Имеется массив данных: 34, 17, 45, 9, 6, 18, 12, 14, 37, 49, 5. Его необходимо отсортировать по возрастанию (табл. 13.1). Разобьём для этого массив на две части и выберем элемент x равный 18. Выберем из левой части первый элемент, который больше 18 – это 34, а из правой части элемент, который меньше 18 – это 5. Поменяем их местами и получим новую последовательность: 5, 17, 45, 9, 6, 18, 12, 14, 37, 49, 34. Далее процесс повторяется (см. Таблицу 13.1).
Таблица 13.1
Пример работы быстрой сортировки на примере
Шаг
Последовательность элементов
X
Меняем
34, 17, 45, 9, 6, 18, 12, 14, 37, 49, 5
34 и 5
5, 17, 45, 9, 6, 18, 12, 14, 37, 49, 34
45 и 14
5, 17, 14, 9, 6, 18, 12, 45, 37, 49, 34
5, 17, 14, 9, 6, 12, 18, 45, 37, 49, 34
17 и 12
5, 12, 14, 9, 6, 17, 18, 45, 37, 49, 34
5, 12, 6, 14, 9, 17, 18, 45, 37, 49, 34
5, 12, 6, 9, 14, 17, 18, 45, 37, 49, 34
5, 9, 12, 6, 14, 17, 18, 45, 37, 49, 34
5, 9, 6, 12, 14, 17, 18, 45, 37, 49, 34
5, 6, 9, 12, 14, 17, 18, 45, 37, 49, 34
5, 37
-, 45 и 34
5, 6, 9, 12, 14, 17, 18, 34, 37, 49, 45
5, 6, 9, 12, 14, 17, 18, 34, 37, 45, 49
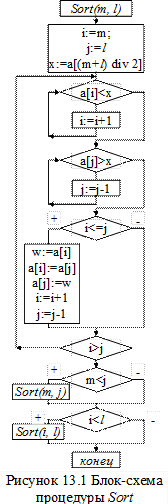
Если индекс выбранного x равен i, то он делит массив сначала на две части: 1) a[1],....,a[i-1] и 2) a[j+1],...,a[n], где j = i+1 для текущего случая. Потом разделение аналогичным образом повторяется. Описанные ниже блок-схемами алгоритмы просты и эффективны, так как сравниваемые переменные i, j и x можно хранить во время просмотра в быстрых регистрах процессора. Здесь применяется процесс разделения к получившимся двум частям, затем к частям частей, и так далее до тех пор, пока каждая из частей не будет состоять из одного единственного элемента. Процедура sort реализует разделение массива на две части, и рекурсивно обращается сама к себе (рис. 13.1). Данная процедура sort(m,l) описывается и вызывается в процедуре hoarsort (рис. 13.2), которая потом вызывается в программе таким образом: hoarsort(b, n), где b – это отсортированный массив, а – это число элементов в массиве.
Существуют и другие способы реализации процедуры sort(m,l), которые могут значительно сократить код программы и уменьшить число используемых переменных.
Улучшенные методы сортировки. Сортировка шелла. Её эффективность.
Сортировка шелла базируется на алгоритме прямой вставки. Исходный массив своеобразным образом разбивается на части, которые и сортируются многократно алгоритмом прямого включения. Эти разбиения помогают сократить количество перестановок, так как чтобы освободить нужное место для очередного элемента, необходимо сдвигать меньше элементов.
Принцип работы сортировки шелла и необходимые расчёты для её реализации
Необходимо на каждом шаге произвести определённые действия, если t – это переменная, которая хранит номер этого шага. Сначала определяются все подпоследовательности, в которых расстояния между элементами равно kt. Далее каждая из этих подпоследовательностей сортируется методом прямого включения.
Сложным и важным местом данного алгоритма является нахождение убывающей последовательности расстояний kt, kt-1..., k1. Она должна обладать определёнными свойствами:
1) k1 = 1;
2) kt > kt-1для всех t;
3) kt не должны быть кратными друг другу (это для того, чтобы не повторялась обработка ранее отсортированных элементов).
Дональд кнут предложил две последовательности расстояний:
Первая последовательность расстояний подходит для сортировок достаточно длинных массивов, а вторая подходит для коротких массивов.
Пример расчёта последовательности расстояний для малых массивов
Для удачного подбора значений необходимо, чтобы длина массива n попадала в такие границы
Kt <= n -1 < kt+1 или 2t <= n < 2t+1. (14.1).
Если прологарифмировать (14.1) по основанию 2, то можно получить следующее уравнение:
T <= log n < t+1. (14.2).
Далее из (14.2) получаем:
T = trunc(log n). (14.3).
Если используется язык программирования, в котором можно логарифмировать только по основанию е (натуральный логарифм), то необходимо применить знакомое из курса средней школы правило «превращения» логарифмов: logmx =logzx/logzm, где в нашем случае m = 2, z = e. Тогда выражение (14.3) будет иметь вид:
T= trunc(ln(n)/ln(2)). (14.4)
Если посчитать t по формулам (12.3), (12.4), то часть подпоследовательностей будет иметь длину 2, а часть – и вовсе 1. Сортировать такие подпоследовательности незачем, поэтому стоит сразу же отступить еще на 1 шаг. Тогда, можно записать окончательное выражение для числа шагов:
T= trunc(ln(n)/ln(2))-1. (14.5)
Тогда расстояние между элементами, т.е. Шаг, в любой подпоследовательности вычисляем таким образом:
K= 2t-1 или k= (1 shl t)-1. (14.6)
Количество подпоследовательностей, которые необходимо будет отсортировать прямой вставкой, для рассматриваемого шага будет равна k.
Далее необходимо определить, сколько элементов будет входить в каждую подпоследовательность. Если длину всей сортируемой последовательности n можно разделить на шаг k без остатка, тогда все подпоследовательности будут иметь одинаковую длину, а именно
S = n div k. (14.7)
Если же n не делится на шаг k нацело, то первые р подпоследовательностей будут длиннее на единицу. Количество таких подпоследовательностей равно остатку от деления n на шаг k: