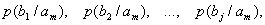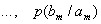Важным понятием при работе с информацией является классификация объектов.
Классификация — система распределения объектов (предметов, явлений, процессов, понятий) по классам в соответствии с определенным признаком.
Под объектом понимается любой предмет, процесс, явление материального или нематериального свойства. Система классификации позволяет сгруппировать объекты и выделить определенные классы, которые будут характеризоваться рядом общих свойств. Классификация объектов — это процедура группировки на качественном уровне, направленная на выделение однородных свойств. Применительно к информации как к объекту классификации выделенные классы называют информационными объектами.
Пример. Всю информацию об университете можно классифицировать по многочисленным информационным объектам, которые будут характеризоваться общими свойствами:
· информация о студентах — в виде информационного объекта "Студент";
· информация о преподавателях — в виде информационного объекта "Преподаватель";
· информация о факультетах — в виде информационного объекта "Факультет" и т.п.
Свойства информационного объекта определяются информационными параметрами, называемыми реквизитами. Реквизиты представляются либо числовыми данными, например вес, стоимость, год, либо признаками, например цвет, марка машины, фамилия.
Пример. Информация о каждом студенте в отделе кадров университета систематизирована и представлена посредством одинаковых реквизитов:
· фамилия, имя, отчество;
· пол;
· год рождения;
· месторождения;
· адрес проживания;
· факультет, где проходит обучение студент, и т.д.
Все перечисленные реквизиты характеризуют свойства информационного объекта "Студент".
Кроме выявления общих свойств информационного объекта классификация нужна для разработки правил (алгоритмов) и процедур обработки информации, представленной совокупностью реквизитов.
При любой классификации желательно, чтобы соблюдались следующие требования:
· полнота охвата объектов рассматриваемой области;
· однозначность реквизитов;
· возможность включения новых объектов.
В любой стране разработаны и применяются государственные, отраслевые, региональные классификаторы. Например, классифицированы: отрасли промышленности, оборудование, профессии, единицы измерения, статьи затрат и т.д.
Классификатор — систематизированный свод наименований и кодов классификационных группировок.
При классификации широко используются понятия классификационный признак и значение классификационного признака, которые позволяют установить сходство или различие объектов. Возможен подход к классификации с объединением этих двух понятий в одно, названное как признак классификации. Признак классификации имеет также синоним основание деления.
Пример. В качестве признака классификации выбирается возраст, который состоит из трех значений: до 20 лет, от 20 до 30 лет, свыше 30 лет. Можно в качестве признаков классификации использовать: возраст до 20 лет, возраст от 20 до 30 лет, возраст свыше 30 лет.
Иерархическая система классификации строится следующим образом:
· исходное множество элементов составляет 0-й уровень и делится в зависимости от выбранного классификационного признака на классы (группировки), которые образуют 1-й уровень;
· каждый класс 1-го уровня в соответствии со своим, характерным для него классификационным признаком делится на подклассы, которые образуют 2-й уровень;
· каждый класс 2-го уровня аналогично делится на группы, которые образуют 3-й уровень, и т.д.
Учитывая достаточно жесткую процедуру построения структуры классификации, необходимо перед началом работы определить ее цель, т.е. какими свойствами должны обладать объединяемые в классы объекты. Эти свойства принимаются в дальнейшем за признаки классификации.
Запомните! В иерархической системе классификации из-за жесткой структуры особое внимание следует уделить выбору классификационных признаков.
В иерархической системе классификации каждый объект на любом уровне должен быть отнесен к одному классу, который характеризуется конкретным значением выбранного классификационного признака. Для последующей группировки в каждом новом классе необходимо задать свои классификационные признаки и их значения. Таким образом, выбор классификационных признаков будет зависеть от семантического содержания того класса, для которого необходима группировка на последующем уровне иерархии.
Количество уровней классификации; соответствующее числу признаков, выбранных в качестве основания деления, характеризует глубину классификации.
Достоинства иерархической системы классификации:
· простота построения;
· использование независимых классификационных признаков в различных ветвях иерархической структуры.
Недостатки иерархической системы классификации:
· жесткая структура, которая приводит к сложности внесения изменений, так как приходится перераспределять все классификационные группировки;
· невозможность группировать объекты по заранее не предусмотренным сочетаниям признаков.
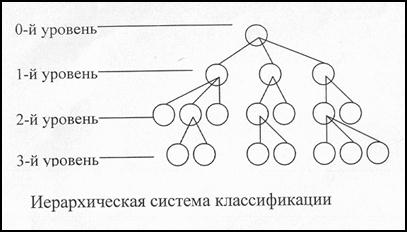
Пример. Поставлена задача — создать иерархическую систему классификации для информационного объекта "Факультет", которая позволит классифицировать ин формацию обо всех студентах по следующим классификационным признакам: факультет, на котором он учится, возрастной состав студентов, пол студента.
Система классификации представлена на рис.2.4 и будет иметь следующие уровни: 0-й уровень. Информационный объект "Факультет";
1-й уровень. Выбирается классификационный признак — название факультета, что позволяет выделить несколько классов с разными названиями факультетов, в которых хранится информация обо всех студентах.
2-й уровень. Выбирается классификационный признак — возраст, который имеет три градации: до 20 лет, от 20 до 30 лет, свыше 30 лет. По каждому факультету выделяются три возрастных подкласса студентов.
3-й уровень. Выбирается классификационный признак — пол. Каждый подкласс 2-го уровня разбивается на две группы. Таким образом, информация о студентах каждого факультета в каждом возрастном подклассе разделяется на две группы — мужчин и женщин.
Созданная иерархическая система классификации имеет глубину классификации, равную трем.
Фасетная система классификации в отличие от иерархической позволяет выбирать признаки классификации независимо как друг от друга, так и от семантического содержания классифицируемого объекта. Признаки классификации называются фасетами (facet — рамка). Каждый фасет (Фi) содержит совокупность однородных значений данного классификационного признака. Причем значения в фасете могут располагаться в произвольном порядке, хотя предпочтительнее их упорядочение.
Пример. Фасет цвет содержит значения: красный, белый, зеленый, черный,
желтый.
Фасет специальность содержит названия специальностей.
Фасет образование содержит значения: среднее, среднее специальное, высшее.
Схема построения фасетной системы классификации в виде таблицы отображена на рисунке. Названия столбцов соответствуют выделенным классификационным признакам (фасетам), обозначенным Ф1, Ф2, ..., Фi,…,Фn. Например, цвет, размер одежды, вес и т.д.
Произведена нумерация строк таблицы. В каждой клетке таблицы хранится конкретное значение фасета. Например, фасет цвет, обозначенный Ф1, содержит значения: красный, белый, зеленый, черный, желтый.
Процедура классификации состоит в присвоении каждому объекту соответствующих значений из фасетов. При этом могут быть использованы не все фасеты. Для каждого объекта задается конкретная группировка фасетов структурной формулой, в которой отражается их порядок следования:
Кs = (Ф1,Ф2,...,Фi,...,Фn),
где Фi|— i-й фасет;
n — количество фасетов.
При построении фасетной системы классификации необходимо, чтобы значения, используемые в различных фасетах, не повторялись. Фасетную систему легко можно модифицировать, внося изменения в конкретные значения любого фасета.
Достоинства фасетной системы классификации:
· возможность создания большой емкости классификации, т.е. использования большого числа признаков классификации и их значений для создания группировок;
· возможность простой модификации всей системы классификации без изменения структуры существующих группировок.
Недостатком фасетной системы классификации является сложность ее построения, так как необходимо учитывать все многообразие классификационных признаков.
Пример. Обратитесь к содержанию предыдущего примера, где показано построение иерархической системы классификации. Для сопоставления разработаем фасетную систему классификации.
Сгруппируем и представим в виде таблицы все классификационные признаки по фасетам:
· фасет название факультета с четырьмя названиями факультетов;
· фасет возраст с тремя возрастными группами;
· фасет пол с двумя градациями;
Структурную формулу любого класса можно представить в виде:
Ks=(Факультет, Возраст, Пол,0
Присваивая конкретные значения каждому фасету, получим следующие классы:
K1 = (Юридический факультет, возраст до 20 лет, мужчина,);
К2= (Коммерческий факультет, возраст от 20 до 30 лет, мужчина,);
Кз = (Математический факультет, возраст до 20 лет, женщина,) и т.д.
КОЛИЧЕСТВЕННАЯ ОЦЕНКА ИНФОРМАЦИИ
Общее число неповторяющихся сообщений, которое может быть составлено из алфавита
m путем комбинирования по n символов в сообщении,
. (1)
Неопределенность, приходящаяся на символ первичного (кодируемого)
[1] алфавита, составленного из равновероятностных и взаимонезависимых
символов,
. (2)
Основание логарифма влияет лишь на удобство вычисления. В случае оценки
энтропии:
а) в двоичных единицах
б) в десятичных единицах
где ;
в) в натуральных единицах
где
Так как информация есть неопределенность, снимаемая при получении сообщения, то
количество информации может быть представлено как произведение общего числа
сообщений к на среднюю энтропию Н, приходящуюся на одно
сообщение:
(3)
Для случаев равновероятностных и взаимонензависимых символов первичного алфавита
количество информации в к сообщениях алфавита m равно
а количество информации в сообщении, составленном из к
неравновероятностных символов,
(5)
Для неравновероятностных алфавитов энтропия на символ алфавита
(4)
При решении задач, в которых энтропия вычисляется как сумма произведений
вероятностей на их логарифм, независимо от того, являются ли они безусловными
, условными или
вероятностями совместных событий
.
Количество информации определяется исключительно характеристиками первичного

 Созданная иерархическая система классификации имеет глубину классификации, равную трем.
Созданная иерархическая система классификации имеет глубину классификации, равную трем.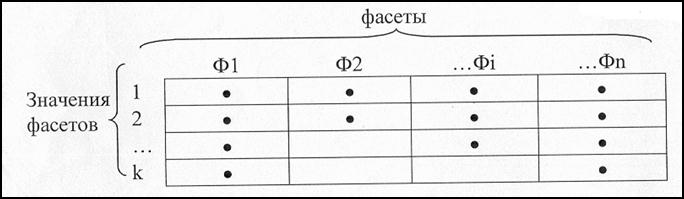 Схема построения фасетной системы классификации в виде таблицы отображена на рисунке. Названия столбцов соответствуют выделенным классификационным признакам (фасетам), обозначенным Ф1, Ф2, ..., Фi,…,Фn. Например, цвет, размер одежды, вес и т.д.
Схема построения фасетной системы классификации в виде таблицы отображена на рисунке. Названия столбцов соответствуют выделенным классификационным признакам (фасетам), обозначенным Ф1, Ф2, ..., Фi,…,Фn. Например, цвет, размер одежды, вес и т.д.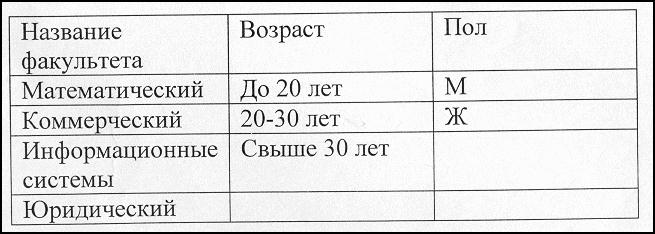 Кз = (Математический факультет, возраст до 20 лет, женщина,) и т.д.
Кз = (Математический факультет, возраст до 20 лет, женщина,) и т.д.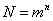 . (1)
. (1)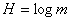 . (2)
. (2)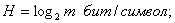
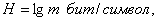
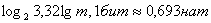 ;
;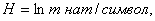
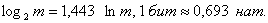
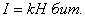 (3)
(3)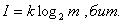
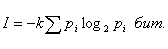 (5)
(5)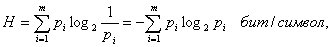 (4)
(4)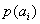
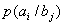 или
или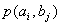
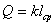 (6)
(6)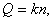
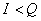 .
.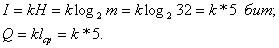
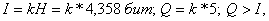
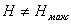
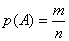

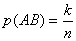
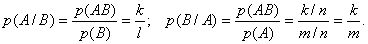 (7)
(7)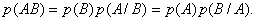 (8)
(8)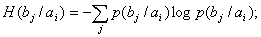 (9)
(9)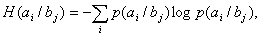 (10)
(10)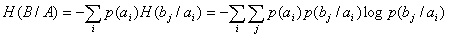
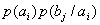
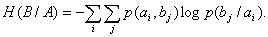 (12)
(12)
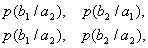
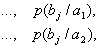
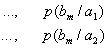 ........................
........................
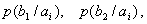
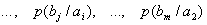 .......................
.......................