Связь и кодирование. Равномерные и неравномерные коды. Проблемы декодирования, условие Фано. Количество и объем информации. Избыточность кода.
Связь и кодирование. Появление технических средств связи повлекло за собой создание методов кодирования сообщений. Передача информации по техническим каналам связи оказалась возможной лишь для сообщений, представленных в строго определенном виде – в закодированном. Основной задачей теории и практики кодирования становится разработка методов преобразования информации, удовлетворяющих современным техническим средствам ее передачи.
Еще в древности люди умели передавать сигналы на расстояние с помощью огня. Однако считается, что современные очертания связь приобрела с появлением оптического телеграфа, изобретенного К. Шаппом (1791 г.). Решающим этапом в процессе развития связи явилось изобретение С. Морзе телеграфного аппарата (1837 г.), а затем и азбуки Морзе. Это изобретение актуально до сих пор, так как оно основано на двоичном кодировании, которое просто смоделировать физически: "1" – есть электрический ток, "0" – нет тока.
Дальнейшее усовершенствование телеграфного аппарата, а также прокладка межконтинентальных кабелей завершились появлением коммерческого телеграфа и сертификацией международного телеграфного кода. Там, где невозможно было использовать провода, по-прежнему оказались необходимы оптические средства связи, такие как международный флажковый код, изобретенный капитаном Ф. Марьятом (1817 г.), а также семафоры и светофоры, до сих пор применяющиеся на железных дорогах. Изобретение радио Поповым и Маркони избавило связь от проводов. А с изобретением телевидения (1935 г.) развитие средств связи временно стабилизируется.
Теория кодирования всё это время развивается с двух направлений. Первое – это создание двоичных кодов с особыми свойствами, полезными с технической точки зрения. К ним можно отнести циклические и одношаговые коды Ж. Бодо (1889 г.), помехоустойчивые коды ван Дуурена (1937 г.) и код Р. Хемминга (1950 г.), позволяющий обнаруживать и исправлять некоторые ошибки, возникающие при передаче сообщений. Второе – это обеспечение криптографической надежности сообщений, особенно актуальное в годы Второй мировой войны. Занимаясь решением этой задачи, Клод Шеннон (1948 г.) и создал теорию (количества) информации. В серии работ он рассмотрел вопросы оптимального кодирования, а также передачи информации при наличии помех.
Получившие свое начало в области связи методы кодирования обретают особую актуальность с появлением вычислительных машин. Любая информация в компьютере представлена в закодированном виде, причем многообразие ее носителей (оперативная память, магнитные диски, дисплей и т. д.) предполагают разнообразие информационных кодов. Кроме того, важнейшей задачей теории кодирования становится проблема сжатия информации с целью ее хранения, восстановления в случае отказов, и увеличения скорости передачи на расстояние.
Итак, перейдем к основным понятиям теории кодирования.
Кодированиембудем считать процесс отображения одного набора знаков в другой, а кодом – множество образов при этом отображении.
При кодировании используются два алфавита: исходный A = {a1, a2,…,aN} и кодовый B = {b1, b2,…,bM}. Обычно N > M. Кодирование заключается в записи символов исходного алфавита А с помощью символов кодового алфавита В. Каждому символу алфавита А ставится в соответствие некоторая последовательность символов алфавита В, называемая кодом или кодовым словом. Число символов в кодовом слове называется длиной кодового слова. Коды бывают двух типов: равномерные – когда длина всех кодовых слов (или их разрядность) одинакова, и неравномерные – когда кодовые слова имеют разную длину.
Равномерные кодыхарактеризуются минимальной разрядностью кодовых слов, которая рассчитывается по формуле
(3.1)
где – объем исходного алфавита А;
– объем кодового алфавита В;
означает целую часть числа .
Рассмотрим эти формулы для случая двоичного кодирования (т. е. при М = 2). Минимальная разрядность равномерного кода для алфавита объемом 8 символов будет равна . А для 9-бук-венного алфавита .
Нетрудно заметить, что есть целое число. В большинстве случаев за счет округления числа H(A) до целого, что порождает избыточность кода, о которой будет сказано далее.
Рис. 3.1. Равномерное двоичное кодирование путем построения дерева
Если кодовый алфавит состоит из двух символов В = {0, 1}, то, как уже отмечалось, такое кодирование называется двоичным. Двоичный равномерный код легко получить путем построения двоичного дерева. Пусть исходный алфавит A = {0, 1, 2, 3, 4, 5, 6, 7} насчитывает 8 символов, тогда двоичное дерево для кодирования его символов будет иметь вид, представленный на рис. 3.1. Код каждого символа исходного алфавита считывается с дерева, двигаясь от корня к листьям, и состоит из 3 символов кодового.
По формуле (3.3) можно найти количество информации, содержащееся в кодовом слове: . Мы видим, что двоичный код содержит столько бит информации, сколько нулей и единиц в нем содержится.
Можно составить кодовые слова и не прибегая к построению дерева. Для этого после расчета разрядности достаточно выписывать последовательности из r символов кодового алфавита В в лексикографическом порядке (заметим, что могут быть и другие варианты составления кодов). Возьмем, например, алфавиты А = {0, 1, 2, 3} и В = { a , b }. Рассчитаем . Запишем символы алфавита В в лексикографическом (как в словаре) порядке по 2: aa , ab , ba , bb . Это и будут коды для символов алфавита А.
Результаты рассмотренных двух способов кодирования совпадают, если обозначать ветви кодового дерева слева направо в соответствии с порядком букв в алфавите B.
Декодирование сообщений, составленных в равномерном коде, не представляет сложности. Достаточно считывать символы сообщения группами по r символов и сопоставлять их с таблицей кодов.
Неравномерные кодыхарактеризуются средней длиной кодового слова
(3.2)
где – длина кодового слова i -го символа;
– вероятность появления i -го символа;
– объем исходного алфавита.
Например, если алфавит А = {a, b, c, d, e} с вероятностями появления символов в сообщениях (pa= 0,5; pb= 0,2; pc= 0,1; pd= 0,15; pe= 0,05) закодирован двоичным неравномерным кодом (a – 0; b – 10; c – 1110; d – 110; e – 1111), то средняя длина кодового слова для такого алфавита будет
.
Таким образом, средняя длина кодового слова есть сумма длин всех кодовых слов, взятых с весом, равным вероятности появления кодируемого символа.
В отличие от равномерного кода, при котором декодирование не представляет проблемы, неравномерный код требует специальных мер для обеспечения правильного и однозначного декодирования сообщений. Простейший способ – ввести разделитель между отдельными кодовыми словами, зарезервировав для этого либо один символ кодового алфавита, либо кодовую последовательность. Однако это ведет к увеличению нагрузки на канал связи, так как сообщение увеличивается по объему. На практике разделимые неравномерные коды строятся на основе соблюдения условия Фано, или принципа префиксности.
Условие Фано. Для того чтобы неравномерный код был однозначно и правильно декодируем, достаточно при его построении обеспечить выполнение следующего условия: никакое кодовое слово не должно быть началом никакого другого кодового слова.
В этом случае декодирование заключается в считывании сообщения по одному символу и сопоставлении прочитанного с таблицей кодов. Как только считанная последовательность символов декодируется – она исключается из рассмотрения. Например, пусть алфавит {A , B , C} закодирован в алфавите {0, 1} префиксным неравномерным кодом: (A – 0, B – 10, C – 110). Полученное сообщение имеет вид 01010110. Считываем первый символ – "0", он декодируется как А. Оставшаяся часть сообщения будет 1010110. Считываем первый символ – "1". Такого кода в таблице нет, значит, читаем еще один символ и получаем последовательность "10". Она декодируется как В. Поступая аналогично с оставшейся частью сообщения 10110, получим исходное декодированное сообщение ABBC.
Приведем пример применения разделителя. Так, в азбуке Морзе символ А имеет код ( ), символ Б – (). В современных средствах связи символы азбуки Морзе представлены своими двоичными эквивалентами () – 1; ( –) – 111. Пауза между точками и тире обозначается нулем. Разделитель между буквами – три нуля (000). Так сообщение АБ ()() будет иметь вид
.
Мы видим, что разделитель позволяет надежно отличать один символ от другого.
Несмотря на сложности декодирования, следует подчеркнуть, что применение неравномерных кодов позволяет добиться того, что средняя длина кодового слова будет меньше, чем минимальная разрядность при кодировании того же алфавита равномерным кодом. Это дает преимущество неравномерному коду с точки зрения избыточности.

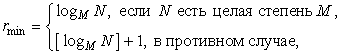
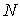 – объем исходного алфавита А;
– объем исходного алфавита А;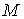 – объем кодового алфавита В;
– объем кодового алфавита В;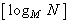 означает целую часть числа
означает целую часть числа 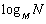 .
.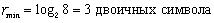 . А для 9-бук-венного алфавита
. А для 9-бук-венного алфавита 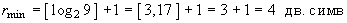 .
.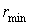 есть целое число. В большинстве случаев
есть целое число. В большинстве случаев 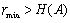 за счет округления числа H(A) до целого, что порождает избыточность кода, о которой будет сказано далее.
за счет округления числа H(A) до целого, что порождает избыточность кода, о которой будет сказано далее.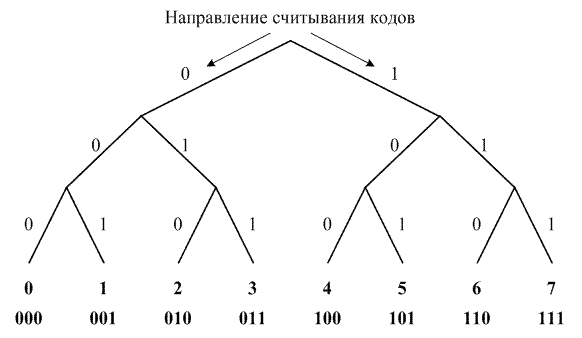
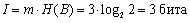 . Мы видим, что двоичный код содержит столько бит информации, сколько нулей и единиц в нем содержится.
. Мы видим, что двоичный код содержит столько бит информации, сколько нулей и единиц в нем содержится. . Запишем символы алфавита В в лексикографическом (как в словаре) порядке по 2: aa , ab , ba , bb . Это и будут коды для символов алфавита А.
. Запишем символы алфавита В в лексикографическом (как в словаре) порядке по 2: aa , ab , ba , bb . Это и будут коды для символов алфавита А.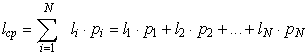
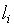 – длина кодового слова i -го символа;
– длина кодового слова i -го символа;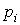 – вероятность появления i -го символа;
– вероятность появления i -го символа;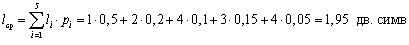 .
. ), символ Б – (
), символ Б – ( ). В современных средствах связи символы азбуки Морзе представлены своими двоичными эквивалентами (
). В современных средствах связи символы азбуки Морзе представлены своими двоичными эквивалентами ( ) – 1; ( –) – 111. Пауза между точками и тире обозначается нулем. Разделитель между буквами – три нуля (000). Так сообщение АБ (
) – 1; ( –) – 111. Пауза между точками и тире обозначается нулем. Разделитель между буквами – три нуля (000). Так сообщение АБ (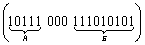 .
.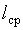 будет меньше, чем минимальная разрядность
будет меньше, чем минимальная разрядность