Прежде чем перейти к изучению деталей алгоритма LZ77, рассмотрим простой пример. Пусть имеется следующая бессмысленная фраза:
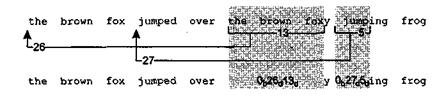
the brown fox jumped over the brown foxy jumping frog
Алгоритм обрабатывает этот текст слева направо. Вначале каждый символ преобразуется в 9-битовый код, состоящий из двоичной единицы, за которой следует 8-битовое ASCII-представление символа. Во время обработки текста алгоритм ищет повторяющиеся последовательности. Когда встречается повторяющаяся последовательность, алгоритм ищет конец такой последовательности, то есть каждый раз алгоритм отыскивает как можно больше символов. Первой такой последовательностью является the brown fox. Повторяющаяся последовательность заменяется указателем на первый экземпляр последовательности и длиной этой последовательности. В данном случае последовательность the brown fox встречается на 26 позиций раньше и имеет длину 13 символов. Для данного примера рассмотрим два варианта кодирования: 8-битовый указатель и 4-битовая длина или 12-битовый указатель и 6-битовая длина. При этом 2-битовый заголовок указывает, который вариант выбран: 00 означает первый вариант, а 01 — второй вариант. Таким образом, второй экземпляр последовательности the brown fox кодируется как <00b><26d><13d> или 00 00011010 1101.
Оставшиеся части сжатого сообщения представляют собой букву у, последовательность <00b><27d><5d>, заменяющую последовательность, состоящую из пробела, за которым следует строка jump, и последовательность символов «ing frog».
На рис. 20.7 иллюстрируется преобразование алгоритма сжатия. Сжатое сообщение состоит из 35 9-битовых символов и двух кодов, то есть всего из 35 • 9 + + 2 • 14 = 343 бит. Таким образом, при 424 бит в несжатом сообщении коэффициент сжатия данного метода в этом примере составил 1,24.
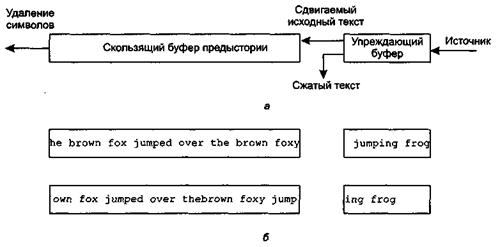
В алгоритме сжатия LZ77 и его вариантах используются два буфера. В скользящем буфере предыстории хранятся N только что обработанных символов источника, а в упреждающем буфере содержатся следующие L символов, ожидающих обработки. Алгоритм пытается найти соответствие между двумя и более символами из начала упреждающего буфера и строкой в скользящем буфере предыстории. Если соответствие не обнаружено, первый символ упреждающего буфера выводится как 9-битовый символ, а также сдвигается в скользящее окно, при этом самый старый символ выбрасывается из скользящего окна. Если совпадение обнаруживается, алгоритм продолжает искать самое длинное совпадение. Затем строка, для которой найдено соответствие, выводится в виде триплета (индикатор, указатель, длина). Затем из скользящего окна выдвигаются столько символов, сколько содержится в кодированной триплетом последовательности, и столько же новых символов исходного текста помещаются в скользящее окно.
На нижней части рисунка показана работа данной схемы с последовательностью из нашего примера. В иллюстрации предполагается использование 39-символьного скользящего окна и 13-символьного упреждающего буфера. В верхней части примера первые 40 символов были обработаны, и несжатая версия последних 39 символов находится в скользящем окне. Остальная часть сообщения находится в упреждающем буфере. Алгоритм сжатия находит следующее совпадение, сдвигает 5 символов из упреждающего буфера в скользящее окно и формирует код для этой строки. Состояние буфера после этих операций показано в нижней части примера.
Несмотря на то что алгоритм LZ77 эффективен и адаптируется к природе текущего входного потока, он обладает рядом недостатков. Для поиска совпадений в предшествующем тексте этот алгоритм использует окно конечного размера. Если размер текста намного превышает размер окна, то многие потенциальные совпадения остаются необнаруженными. Размер окна может быть увеличен, но это приведет к двум нежелательным эффектам. Во-первых, время работы алгоритма возрастет. Во-вторых, придется увеличить размер поля указателя.