Многомерные массивы, обсуждавшиеся в предшествующем разделе, обычно называются прямоугольными, поскольку у них каждая "строка" имеет один и тот же размер. Если использовать наш пример, то координата у может изменяться от 0 до 2 для любой координаты х. Однако существует возможность использовать ступенчатые (jagged) массивы, у которых "строки" могут быть неодинакового размера. Для этого требуется массив, каждым элементом которого также является массив. При желании можно использовать массивы массивов и даже более сложные конструкции. Однако это оказывается возможным только в том случае, если все массивы имеют один и тот же базовый тип.
Синтаксис, применяемый для объявления массива массивов, подразумевает использование в объявлении массива нескольких пар квадратных скобок, например:
int[][] jaggedIntArray;
К сожалению, инициализация подобных массивов оказывается не таким простым делом, как инициализация многомерных массивов. Так, например, мы не имеем возможности использовать вслед за этим объявлением следующую запись:
jaggedIntArray = new int [ 3 ] [ 4 ] ;
Но даже в том случае, если бы мы могли применять запись такого вида, вряд ли от этого была бы какая-нибудь польза, поскольку в случае многомерных массивов точно такого же эффекта можно достичь с меньшими затратами. Следующий код также является недопустимым:
jaggedInt Array = {{1, 2, 3), {1}, {1, 2}};
На самом деле существуют две возможности. Можно сначала инициализировать массив, содержащий другие массивы (чтобы избежать путаницы, мы будем называть вложенные массивы субмассивами), а затем, в свою очередь, инициализировать эти субмассивы:
jaggedIntArray - new int[2][];
jaggedIntArray [0] = new int[3];
jaggedInt Array [1] = new int[4];
Можно также воспользоваться видоизмененной формой приведенного выше литерального присваивания:
jaggedIntArray = {new int[] {1, 2, 3}, new int[] {1}, new int[] {1,2}};
Для таких неоднородных массивов можно использовать циклы foreach, однако чаще всего вложенные циклы применяются для того, чтобы получить доступ к реальным данным. Например, допустим, что имеется следующий неоднородный массив, который включает в себя десять других массивов, каждый из которых содержит целые значения, являющиеся делителями целых чисел из диапазона от 1 до 10:
int[] [] divisorsITo10 = {new int[] {1},
new int[] {1,2},
new int[] {1, 3},
new int[] {1, 2, 4}, ;
new int [] {1, 5},
new int[] {1, 2, 3, 6},
new int[] {1,7},
new int [] {1, 2, 4, 8},
new int[] {1, 2, 5, 1С}};
Использование следующего кода:
foreach (int divisor in divisorsITo10)
{
Console.WriteLine(divisor);
}
является недопустимым, поскольку divisorsITo10 содержит в себе не элементы int, а элементы int [ ]. Поэтому нам придется проходить не только по самому массиву, но и непосредственно по каждому субмассиву:
foreach (int[] divisorsOfInt in divisorsITo10)
{
foreach (int divisor in divisorsOfInt)
{
Console.WriteLine(divisor);
}
}
Элементы в них однотипные, но количество их не фиксируется в структуре. Динамические структуры – это:
последовательность,
стек,
очередь,
дек,
список,
деревья,
графы (на 2 курсе)
У каждого из этих типов своя дисциплина работы с элементами, она определяет свой набор допустимых операцийнад элементами.
1) Последовательность –характерен последовательный доступ к элементам,последовательно расположенным, так, что добраться до какого–то элемента можно только просмотрев все предшествующие ему. Поступающие элементы встают в конец последовательности, а читаются из её начала Этот тип данных реализован в языках в типе “последовательный файл” , все операции соответствуют операциям чтения из файла, записи в файл. Последовательность может быть закрыта, либо открыта для чтения из неё элементов, либо открыта для записи в неё элементов..
Операции:пусть S – последовательность элементов типа T.
1.Открыть последовательность S для чтения.
2.Читать элемент x типа T из последовательности S, если есть непрочитанные.
3. Проверить , есть ли непрочитанные элементы в последовательности.
4. Открыть последовательность S для записи.
5. Добавить элемент x типа T в последовательность S.
6. Закрыть последовательность S.
2) Стек –структура данных, в которой могут накапливаться однотипные данные, при этом выполняется условие: элементы можно выбирать из стека в порядке, обратном порядку их поступления. Это условие называют принципом LIFO: Last –In- First- Out (последний пришел, первый уйдёшь).
дно стека вершина
Пусть S – стек элементов типа Т.
Операции для работы со стеком:
1. Сделать стек S пустым: clrst (S).
2. Добавить элемент x типа Т в стек S: push(S, x).
3. Удалить элемент из непустого стека S: pop(S).
4. Проверить стек S на пустоту:
true , если S пустой
emptyst(S)= .
5. Выбрать элемент x типа Т из вершины стека без удаления: x = topst(S).
Типа стекв языках нет. Такие совокупности можно моделировать, например на базе массива, тогда получается ограниченный стек.
3) Очередь –структура данных, в которой элементы накапливаются в соответствии с принципом FIFO:
First –In- First- Out (первый пришел, первый уйдешь)
Операции для очереди q с элементами типа Т:
1. Сделать очередь q пустой: clrqu(q).
2. Добавить элемент a типа Т в очередь q : insqu(q,a).
3. Удалить элемент из непустой очереди q: remqu(q).
4. Проверить очередь q на пустоту:
true , если q пустая
emptyqu(q)= .
5. Выбрать элемент a типа Т из непустой очереди без удаления: a= topqu(q).
4. Дек – очередь с двумя концами (double ended queue)







 дно стека вершина
дно стека вершина Проверить стек S на пустоту:
Проверить стек S на пустоту: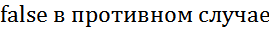 .
.