделим приблизительно на 1000, чтобы получить килобайты – 4,8, т.е. приблизительно 5 килобайтов.
В связи, с тем, что единицы измерения объема и ёмкости носителей информации кратны 2 и не кратны 10, большинство задач по этой теме проще решается тогда, когда фигурирующие в них значения представляются степенями числа 2. Рассмотрим пример подобной задачи и ее решение:
В текстовом файле хранится текст объемом в 400 страниц. Каждая страница содержит 3200 символов. Если используется кодировка KOI-8 (8 бит на один символ), то размер файла составит:
- 1 Mb;
- 1,28 Mb;
- 1280 Kb;
- 1250 Kb.
Решение
1) Определяем общее количество символов в текстовом файле. При этом мы представляем числа, кратные степени числа 2 в виде степени числа 2, т.е. вместо 4, записываем 22 и т.п. Для определения степени можно использовать Таблицу 7.
символов.
2) По условию задачи 1 символ занимает 8 бит, т.е. 1 байт => файл занимает 27*10000 байт.
Сколько бит в сообщении объемом четверть килобайта? Варианты: 250, 512, 2000, 2048(правильно).
Объем текстового файла 640 Kb. Файл содержит книгу, которая набрана в среднем по 32 строки на странице и по 64 символа в строке. Сколько страниц в книге: 160, 320(правильно), 540, 640, 1280?
Досье на сотрудников занимают 8 Mb. Каждое из них содержит 16 страниц (32 строки по 64 символа в строке). Сколько сотрудников в организации: 256(правильно); 512; 1024; 2048?
Графическая информация, как и информация любого другого типа, хранятся в памяти компьютера в виде двоичных кодов. Изображение, состоящее из отдельных точек, каждая из которых имеет свой цвет, называется растровым изображением. Минимальный элемент такого изображения в полиграфии называется растр, а при отображении графики на мониторе минимальный элемент изображения называют пиксель (pix).
Пиксель
Растр
Рис. 11. Минимальная единица изображения: пиксель и растр.
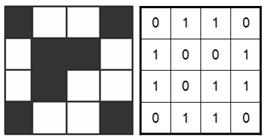
Если пиксель изображения может быть раскрашен только в один из 2х цветов, допустим, либо в черный (0), либо в белый (1), то для хранения информации о цвете пикселя достаточно 1 бита памяти (log2(2)=1 бит). Соответственно, объем, занимаемый в памяти компьютера всем изображением, будет равен числу пикселей в этом изображении (рис. 20а).
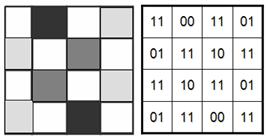
Если под хранение информации о цвете пикселя выделить 2 бита, то число цветов, допустимых для раскраски каждого пикселя, увеличится до 4х (N=22=4), а объем файла изображения в битах будет вдвое больше, чем количество составляющих его пикселей (рис. 20b).
Рис. 12a. 1 бит на пиксель – 2 цвета.
Рис. 12b. 2 бита на пиксель – 4 цвета.
При печати на не цветном принтере обычно допускает 256 градаций серого цвета (от черного (0) до белого (255)) для раскраски каждой точки изображения. Под хранение информации о цвете точки в этом случае отводится 1 байт, т.е. 8 бит (log2(256)=8 бит).



 Теоретически давно существует решение этих проблем. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=216=65 536 символов.
Теоретически давно существует решение этих проблем. Оно называется Unicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодировано N=216=65 536 символов.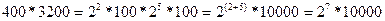 символов.
символов.