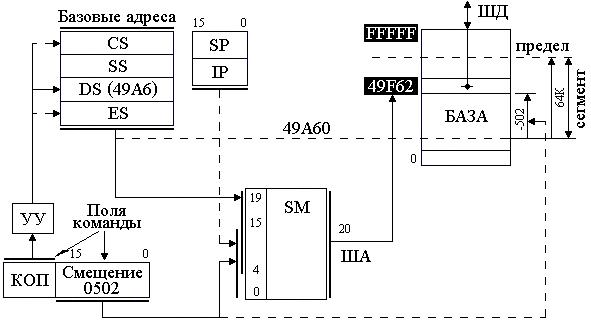
Для эффективного распределения памяти в микропроцессорах 8086/88 была введена сегментация. Под сегментом в них принята область 64К смежных ячеек в любом месте адресного пространства от 0 до FFFFF. Для вычисления адреса используются четыре 16-разрядных регистра: кода CS, стека SS, данных DS, дополнительных данных ES. В этих регистрах для программы задаются базовые физические адреса начала сегмента. Так как шина адреса в 8086/88 20-разрядная, а ШД и сегментные регистры 16-разрядные, то принято, что 4 младших бита любого базового адреса равны 0. Поэтому базовые адреса указывают на границу параграфа (область памяти по 16 смежных байта, начиная с нулевого адреса) и используются для вычисления адреса по схеме, изображенной на рис. 3.11.
В зависимости от типа команды, который определяется полем кода операции (КОП), устройство управления (УУ) для вычисления адреса команды или операнда в памяти привлекает один из соответствующих сегментных регистров CS, SS, DS или ES. Содержимое этих регистров подается в 16 старших разрядов сумматора (передача со сдвигом на 4 разряда влево – L4), а к 16 младшим разрядам сумматора подключается "смещение". При этом вычисление адреса в сумматоре происходит по модулю 220 (перенос из старшего разряда отбрасывается, т.е. осуществляется заворачивание адреса) по одной из формул:
<ФА (19,0)> = [L4[CS)] + [IP],
<ФА (19,0)> = [L4(SS)] + [SP],
<ФА (19,0)> = [L4(DS или ES)] + [EA],
где: <ФА (19,0)> – двоичный 20-разрядный код, передаваемый на шину адреса; IP, SP – содержимое счетчика команд и указателя стека соответственно; ЕА – смещение, располагаемое в поле команды, которое вычисляется по схеме рис. 1.5 для 16-битной адресации 8086, 286 без- масштабирования и защиты нарушения, где в качестве базы массива используется только РОН ВХ или ВР, индексов SI или DI.
На рис. 3.11 в качестве примера рассмотрено вычисление адреса 49F62h операнда через адрес: сегмент :смещение = 49А6:0502, при обработке его командой (обращение по умолчанию к DS) со смещением в поле команды 0502h. В регистре DS хранится базовый адрес сегмента данных 49A6h, в котором 4 младших нулевых бита адреса не представлены. К недостаткам сегментной адресации в 8086 можно отнести: отсутствие контроля и защиты данных от неправильного использования сегментов; возможность обращения к несуществующей физической памяти.
В дальнейшем, с целью изолирования программ и данных, организации динамического распределения памяти, фиксации ошибок программирования устройство сегментации было усовершенствовано.
FFFFF
49F62
Рис. 3.11. Схема вычисления адреса в МП 8086
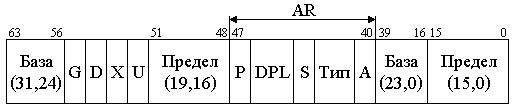
В i486, Pentium под сегментом понимается защищенная область линейного адресного пространства. Все пространство разбито на 16 383 сегмента, а их адреса и характеристики (атрибуты) занесены в дескрипторные таблицы GDT, IDT, LDT. Глобальная дескрипторная таблица GDT и дескрипторная таблица прерываний IDT создаются операционной системой для всех задач, фигурирующих в системе, а локальная таблица LDT может быть создана системным программистом для своих прикладных задач. Элементами этих таблиц являются дескрипторы размером в 8 байт с содержанием полей, приведенным на рис. 3.12.
Рис. 3.12. Дескриптор сегмента
Дескриптор содержит:
- линейный базовый адрес сегмента Вс (31,0) в полях, соответствующих разрядам (63,56) и (39,16);
- размер сегмента (предел) Рс (19,0), который находится в разрядах (51,48) и (15,0);
- байт прав доступа AR в разрядах (47,40).
Атрибуты дескриптора имеют следующее назначение:
- А – бит доступа, устанавливается в "1" операционной системой при обращении к сегменту, используется в свопинге;
- Тип – 3 бита определяют назначение сегмента и допустимые в нем операции: <000> – сегмент "0" - предназначен для данных и только считывания, 1 (<001>) - сегмент данных для записи и считывания, 2 – стек для считывания, 3 – стек для записи и считывания, 4-6 – сегмент кода, 7 – <111> подчиненный сегмент кода с разрешением выполнения и считывания. Операция выполнения предполагает использование считанного сегмента как команды, а считывания – как данных, причем запись в любой сегмент кода запрещена;
- S – системный. При S = 0 дескриптор описывает системный объект;
- DPL – двухбитное поле, определяет привилегии от 0 до 3 (код <11> – наименьший уровень);
- Р – присутствие (Р = 1 – сегмент находится в физически доступной памяти).
Бит дескриптора U используется при необходимости пользователем, бит Х зарезервирован (Х = 0). Бит D = 1 команда работает с 32-битными данными. Бит G является битом гранулярности. При G = 0 предел измеряется в байтах, при G = l предел измеряется в страницах Рс ´ 4К.
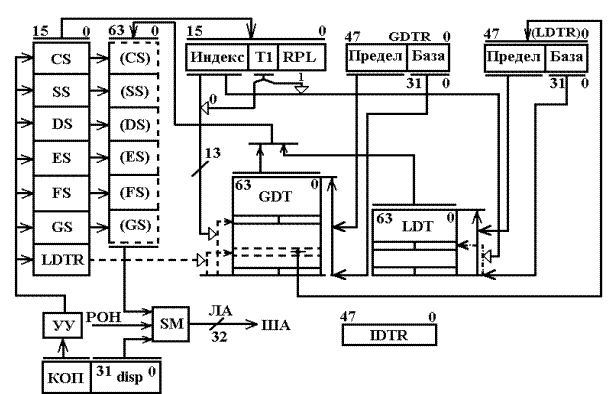
Число дескрипторов в таблицах IDT и GDT может достигать величины 8192, а наибольший размер любой таблицы = 8 ´ 8192 = 64 Кб. Эта величина максимальной размерности таблицы требует включения смещения 16 бит, которое хранится как предел в соответствующих программно-доступных регистрах GDTR и IDTR, и теневом – (LDTR). Элементы в дескрипторных таблицах размещаются последовательно по 8 байт и для их поиска достаточно задать 13-разрядный индекс. Индекс сегмента передается в старшие разряды 16-битного селектора сегмента. В 2 младших бита (0,1) RPL селектора заносится код привилегий, а третьему биту Т1 присваивается 1, если селектор обращается к LDT и 0 – при обращении к GDT. Перед выполнением команды используемый ею дескриптор должен быть определен, а его селектор занесен в один из регистров CS, SS, DS, ES, FS, GS. В процессе распределения памяти операционная система заносит ЛА в регистры GDTR и IDTR: в младшие 32 бита базовые адреса таблиц, а в старшие 16 разрядов – размер этих таблиц, которые не изменяются при постоянном числе задач, фигурирующих в компьютере.
Изменить организацию сегментов системный программист может для своих прикладных задач с помощью таблицы LDT. В этой таблице он создает дескрипторы сегментов, доступ к которым осуществляется теми же селекторами в регистрах CS, ..., GS, но у которых бит Т1 установлен в 1. При этом дескрипторы LDT автоматически с загрузкой селекторов считываются в теневые регистры (CS), ..., (GS) с использованием базы теневого регистра (LDTR). База и предел в 48-разрядный теневой регистр (LDTR) передается из GDT, в которой размещается по индексу селектора регистра LDTR специальный дескриптор.
На рис. 3.13 показан процесс вычисления линейного адреса в устройстве сегментации i486. Он осуществляется следующим образом. Перед началом решения задачи операционной системой формируются таблицы GDT и IDT и их адреса загружаются в регистры GDTR и IDTR. При необходимости специальными командами программист заносит селекторы в сегментные регистры CS, ..., GS, а системной программой устанавливает селектор в LDTR для чтения созданной им локальной дескрипторной таблицы. В пользовательской программе очередная команда обрабатывается устройством предвыборки команд. В соответствии с кодом операции (КОП) для выполнения команды, операнд которой находится в памяти, к ней подключается один из сегментных регистров CS, ..., GS и соответствующий ему теневой регистр (CS), ..., (GS). Базовый адрес теневого регистра и эффективный адрес (ЕА) в соответствии с типом команды суммируются в SM по модулю 232 по схеме рис. 3.13. В результате определяется линейный адрес операнда. Процессор, используя атрибуты дескриптора, пределы регистров таблиц, контролирует права доступа к сегменту и правильность выполнения команды.
Рис. 3.13. Схема вычисления адреса в устройстве сегментации
При отсутствии нарушений (см. рис. 1.5) линейный адрес передается на адресную шину (через устройство страничного преобразования в Р-режиме) ША для извлечения операнда из кэш-памяти или ОЗУ.
При определении нарушений в i486 задействуется регистр IDTR с таблицей прерывания IDT и программа формирования соответствующих инструкций.
Рассмотренная схема вычисления адреса позволяет обращаться к сегментам, распределенным в любой области линейного пространства от 0 до 4Г-1, с точностью до байта, т.к. базовый адрес сегмента Вс может иметь любой 32-разрядный код. Величина сегмента при G = 0 составляет не более одного Мб, а при G = 1 охватывает всю область линейного пространства. Смещение в команде определяет расстояние от базового адреса до ячейки в сторону увеличения адресов в сегментах данных и кода.
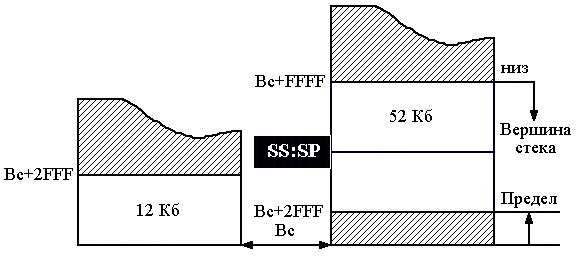
В сегментах стека используется принцип записи "последним пришел, первым обслужился". Базовый адрес вместе с максимальной величиной ESP/SP (низ стека) ограничивают сегмент сверху. При каждой записи указатель стека декрементируется, а при считывании инкрементируется. Если бит D и G дескриптора = 1, то используется ESP и обмен идет 32-разрядными словами, тогда низ стека устанавливается адресом Вс+4Г-1. При D=0 в стековых операциях участвует SP и SS, где хранится Вс. Тогда низ стека устанавливается адресом SS :FFFFh. При обращении к ячейкам стека допустимы все смещения, которые больше предела, но меньше максимального размера, а при обращении к ячейкам сегментов кода и данных все смещения меньше предела.
На рис. 3.14. показаны незаштрихованные рабочие области для сегментов кода и данных (а) и сегмента стека (б), имеющие D = 0, одинаковую базу Вс и предел 2FFFh.
а б
Рис. 3.14. Рабочие области сегментов: а – рабочие области для сегментов кода и данных, б – рабочие области для сегмента стека