Шаг 1. Упорядочиваем символы исходного алфавита в порядке невозрастания их вероятностей. (Записываем их в столбец.)
Шаг 2. Объединяем два символа с наименьшими вероятностями. Символу с большей вероятностью приписываем "1", символу с меньшей – "0" в качестве элементов их кодов.
Шаг 3. Считаем объединение символов за один символ с вероятностью, равной сумме вероятностей объединенных символов.
Шаг 4. Возвращаемся на Шаг 2 до тех пор, пока все символы не будут объединены в один с вероятностью, равной единице.
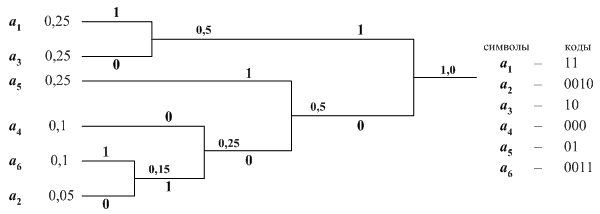
Закодируем тот же 6-буквенный алфавит методом Хаффмана, изобразив соответствующее двоичное дерево (рис. 4.2).
Рис. 4.2. Двоичное дерево, соответствующее кодированию по методу Хаффмана
Считывание кода идет от корня двоичного дерева к его вершинам с обозначением символов. Это обеспечивает префиксность кода. Метод Хаффмана также содержит неоднозначность, поскольку в алфавите могут оказаться несколько символов с одинаковой вероятностью, и код будет зависеть от того, какие символы мы будем объединять в первую очередь. Мы видим, что код Шеннона – Фано и код Хаффмана для заданного алфавита отличаются. На вопрос, какой из них лучше, даст ответ проверка на оптимальность.
Описанные методы легко применить не только для двоичного кодирования, но и для кодирования алфавитом, содержащим произвольное число символов . В этом случае в методе Шеннона – Фано идет разбиение последовательности символов на равновероятных групп, в методе Хаффмана – объединение в группы по символов.
Проверка кода на оптимальность.Для оценивания оптимальности кода используют разные критерии. Основным показателем является коэффициент относительной оптимальности , вычисляемый по формуле
. (4.1)
Из теоремы кодирования следует, что эта величина не превышает единицы. И чем меньше она отличается от единицы, тем более эффективным считается код.
Следующая характеристика оптимальности кода обусловлена оценкой распределения символов кодового алфавита: код тем ближе к оптимальному, чем меньше различаются вероятности появления различных символов кодового алфавита в закодированном сообщении. Среднее число появлений -го ( j = 1, …, M ) символа кодового алфавита можно оценить по формуле
,
где N – объем исходного алфавита;
mij– число bj - х символов в коде ai-го символа исходного алфавита;
pi– вероятность появления ai-го символа.
Рассмотрим эти оценки оптимальности применительно к двоичному кодированию, как наиболее распространенному. Признаки оптимальности двоичного кода вытекают из предыдущих формул при условии, что кодовый алфавит равновероятен, т.е. H(B) = 1.
Признак 1. Средняя длина кодового слова должна быть приблизительно равна энтропии кодируемого алфавита:
.
(4.2)
Признак 2. Среднее число нулей и единиц в кодовой последовательности должно быть приблизительно одинаково:
,
(4.3)
где
, .
Здесь – число нулей в коде -го символа;
– число единиц в коде -го символа;
– вероятность -го символа;
– число символов в исходном алфавите.
Термин "приблизительно" условимся понимать как с точностью до 10%.
Выполним проверку на оптимальность двоичного кода, полученного методом Шеннона – Фано для алфавита A = {a1, a2, a3, a4, a5,a6} с вероятностями появления отдельных символов (0,25 – 0,3 – 0,15 – 0,2 – 0,05 – 0,05) соответственно. Для удобства занесем все необходимые данные в таблицу, расположив в ней символы в порядке невозрастания вероятностей.
ai
pi
Код
li
n 0i
n 1i
a2
0,3
0 0
a1
0,25
0 1
a4
0,2
1 0
a3
0,15
1 1 0
a5
0,05
1 1 1 0
a6
0,05
1 1 1 1
Итак, в соответствии с первым признаком: ,
симв.
симв.
Второй признак, к сожалению, выполняется хуже.
Блочное кодирование.В отличие от побуквенного, блочное кодирование формирует коды для буквосочетаний, составленных из m символов исходного алфавита. Буквосочетания можно рассматривать как новый, расширенный алфавит объемом , где N – объем исходного алфавита; m – число символов в буквосочетании.
Блочное кодирование применяется к алфавитам, в которых вероятность появления одной какой-то буквы значительно превышает вероятность появления других букв. Например, алфавит {a, b, c} с вероятностями pa= 0,7; pb= 0,2; pc= 0,1. Методы побуквенного кодирования здесь не будут эффективными, так как невозможно обеспечить разбиение алфавита на равновероятные подгруппы, равно как и объединение равноценных групп элементов. Расширенный алфавит имеет более сглаженную разницу в вероятностях буквосочетаний, что и позволяет добиться большей оптимальности при его кодировании.
Из теории вероятностей известно, что если буквы появляются независимо одна от другой, то вероятность появления некоторой последовательности букв равна произведению вероятностей входящих в нее букв. Исходя из этого, рассчитываем вероятности для буквосочетаний и кодируем их одним из методов побуквенного оптимального кодирования (т. е. методом Шеннона – Фано или методом Хаффмана).
Рассмотрим это для приведенного выше алфавита и убедимся в большей эффективности блочного кодирования в подобных ситуациях.
Буква
pi
Код
li
pili
a
0,7
0,7
b
0,2
1 0
0,4
c
0,1
1 1
0,2
Энтропия данного алфавита равна
;
средняя длина кодового слова ;
избыточность кода
Теперь составим таблицу сочетаний из 2 букв.
Сочетание
pi
Код Ш – Ф
li
pili
aa
0,49
0,49
ab
0,14
0,42
ba
0,14
0,42
ac
0,07
0,28
ca
0,07
0,28
bb
0,04
0,16
bc
0,02
0,10
cb
0,02
0,12
cc
0,01
0,06
Получим:
2,33 дв. симв.,
1,165 дв. симв.
Отсюда
1,165 – 1.157 = 0,008 дв. симв.
При сравнивании результатов кодирования очевидно, что применение блочного кодирования позволило снизить избыточность кода почти в 20 раз.
Действуя аналогично, можно закодировать алфавит блоками по 3 и по 4 символа. Это позволит еще больше оптимизировать код, приближая среднюю длину кодового слова к энтропии алфавита, как и утверждает теорема кодирования. Однако практика показывает, что с увеличением числа символов в блоке больше четырех, сложность кодирующего устройства растет быстрее, чем оптимальность кода. Поэтому применение слишком длинных блоков нецелесообразно.
Единая система кодирование текстовой информации.Ознакомившись с теоретическими основами кодирования, можно перейти к рассмотрению способов кодирования текстовых данных, применяющихся на практике для обмена информацией в компьютерных системах.
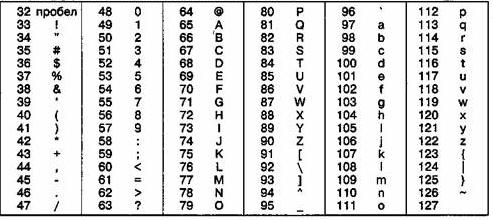
Естественные человеческие языки сами есть не что иное, как системы кодирования понятий для выражения мыслей посредством речи. Несмотря на разнообразие природных языков общие подходы к кодированию сообщений одинаковы. Учитывая потребности обмена информацией, постоянно велась работа по созданию единых стандартов кодирования текстовых данных. Поскольку английский язык стал средством международного общения, для него была разработана и введена в действие система кодирования ASCII ( American Standard Code for Information Interchange - стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования – базовая и расширенная. Базовая закрепляет значения кодов от 0 до 127, а расширенная от 128 до 255. Коды являются двоичными, равномерными, восьмиразрядными. Первые 32 кода, начиная с нулевого, являются управляющими, они предоставлены производителям вычислительной техники. С 32 по 127 коды заняты символами английского языка, цифрами, знаками препинания, обозначениями арифметических функций и вспомогательных символов. Коды, начиная со 128 отведены под национальные алфавиты. Кодировка символов русского языка, известная как Windows 1251, была введена компанией Microsoft и закрепилась благодаря широкому распространению продукции этой компании в России. Базовая таблица ASCII приведена в таблице 4.1, расширенная таблица Windows 1251 приведена в таблице 4.2.
Таблица 4.1
Базовая таблица кодировки ASCII
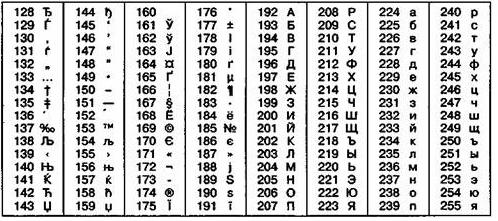
Таблица 4.2
Кодировка Windows 1251
Мы видим, что каждому символу в таблицах 4.1 и 4.2 поставлены в соответствие номера; 8-разрядный двоичный код номера и будет являться кодом символа. Так, символу А соответстует номер 65. Значит, код А будет представлть собой последовательность 01000001.
Аналогичные системы кодирования были разработаны в свое время и в Советском Союзе, это КОИ-7 (код обмена информацией 7-разрядный) и КОИ-8. Сегодня кодировка КОИ-8 (восьмиразрядный код) широко используется на территории России и в российском секторе Internet .
Трудности всемирного использования системы ASCII заключаются в недостаточности 8-разрядных кодов для всего множества национальных алфавитов. Однако в настоящее время технические средства достигли такого уровня, что позволяют использовать 16-разрядные коды, которыми можно закодировать алфавит объемом 65 536 символов. Этого поля достаточно для размещения в одной таблице символов большинства языков планеты. Система, основанная на 16-разрядном кодировании символов, получила название универсальной – UNICODE . Сегодня происходит постепенный перевод документов и программных средств на универсальную систему кодирования.

 . В этом случае в методе Шеннона – Фано идет разбиение последовательности символов на
. В этом случае в методе Шеннона – Фано идет разбиение последовательности символов на 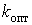 , вычисляемый по формуле
, вычисляемый по формуле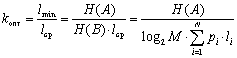 . (4.1)
. (4.1)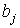 -го ( j = 1, …, M ) символа кодового алфавита можно оценить по формуле
-го ( j = 1, …, M ) символа кодового алфавита можно оценить по формуле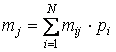 ,
,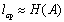 .
.
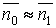 ,
,
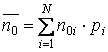 ,
, 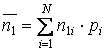 .
.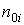 – число нулей в коде
– число нулей в коде 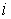 -го символа;
-го символа;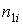 – число единиц в коде
– число единиц в коде 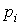 – вероятность
– вероятность  – число символов в исходном алфавите.
– число символов в исходном алфавите.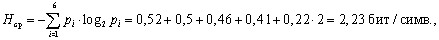

 ,
, симв.
симв. симв.
симв. , где N – объем исходного алфавита; m – число символов в буквосочетании.
, где N – объем исходного алфавита; m – число символов в буквосочетании.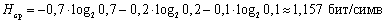 ;
;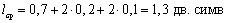 ;
;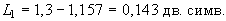
 2,33 дв. симв.,
2,33 дв. симв.,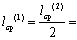 1,165 дв. симв.
1,165 дв. симв. 1,165 – 1.157 = 0,008 дв. симв.
1,165 – 1.157 = 0,008 дв. симв.