6.1. Кластерный анализ структуры многомерных данных.
6.1.1. Основные понятия кластерного анализа.
Кластерный анализ предназначен для разбиения множества объектов на заданное или неизвестное число классов на основании некоторого математического критерия качества классификации.
Кластеризация – это автоматическое разбиение элементов некоторого множества на группы (кластеры) по принципу схожести. Характеристики групп определяются только фактическим результатом.
Классификация относит каждый объект к одной из заранее определенных групп.
Пусть = (x1, …, xn) – вектор характеристик (объект), где n – размерность пространства характеристик.
Множество объектов M = {} – набор входных данных.
Расстояние d(, ) между объектами и – результат применения выбранной метрики в пространстве характеристик.
Кластер – подмножество «близких друг к другу» (с малым расстоянием) объектов из M.
Расстояние между группами объектов измеряется различными способами.
Пусть wi – i-я группа объектов (кластер);
Ni – число объектов, образующих группу wi;
mi – «центр масс» i-й группы (среднее арифметическое координат объектов, входящих в wi);
q (ws, wm) – расстояние между группами ws и wm
Способы измерения расстояний между кластерами:
Расстояние ближайшего соседа – расстояние между ближайшими объектами кластеров
Расстояние дальнего соседа – расстояние между самыми дальними объектами кластеров
Расстояние центров тяжести – расстояние между центральными точками кластеров
Выбор меры расстояния между кластерами влияет на вид выделяемых геометрических группировок объектов в пространстве признаков. Алгоритмы, основанные на расстоянии ближайшего соседа, хорошо работают в случае группировок, имеющих сложную (например, цепочечную) структуру. Расстояние дальнего соседа применяется, когда искомые группировки образуют в пространстве признаков шаровидные облака. Алгоритмы, использующие расстояние центров тяжести, лучше всего работают в случае группировок эллипсоидной формы.
Критерий качества кластеризации должен отражать следующие неформальные требования:
а) внутри групп объекты должны быть тесно связаны между собой;
б) объекты разных групп должны быть далеки друг от друга;
в) при прочих равных условиях распределения объектов по группам должны быть равномерными.
Требования а) и б) выражают стандартную концепцию компактности классов разбиения; требование в) состоит в том, чтобы критерий не навязывал объединения отдельных групп объектов.
Примеры критериев качества кластеризации:
Среднее арифметическое расстояние между объектами и центрами их кластеров
,
где – объект (k = 1…K);
K – количество объектов;
– центр кластера, в который входит объект .
i – номер координаты (i = 1…n);
n – размерность пространства признаков.
Среднеквадратическое расстояние между объектами и центрами их кластеров
.
6.1.2. Общая схема кластеризации.
Этапы:
Выделение характеристик объектов;
Выбор метрики;
Выбор метода кластеризации и разбиение объектов на группы;
Представление результатов.
Выделение характеристик:
Выбор свойств, характеризующих объекты (количественные и качественные характеристики);
Нормализация характеристик (приведение к единой шкале);
Представление объектов в виде характеристических векторов.
Выбор метрики
Метрика выбирается в зависимости от пространства, где расположены объекты. Если все координаты объекта непрерывны и вещественны, то используется метрика Евклида:
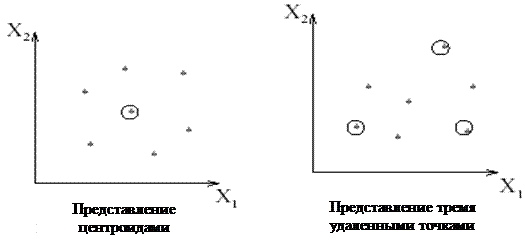
Представление результатов
Обычно используется один из следующих способов представления кластеров:
1. Центроидами;
2. Набором характерных точек;
3. Ограничениями кластеров.
6.1.3. Методы кластеризации.
Алгоритм k-средних (k-Means)
Выбрать k точек, являющихся начальными «центрами масс» кластеров (любые k из n объектов или вообще k случайных точек);
Отнести каждый объект к кластеру с ближайшим «центром масс»;
Пересчитать «центры масс» кластеров согласно текущему членству;
Если критерий остановки алгоритма не удовлетворен, вернуться к шагу 2.
Критерии остановки:
Отсутствие перехода объектов из кластера в кластер на шаге 2;
Минимальное изменение среднеквадратической ошибки.
Достоинства: алгоритм быстро работает и прост в реализации.
Недостатки:
- алгоритм создает только кластеры, похожие на гиперсферы;
- алгоритм чувствителен к начальному выбору «центров масс».
Наибольшее распространение получили агломеративные процедуры, основанные на последовательном объединении кластеров (разбиение «снизу-вверх»).
На первом шаге все объекты считаются отдельными кластерами. На каждом последующем шаге два ближайших кластера объединяются в один. Каждое объединение уменьшает число кластеров на один так, что в конце концов все объекты объединяются в один кластер. В результате образуется дендрограмма, отображающая результаты группирования объектов на всех шагах алгоритма.
Вид дендрограммы зависит от выбранного способа измерения расстояний между кластерами.
Достоинства: возможность проследить процесс выделения группировок и иллюстрация соподчиненности кластеров.
Недостаток: квадратичная трудоемкость.
Минимальное покрывающее дерево
Позволяет производить иерархическую кластеризацию «сверху-вниз».
Объекты представляются вершинами связного неориентированного графа с взвешенными ребрами, где вес ребер – это их длина (расстояние между объектами). Нужно удалить ребра как можно большей суммарной длины, оставив граф связным. При этом получается дерево с минимальной суммарной длиной ребер.
Алгоритм Прима:
Выбирается произвольная вершина. Она образует начальное дерево.
Измеряется расстояние от нее до всех других вершин.
До тех пор пока в дерево не добавлены все вершины:
3.1. Найти ближайшую вершину, с минимальным расстоянием до дерева;
3.2. Добавить ее к дереву;
3.3. Пересчитать расстояния от вершин до дерева: если расстояние до какой-либо вершины из новой вершины меньше текущего расстояния от дерева, то старое расстояние от дерева заменить новым.
Разбить объекты на заданное число кластеров в соответствии с максимальными длинами ветвей дерева.
Метод ближайшего соседа
Пока существуют объекты вне кластеров:
Для каждого такого объекта выбрать ближайшего соседа, кластер которого определен, и если расстояние до этого соседа меньше порога – отнести его в тот же кластер, иначе можно создать новый кластер;
Увеличить порог при необходимости.
Достоинство: простота.
Недостаток: низкая эффективность.
Нечеткая кластеризация
Непересекающаяся (четкая) кластеризация относит объект только к одному кластеру.
Нечеткая кластеризация считает для каждого объекта xi степень его принадлежности uik к каждому из k кластеров.
Схема нечеткой кластеризации:
Выбрать начальное нечеткое разбиение N объектов на K кластеров путем выбора матрицы принадлежности U размера N x K (обычно uik Î [0;1]);
Используя матрицу U, найти значение критерия нечеткой ошибки. Например,
Перегруппировать объекты с целью уменьшения ошибки.
Повторять шаг 2, пока матрица U меняется.
Достоинства:
Отсутствие необходимости в априорных предположениях относительно структуры данных (вид и параметры распределения вероятности по кластерам, центров плотности);
Отсутствие ограничений на геометрию кластеров;
Время выполнения алгоритма мало зависит от числа компонент входных векторов.
Недостаток: большое время выполнения алгоритма, характеризуемое порядком от числа элементов.
6.2. Метод потенциальных функций.
Пусть требуется разделить два непересекающихся образа V1 и V2. Это значит, что нужно найти функцию положительную в точках образа V1 и отрицательную в точках образа V2.
В процессе обучения с каждой точкой обучающей последовательности связывается потенциальная функция (по аналогии с потенциалом электрического поля вокруг точечного электрического заряда, который убывает при удалении от заряда). Если поле образовано несколькими зарядами, то потенциал в каждой точке этого поля равен сумме потенциалов зарядов. Если заряды расположены компактной группой, то потенциал будет максимальным внутри группы. Тогда могут быть построены потенциальные функции для каждого образа:
, .
В качестве разделяющей функции можно выбрать функцию вида
.
Примеры потенциальных функций:
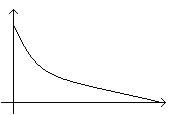
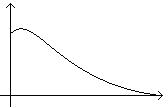
;
где α – параметр функции;
– расстояние между объектами.
В процессе обучения предъявляется обучающая последовательность и на каждом n-м такте обучения строится приближение по следующей процедуре:
;
где l – положительная константа.
Процесс обучения останавливается, когда перестает меняться.
6.3. Метод предельных упрощений.
Метод использует подход, при котором, в отличие от построения сложных разделяющих поверхностей в заданных пространствах признаков, формируется такое пространство, в котором процесс распознавания очень прост.
В методе предельных упрощений предполагается, что разделяющая функция задается заранее в виде линейного полинома, а процесс обучения состоит в конструировании такого пространства минимальной размерности, в котором эта функция правильно разделяет обучающую последовательность. Алгоритм построения такого пространства предполагает последовательный отбор тех свойств объектов, которые позволяют правильно решить большинство обучающих примеров. Такой отбор признаков продолжается до тех пор, пока не наступит безошибочное линейное разделение образов на обучающей последовательности.
Для разделения образов выбирается гиперплоскость, описываемая уравнением
или , где xi – i-й признак.
6.4. Коллективы решающих правил.
Этот подход объединяет различные алгоритмы для решения задач распознавания.
Пусть в некоторой ситуации Х принимается решение S. Тогда S = R(X), где R – алгоритм принятия решения в ситуации X. Пусть существует L различных алгоритмов решения задачи, т. е. Sl = Rl(X), где l = 1, ..., L; Sl – решение, полученное алгоритмом Rl.
Множество алгоритмов {R} = {R1, R2, ..., RL} называется коллективом алгоритмов решения задачи (коллективом решающих правил), если на множестве решений Sl в любой ситуации Х определено решающее правило F, т. е. S = F(S1, S2, ..., SL, X). Алгоритмы Rl называются членами коллектива, Sl – решение l-го члена коллектива, а S – коллективное решение. Функция F определяет способ обобщения индивидуальных решений для получения решения коллектива S.
Выбор правила осуществляется взвешиваньем его компетентности в решаемой задаче. Например, вес решающего правила Rl может определяться соотношением
где Bl – область компетентности решающего правила Rl.
Веса решающих правил выбираются так, что для всех возможных значений X.
Такой подход представляет собой двухуровневую процедуру распознавания: на первом уровне определяется принадлежность образа той или иной области компетентности, а на втором – вступает в силу решающее правило, компетентность которого максимальна в найденной области.
6.5. Метод группового учета аргументов.
Алгоритмы МГУА воспроизводят схему массовой селекции.
Так называемое «полное» описание объекта y = F(x1, x2, ¼,xm), где F – некоторая функция (например, степенной полином) заменяется несколькими рядами «частных» описаний:
где f – некоторая простая функция (например, квадратичная форма);
s = c2, p = cs2 и т.д., с – увеличение поля.
Каждое частное описание является функцией только двух переменных. Поэтому коэффициенты такого регрессионного уравнения легко определяются даже по небольшому числу наблюдений обучающей последовательности методом наименьших квадратов.
Входные аргументы и промежуточные переменные сопрягаются попарно, и сложность комбинаций на каждом ряду обработки информации возрастает. Общая результирующая сложность модели зависит вида частного описания f и количества рядов селекции.
Из ряда в ряд селекции пропускается только некоторое количество самых регулярных (качественных) частных описаний. Степень регулярности оценивается по величине среднеквадратичной ошибки на отдельной проверочной последовательности данных. Ряды селекции наращиваются до тех пор, пока регулярность повышается.

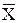 = (x1, …, xn) – вектор характеристик (объект), где n – размерность пространства характеристик.
= (x1, …, xn) – вектор характеристик (объект), где n – размерность пространства характеристик.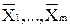 } – набор входных данных.
} – набор входных данных.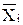 ,
, 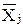 ) между объектами
) между объектами 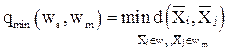

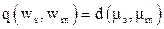
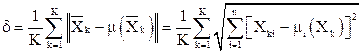 ,
,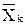 – объект (k = 1…K);
– объект (k = 1…K);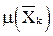 – центр кластера, в который входит объект
– центр кластера, в который входит объект 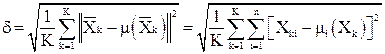 .
.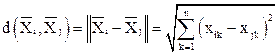
 Ограничениями кластеров.
Ограничениями кластеров.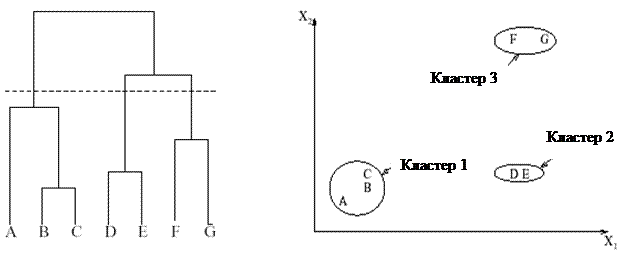 Недостаток: квадратичная трудоемкость.
Недостаток: квадратичная трудоемкость.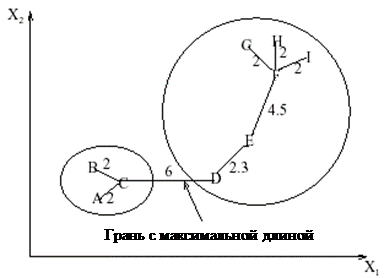 Добавить ее к дереву;
Добавить ее к дереву;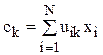
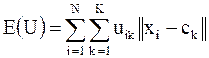
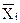 связывается потенциальная функция
связывается потенциальная функция  (по аналогии с потенциалом электрического поля вокруг точечного электрического заряда, который убывает при удалении от заряда). Если поле образовано несколькими зарядами, то потенциал в каждой точке этого поля равен сумме потенциалов зарядов. Если заряды расположены компактной группой, то потенциал будет максимальным внутри группы. Тогда могут быть построены потенциальные функции для каждого образа:
(по аналогии с потенциалом электрического поля вокруг точечного электрического заряда, который убывает при удалении от заряда). Если поле образовано несколькими зарядами, то потенциал в каждой точке этого поля равен сумме потенциалов зарядов. Если заряды расположены компактной группой, то потенциал будет максимальным внутри группы. Тогда могут быть построены потенциальные функции для каждого образа: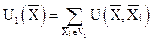 ,
, 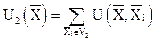 .
.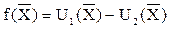 .
.
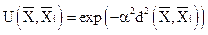 ;
; 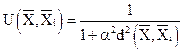
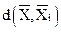 – расстояние между объектами.
– расстояние между объектами. по следующей процедуре:
по следующей процедуре: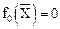 ;
; 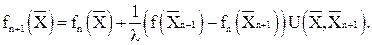
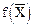 перестает меняться.
перестает меняться.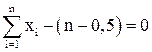 или
или 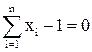 , где xi – i-й признак.
, где xi – i-й признак.
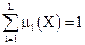 для всех возможных значений X.
для всех возможных значений X.