Сортировка Шелла была названа в честь ее изобретателя – Дональда Шелла, который опубликовал этот алгоритм в 1959 году. Общая идея сортировки Шелла состоит в сравнении на начальных стадиях сортировки пар значений, расположенных достаточно далеко друг от друга в упорядочиваемом наборе данных. Такая модификация метода сортировки позволяет быстро переставлять далекие неупорядоченные пары значений (сортировка таких пар обычно требует большого количества перестановок, если используется сравнение только соседних элементов).
Общая схема метода состоит в следующем.
Шаг 1. Происходит упорядочивание элементов n/2 пар (xi,xn/2+i) для 1<i<n/2.
Шаг 2. Упорядочиваются элементы в n/4 группах из четырех элементов (xi,xn/4+i,xn/2+i,x3n/4+i) для 1<i<n/4.
Шаг 3. Упорядочиваются элементы уже в n/4 группах из восьми элементов и т.д.
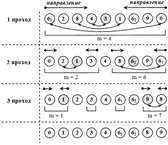
На последнем шаге упорядочиваются элементы сразу во всем массиве x1,x2,...,xn. На каждом шаге для упорядочивания элементов в группах используется метод сортировки вставками ( рис. 42.2).
В настоящее время неизвестна последовательность hi,hi-1,hi-2,...,h1,, оптимальность которой доказана. Для достаточно больших массивов рекомендуемой считается такая последовательность, что hi+1=3hi+1, а h1=1. Начинается процесс с hm, что hm>[n/9]. Иногда значение h вычисляют проще: hi+1=hi/2,h1=1,hm=n/2. Это упрощенное вычисление h и будем использовать далее.
Рис. 42.2.Демонстрация сортировки по неубыванию методом Шелла
//Описание функции сортировки Шеллаvoid Shell_Sort (int n, int *x){ int h, i, j; for (h = n/2 ; h > 0 ; h = h/2) for (i = 0 ; i < n-h ; i++) for (j = i ; j >= 0 ; j = j - h) if (x[j] > x[j+h]) Exchange (j, j+h, x); else j = 0;}//процедура обмена двух элементовvoid Exchange (int i, int j, int *x){ int tmp; tmp = x[i]; x[i] = x[j]; x[j] = tmp;}
Метод, предложенный Дональдом Л. Шеллом, является неустойчивой сортировкой по месту.
Эффективность метода Шелла объясняется тем, что сдвигаемые элементы быстро попадают на нужные места. Среднее время для сортировки Шелла равняется O(n1.25), для худшего случая оценкой является O(n1.5).
Метод быстрой сортировки был впервые описан Ч.А.Р. Хоаром в 1962 году. Быстрая сортировка – это общее название ряда алгоритмов, которые отражают различные подходы к получению критичного параметра, влияющего на производительность метода.
При общем рассмотрении алгоритма быстрой сортировки, отметим, что этот метод основывается на последовательном разделении сортируемого набора данных на блоки меньшего размера таким образом, что между значениями разных блоков обеспечивается отношение упорядоченности (для любой пары блоков все значения одного из этих блоков не превышают значений другого блока).
Опорным (ведущим) элементом называется некоторый элемент массива, который выбирается определенный образом. С точки зрения корректности алгоритма выбор опорного элемента безразличен. С точки зрения повышения эффективности алгоритмавыбираться должна медиана, но без дополнительных сведений о сортируемых данных ее обычно невозможно получить. Необходимо выбирать постоянно один и тот же элемент (например, средний или последний по положению) или выбирать элемент со случайно выбранным индексом.
Алгоритм быстрой сортировки Хоара
Пусть дан массив x[n] размерности n.
Шаг 1. Выбирается опорный элемент массива.
Шаг 2. Массив разбивается на два – левый и правый – относительно опорного элемента. Реорганизуем массив таким образом, чтобы все элементы, меньшие опорного элемента, оказались слева от него, а все элементы, большие опорного – справа от него.
Шаг 3. Далее повторяется шаг 2 для каждого из двух вновь образованных массивов. Каждый раз при повторении преобразования очередная часть массива разбивается на два меньших и т. д., пока не получится массив из двух элементов (рис. 42.3).
Быстрая сортировка стала популярной прежде всего потому, что ее нетрудно реализовать, она хорошо работает на различных видах входных данных и во многих случаях требует меньше затрат ресурсов по сравнению с другими методами сортировки.
Выберем в качестве опорного элемент, расположенный на средней позиции.
Рис. 42.3.Демонстрация быстрой сортировки Хоара по неубыванию
//Описание функции сортировки Хоараvoid Hoar_Sort (int k, int *x){ Quick_Sort (0, k-1, x);} void Quick_Sort(int left, int right, int *x){ int i, j, m, h; i = left; j = right; m = x[(i+j+1)/2]; do { while (x[i] < m) i++; while (x[j] > m) j--; if (i <= j) { Exchange(i,j,x); i++; j--; } } while(i <= j); if (left < j) Quick_Sort (left, j, x); if (i < right) Quick_Sort (i, right, x);} //процедура обмена двух элементовvoid Exchange (int i, int j, int *x){ int tmp; tmp = x[i]; x[i] = x[j]; x[j] = tmp;}
Эффективность быстрой сортировки в значительной степени определяется правильностью выбора опорных (ведущих) элементов при формировании блоков. В худшем случае трудоемкость метода имеет ту же сложность, что и пузырьковая сортировка, то есть порядка O(n2). При оптимальном выборе ведущих элементов, когда разделение каждого блока происходит на равные по размеру части, трудоемкость алгоритма совпадает с быстродействием наиболее эффективных способов сортировки, то есть порядка O(n log n). В среднем случае количество операций, выполняемых алгоритмом быстрой сортировки, определяется выражениемT(n) = O(1.4n log n)
Быстрая сортировка является наиболее эффективным алгоритмом из всех известных методов сортировки, но все усовершенствованные методы имеют один общий недостаток – невысокую скорость работы при малых значениях n.
Рекурсивная реализация быстрой сортировки позволяет устранить этот недостаток путем включения прямого метода сортировки для частей массива с небольшим количеством элементов. Анализ вычислительной сложности таких алгоритмов показывает, что если подмассив имеет девять или менее элементов, то целесообразно использовать прямой метод (сортировку простыми вставками).