Принцип обобщения для нечетких множеств представляет собой в сущности основное равенство, позволяющее расширить область определения U отображения или отношения, включив в неё наряду с точками произвольные нечеткие подмножества множества U. Более конкретно, предположим, что f – отображение , а А – нечеткое подмножество вида: .
Тогда принцип обобщения утверждает, что
Итак, образ множества А при отображении f можно получить, зная образы элементов u1….un при этом отображении.
Если носитель подмножества А имеет мощность континуума, т.е.
То принцип обобщения принимает следующий вид:
при этом необходимо учитывать, что f(u) – точка множества V, а - степень принадлежности f(u) нечеткому подмножеству f(A) множества V.
Во многих приложениях принципа обобщения возникает следующая проблема. Имеется функция n переменных f : и нечеткое множество (отношение) А в , характеризующееся функцией принадлежности , где , i = 1, …n.
Непосредственное применение в этом случае принципа обобщения дает
Однако во многих случаях нам известно не само множество А, а его проекции А1…Аn на U1,…, Un соответственно. В связи с этим возникает вопрос: какое выражение для , следует использовать в (*).
В таких случаях будем предполагать, что функция принадлежности А имеет вид
где - функция принадлежности отношения Ai.
В зависимости от выбора различных существенных черт системы (элементов и связей между ними)можно получать различные модели, описывающие с различных точек зрения реальную систему.
В настоящее время используются следующие уровни описания систем:
1) лингвистический (в том числе – логико-математический);
2) теоретико-множественный (в том числе – абстрактно-алгебраический, топологический);
3) динамический.
Лингвистический уровень – наиболее высокий уровень абстрагирования. Наиболее детально разработано представление моделей на теоретико-множественном и динамическом уровнях.
В общем случае модель S на теоретико-множественном уровне задается в виде кортежа *:
Компонентами которого являются множество элементов А1,…Аn, образующих систему, и определенные на этом множестве отношения между элементами системы R1,…Rmиз представления моделей (1.1)видно, что компоненты А1,…Аn представляют некоторую “опорную информацию”, положенную в построение моделей. Только выделив «опорные» точки можно приступать к заданию отношений на множестве А1, А2,….Аn.
Кортеж – последовательность элементов, в которой каждый элемент занимает определенное место.
Система может характеризоваться различными отношениями между множествами объектов. В связи с этим математической моделью системы назовем кортеж: , (*).
Компонентами которого являются семейство множеств (объектов) М1, М2….Мn, образующих систему, и определенные на этом семействе множеств отношения R1, R2,…Rm, каждое из которых определяется или как бинарное отношение на семействе множеств, или как отношение размерности к, .
Каждой комбинации отношений будет соответствовать своя модель системы.
Если кортеж (*) имеет одно отношение, то модель отображает какую-либо одну сторону – один аспект системы.
В многоаспектной модели принимается во внимание множество отношений.
Кортеж (*), который мы назвали математической моделью системы, иногда будем называть просто – системой.
Воздействие среды на систему характеризуется некоторыми параметрами или показателями, которые называются входными параметрами (входами, факторами). Множество входов может быть представлено кортежем: Х=(Х1, Х2, …Хr).
Входы преобразуются системой в параметры, которые характеризуют результаты проводимых системой операций. Эти параметры – выходные: у= (у1, у2,…уs).
Система преобразует входы в выходы благодаря некоторому отношению R: .
Тогда моделью системы «вход-выход» будет тройка: S = (x, y, R)
Отношение может быть функциональным: y = F(x), тогда модель будет иметь вид: S = (x, y, F).
Эти модели соответствуют случаям, когда система имеет единственное состояние и параметры выходов совпадают с параметрами состояния.
В более общем случае вход системы определяет параметры её состояния: Z = (Z1, Z2,…Zn).
через отношениеили через функцию Z = F(x)
Выходные системы определяются бинарным отношением между параметрами вход-состояние и выход или функционально y = G(x,Z).
В этом случае модели системы определяются пятерками: S = (x, Z, y, R1, R2) или S = (x, Z, y, F, G).
При описании системы в виде конечного автомата: ,
где G, X, Y, - конечные множества, называемые соответственно множеством внутренних состояний, множеством входных сигналов и множеством выходных сигналов, а и - однозначные функции:
- функция переходов,
- функция выходов, опорная информация определяется множествами состояний, входов и выходов.
Из рассмотрения различных вариантов представления опорной информации можно сделать вывод, что построение моделей фактически сводится к выражению существенных черт системы на определенном специальном языке. Такой языковый аспект построения моделей требует различать семантическую и синтаксическую сторону моделей /17/. Семантика – раздел семиотики: науки о знаковых системах, посвященный изучению отношений между знаками и обозначаемыми ими объектами, т.е. смысловому содержанию знаковых выражений. Синтактика – раздел семиотики, связанный с исследованием отношений между знаками. Таким образом, семантика модели есть ее содержание, её смысл, т.е. все то, что определяет сходство модели с оригиналом. Если тот, кто использует модель, не имеет доступа к связанной с ней семантике, то он не может и правильно интерпретировать модель. Синтаксис модели – есть совокупность формальных вспомогательных средств модели для представления её опорной информации и её основных отношений. Для представления любой модели необходимы основные синтаксические элементы и их соединения. Основными синтаксическими элементами являются знаки. В зависимости от выбранной системы знаков (а также от выбранного вида представления отношений) модели можно задавать в символическойили иконографической форме.
Естественно, что на разных уровнях моделей (лингвистическом, теоретико-множественном, динамическом)используется различная опорная информация. Так, на лингвистическом уровне абстрактного описания система определяется как множество правильных высказываний /4/. Все высказывания делят обычно на два типа. К первому причисляются термы имена предметов, члены предложений и т.д./, с помощью которых обозначают объекты исследования/, а ко второму – функторы, определяющие отношения между системами. С помощью термов и функторов лингвистическое описание моделей также может быть представлено в виде I.I. Причем роль опорной информации играют термы.

 , а А – нечеткое подмножество вида:
, а А – нечеткое подмножество вида:  .
.



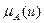 - степень принадлежности f(u) нечеткому подмножеству f(A) множества V.
- степень принадлежности f(u) нечеткому подмножеству f(A) множества V.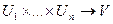 и нечеткое множество (отношение) А в
и нечеткое множество (отношение) А в  , характеризующееся функцией принадлежности
, характеризующееся функцией принадлежности  , где
, где  , i = 1, …n.
, i = 1, …n.
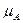 , следует использовать в (*).
, следует использовать в (*).
 - функция принадлежности отношения Ai.
- функция принадлежности отношения Ai.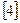

 , (*).
, (*). .
. .
. или через функцию Z = F(x)
или через функцию Z = F(x) или функционально y = G(x,Z).
или функционально y = G(x,Z). ,
, и
и 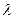 - однозначные функции:
- однозначные функции: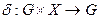 - функция переходов,
- функция переходов, - функция выходов, опорная информация определяется множествами состояний, входов и выходов.
- функция выходов, опорная информация определяется множествами состояний, входов и выходов.