4.1. Если адрес каждой записи легко и однозначно вычисляется по значению первичного ключа, то возможен прямой доступ к нужной записи по заданному значению ключа. Однако этот способ встречается редко и применим для относительно небольших файлов.
4.2. Метод бинарного поиска основан на делении интервала по иска пополам, при условии, что записи в файле упорядочены по значению соответствующего ключа. Сравнивают значение ключа средней по месторасположению записи о искомым значением К=а , выбирают нужную половину файла и процесс повторяют, пока не будет найдена нужная запись, либо пока в интервале не останется всего одна запись В последнем случае , если значение ключа последней записи не удовлетворяет условию поиска, то поиск неудачный и искомой записи в файле нет.
Бинарный поиск можно выполнять, работая с блоками файла, а не с записями. При считывании выбранного блока в оперативную память поиск записи в нем может быть последовательным. В этом случае в качестве характеристик блока используются граничные значения ключей записей блока.
Если поиск ведется по интервалу значений ключей а < к < b то вначале выполняется бинарный поиск записи, удовлетворяющей условию ki = a, либо (если такой записи нет в файле) наиболее близкой по ki к значению а по условию а < Кi. Далее последовательно читаются записи в блоках файла до тех пор, пока не будет нарушено условие ki<b.
4.3. Поиск в хешированных файлах ведется СУБД с помощью про граммы хеширования и эффективность такого поиска определяется равномерностью распределения записей по блокам файла, которая, в свою очередь, зависит от равномерности значений ключей в записях файла, от свойств хеш-функции и схемы разрешения коллизий. Такая хешированная (перемешанная) организация файла эффективна при по иске записей по отдельному ключу, однако не позволяет производить поиск по интервалу значений ключа.
4.4. Индексирование состоит в том, что СУБД, размещая записи в блоках (страницах) данных, формирует специальные индексные таблицы. Они используются для нахождения адреса записи по значению первичного ключа. При использовании индексирования по первичному ключу (первичное индексирование) необходимо выполнять требования:
1) ключ индексирования должен иметь уникальные и неизменяемые значения;
2) первоначальная загрузка записей должна выполняться обязательно с предварительной сортировкой;
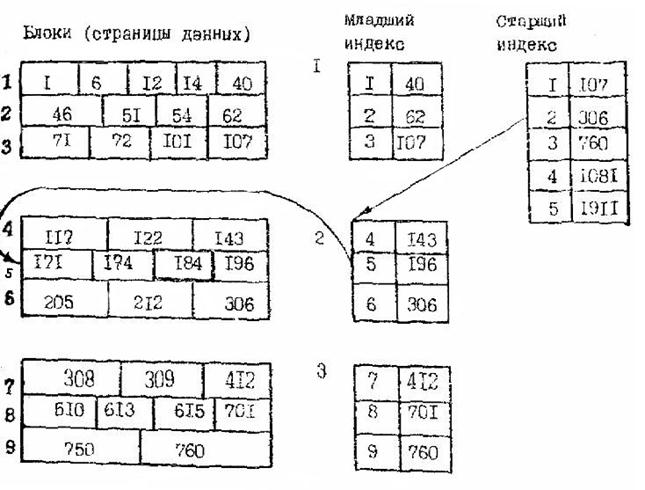
3) формирование индексных таблиц происходит одновременно с за грузкой записей в файл, а значения ключа индексирования влияют на размещение записей в памяти ЭВМ. Рассмотрим типичный пример механизма индексирования. Пусть записи имеют ключи со значением из натурального ряда. В файл будут загружаться записи, упорядоченные по возрастанию значений ключей, плотно заполняя блоки данных. После заполнения блока СУБД формирует одну строку в таблице, называемой младшим индексом. Эта строка устанавливает соответствие между номером блока и максимальным ключом в этом блоке (рис. 12.1). Таблица младшего индекса создается на определенную совокупность блоков данных, поэтому по мере заполнения файла будет создано много таблиц младшего индекса жаждая из них имеет уникальный номер.
После заполнения всех блоков, обслуживаемых одним младшим индексом, система формирует строку в таблице, называемой старшим индексом. Здесь строка устанавливает соответствие между номером таблицы младшего индекса и максимальным ключом в этом младшем индексе. Для файлов больших объемов возможно создание еще нескольких уровней индексирования (главный индекс, гипериндекс и т.д.).
На рис. 12.1 линией показана последовательность поиска записи заданным значением первичного ключа (184).
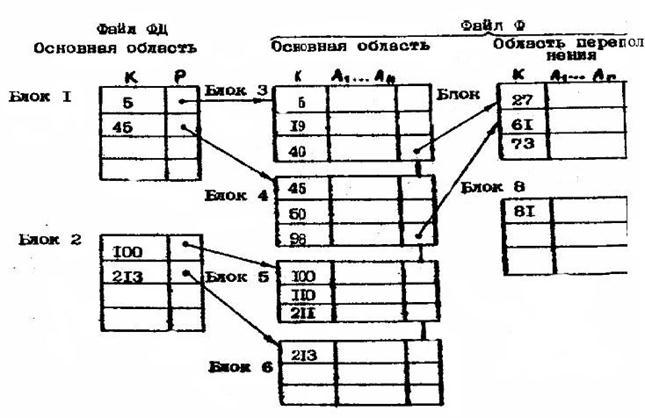
Частным случаем индексирования является использование "не плотного индекса", т.е. специального дополнительного индексного файла.
Пусть основной файл Ф упорядочен по полю ключа К . Построим дополнительный файл (рис. 12.2) по правилу: 1) записи файла ФД содержат два поля, в которых содержатся значение ключа пер вой записи блока файла Ф и значение указателя ( Р ) на этот блок 2) записи файла ФД упорядочены по полю К. .
Рис.12.1. Пример заполнения и использования индексных таблиц
Полученный файл ФД называется неплотным индексом. Количество записей файла ФД равно количеству блоков основного файла Ф. Для организации файла Яд требуется дополнительная внешняя память.
Поиск вначале выполняется в индексе для нахождения адреса блока основного файла, а затем этот блок считывается в оперативную память и в нем, например, с помощью последовательного поиска определяется требуемая запись. Другой разновидностью индексирования является использование "плотного индекса". Если основной файл не упорядочен по ключу К, а записи дополнительного файла ФД упорядочены по ключу К ( и аналогично состоят из двух полей К, Р), то в этом случае файл ФД называется плотным индексом.
Различие между плотным и неплотным индексом заключается в том, что для каждого значения ключа К в плотном индексе (файле ФД) имеется отдельная запись, а в неплотном индексе - только для значения ключа первой записи блока. 4.5.