Приклад 6.5.:
/*strcmpi.cpp*/
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
main(int argc, char *argv[])
{
char *p;
if (argv <= 2)
{
puts(“Введіть дві стрічки, що порівнюються без урахування різниці між стрічковими і прописними літерами”);
puts(“Наприклад, STRCMPI стрічкаа стрічкаб”);
exit(1);
}
int result = strcmpi(argv[1], argv[2]);
if (result < 0)
p = ”менше”;
else if (result > 0)
p = “більше”;
else
p = “дорівнює”;
printf(“%s %s %s”, argv[1], p, argv[2]);
return 0;
}
Функція strcpy() -копіює вихідну стрічку src і завершуючий її нульовий символ у стрічку результату dst, перезаписуючи символи результуючої стрічки, розташовані в місці копіювання. Повертає dest.(string.h)
Синтаксис: char *strcpy(char *dest,const char *src);
char far * far _fstrcpy(char far *dest, const char far *src);
Параметри:
- char *dest - вказівник на стрічку результату, що перезаписується вихідною стрічкою. Результуюча стрічка не обов'язково повинна бути ініціалізованною.
- const char *src - вказівник на вихідну стрічку, що завершується нульовим символом.
Функція аналогічна до stpcpy(), strncpy()
Приклад 6.6.:
/*strcpy.cpp*/
#include<stdio.h>
#include<string.h>
main()
{
char src[80] = “abcdefghij”;
char dst[80] = “1234567890”;
puts(“Викликаємо strcpy(приймач, джерело)”);
strcpy(dst, src);
printf(“Gіckz^ l;thtkj==%s ghbqvfx==%s\n”? src? dst);
return 0;
}
Функція strdate()-запам'ятовує поточну дату у вигляді стрічки у форматі mm/dd/yy(mm – місяць, dd – день, yy – рік. Повертає datestr,(time.h)
Синтаксис: char *_strdate(cha *datestr);
Параметри:
- char *datestr - вказівник на результуючу стрічку довжиною принаймні 9 байтів.
Функція аналогічна до asctime(), ctime(), strtime(), time()
Приклад 6.7.:
/*_strdate.cpp*/
#include<stdio.h>
#include<time.h>
main()
{
char sdate[9];
_strdate(sdate);
printf(“: %s\n”, sdate);
return 0;}
Функціяstrerror()-створює зі стрічки s стрічку повідомлення про помилку, додаючи двокрапку, пробіл і опис поточної системної помилки (string.hчи stdio.h).
Синтаксис: char *_strerror(const char *s);
Параметри:
- const char *s - повідомлення користувача про помилку довжиною не більше 94 символів, до якого додається повідомлення про системну помилку. Якщо цей вказівник дорівнює нулю, _strerror() повертає вказівник на стрічку повідомлення про помилку із самим останнім кодом помилки.
Функція аналогічна до perror(), strerror()
Приклад 6.8.:
#include<stdio.h>
#include<string.h>
main()
{
char *p = _strerror(“Перевірочне повідомлення про помилку”);
printf(“Повідомлення про помилку == %s\n”, p);
p = _strerror(NULL);
printf(“Сама остання помилка == %s\n”, p);
return 0;
}
Функція strftime()-форматує дату і час у вигляді текстової стрічки, використовуючи систему правил перетворення, аналогічну системі printf(). Форматна стрічка fmt містить одне чи декілька правил, що заміняються компонентами дати і часу. Крім того, форматна стрічка може також містити й інші символи, що не відносяться до правил перетворення. Повертає число символів, записаних у результуючу стрічку(time.h). Правило перетворення складається зі знака відсотка (%) і символу.
| Таблиця 6.2 - Правила перетворення для strftime()
|
| Правила перетворення
| Компоненти дати і часу
|
| %
| Вставити знак відсотка (%)
|
| A
| День тижня (абревіатура: Sun, Mon і т.д.)
|
| A
| Повна назва дня тижня
|
| B
| Місяць (абревіатура: Jan, Feb і т.д.)
|
| B
| Повна назва місяця
|
| С
| Дата і час у форматі asctime()
|
| D
| День місяця (від 01 до 31)
|
| H
| Час в 24-годинному форматі (від 00 до 23)
|
| I
| Час в 12-годинному форматі (від 00 до 12)
|
| J
| День року (від 001 до 366)
|
| M
| Номер місяця (від 1 до 12)
|
| M
| Хвилина (від 00 до 59)
|
| P
| Букви АМ чи РМ (що позначають час до чи після півдня відповідно)
|
| S
| Секунда (від 00 до 59)
|
| U
| Номер тижня (від 00 до 53) (тиждень починається із неділі)
|
| w
| День тижня (від 0 до 6) (неділя == 0)
|
| W
| Номер тижня (від 00 до 53) (тиждень починається з понеділка)
|
| X
| Дата
|
| X
| Час
|
| Y
| Рік мінус сторіччя (наприклад, 68 для 1968)
|
| Y
| Повний рік (наприклад, 1968)
|
| Z
| Найменування часової зони (EST чи EDT)
|
Синтаксис: size_t strftime(char *s, size_t maxsize, const char *fmt, conststruct tm *t);
Параметри:
- char *s - вказівник на результуючу стрічку, в якій запам'ятовується результат функції.
- size_t maxsize - максимальне число символів, записуваних у результуючу стрічку. Звичайно встановлюється рівним розміру стрічки мінус одиниця.
- const char *fmt -вказівник на форматну стрічку, що містить звичайний текст і правила перетворення .
- const struct tm *t - вказівник на структуру типу tm, що містить дату і час, форматуємі у стрічку.
Функція аналогічна до asctime(), ctime(), localtime(), mktime(), time().
Приклад 6.9.:
#include<stdio.h>
#include<time.h>
#define SIZE 80
main()
{
time_t t;
struct tm *tp;
char s[SIZE];
time(&t);
tp = localtime(&t);
puts(“”);
strftime(s, SIZE, “Дата: %x\n”, tp);
puts(s);
strftime(s, SIZE, “Час: %x\n”, tp);
puts(s);
strftime(s, SIZE, “Сьогодні %A\n”, tp);
puts(s);
return 0;
}
Функція strncpy(), fstrncpy() - копіює максимум maxlen символів із вихідної стрічки src у результуючу стрічку dest, перезаписуючи символи результуючої стрічки. Якщо maxlen дорівнює розміру в байтах результуючій стрічці (і вихідна стрічка має не меншу довжину), то результуюча стрічка не завершується нульовим символом. Якщо maxlen і довжина вихідної стрічки перевищують розмір результуючої стрічки, кінець результуючої стрічки перезаписується, що, можливо, зруйнує інші дані чи код у цьому місці пам'яті. Щоб уникнути подібних помилок, ніколи не встановлюйте maxlen більше максимального числа символів, що може, містити результуюча стрічка(string.h)
Функція аналогічна доstrcat(), strcpy()
Приклад 6.10.:
#include<stdio.h>
#include<string.h>
main ( )
{
char src[80] = “abcdefghij”;
char dst[80] = “1234567890”;
printf (“До: src = =%s dst = =%s \n”, src, dst);
puts (“Викликаємо strncpy (dst, src, 5)”);
strncpy (dst, src, 5);
printf (“Після: src = = %s dst = = %s \n”, src, dst);
return 0;
}
Функція strstr(), fstrstr() - шукає стрічку (s2) в іншій стрічці (s1). Повертає адресу першого символу входження стрічки або, якщо підстрічка s2 не знайдена в стрічку s1, - повертає нуль (string.h)
Синтаксис:char *strstr (const char *s1, const char *s2);
char far *far _ fstrstr (const char far *s1, const char far *s2);
Параметри:
- const char *s1 - покажчик на стрічку, у якій відбувається пошук підстрічки, адресуємо s2.
- const char *s2-покажчик на підстрічку, що шукається в стрічці,
адресуємої s1.
Функція аналогічна до strchr(), strcmp(), strspn()
Приклад 6.11.:
/*strstr.cpp*/
#include<stdio.h>
#include<string.h>
main ()
{
char *s1= “filename.cpp”;
char *s2=”.cpp”;
printf (“s1= = %s \n”, s1 );
printf (“s2= = %s \n”, s2);
puts (“Викликаємо char *s3= strstr (s1, s2)”);
char *s3= strstr (s1, s2);
printf (“s3= = %s \n”, s3);
return 0;
}
Функція strtod() - Перетворить символьне представлення числа з плаваючою крапкою, що міститься в стрічці, у його двійкове представлення типу double чи long double. У випадку успіху повертає отриманий при перетворенні результат, а у випадку помилки повертає HUGE_VAL (strtod ()) чи LHUGE _VAL помилки повертає HUGE_VAL (strtod ()) чи LHUGE _VA(stdlib.h)
Синтаксис :double strtod (const char *s, char **endptr);
long double strtold (const char *s, char ** endptr);
Параметри :
- const char *s - покажчик на стрічку, що містить символьне представлення числа з плаваючою крапкою, або в десятковій нотації (наприклад, “123.45”), або в науковій нотації (наприклад, “4.5е-3”).
- char **endptr - якщо цей параметр не дорівнює нулю, то він повинен бути рівним адресі символу, розташованого безпосередньо після останнього символу в рядку s, що бере участь у перетворенні. Цей не обов'язковий покажчик використовується при розборі стрічок, що містять кілька значень з плаваючою комою, можливо, розділених символами пробілу, комами.
Функція аналогічна до atof(), printf(), sprintf(), strtol()
Приклад 6.12.:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
main (int argc, char *argv [ ])
{
if (argc <= 1)
{
puts (“Введіть значення типу double”);
puts (“наприклад, STRTOD 3.14159”);
exit (1);
}
char *endptr;
double d = strtod (argv[1], &endptr);
printf (“Значення у двійковому представленні = = %lf \n”, d);
if (strlen (endptr)>0)
printf (“Перегляд зупинений на: %s \n”, endptr);
return 0;
}
Функціяstrtol() -перетворить символьне представлення значення типу long у його двійкове представлення. Значення в стрічці може бути представлене в десятирічному, восьмирічному чи шістнадцятирічному вигляді, що використовує стандартні правила форматування мови С (що діють для printf( ), scanf( ) і інших аналогічних функцій). Розпізнаються також інші основи системи числення, від 2 до 36. У випадку успіху функція повертає перетворений результат і встановлює не нульовий покажчик endptr рівним адресі, що слідує за останнім символом, що входить у символьне представлення числа. У випадку помилки функція повертає нуль і встановлює ненульовий покажчик endptr рівним s.
Синтаксис: long strtol (const char *s, char **endptr, int radix);
Параметри:
- const char *s - покажчик на стрічку, що містить, ціле значення типу long у текстовому вигляді. Ця стрічка може також містити й інші символи.
- char ** endptr - якщо цей параметр не дорівнює нулю, то він повинен бути рівним адресі символу, розташованого безпосередньо після останнього символу в стрічці s, що бере участь у перетворенні. Цей необов'язковий покажчик використовується при розбиранні рядків, що містять кілька значень типу long, можливо, поділених символами пробілу, комами і т.п.
- int radix - задає основу системи числення, яка використовується при перетворенні, і може приймати значення від 2 до 36. Наприклад, 2 – для двійкових значень, 10 – для десятеричних значень, 16 – для шістнадцятирічних значень і т.д. Літери від A до Z розпізнаються як числові символи для основ, що перевищують 10. (При основі 16 для представлення числа використовуються цифри від 0 до 9 і букви від А до F, при основі 17 – цифри від 0 до 9 і букви від А до G і т.п.) Якщо параметр radix встановлений рівним нулю, функція буде автоматично розпізнавати і перетворити числа, використовуючи стандартні правила форматування мови С, тобто десяткові числа повинні починатися з цифри, вісімкові – із літери О, а шістнадцяткові – із префікса Ох чи ОХ.
Функція аналогічна до atoi(), atof(), atol(), printf(), sprintf(), strtoul().
Алгоритм розв’язання задачі наведено на рис. 6.1.
Розробка тексту програми
#include <stdio.h>
#include <ctype.h>
#include <conio.h>
#include <string.h>
#include <stdlib.h>
#include <dos.h>
int main()
{
char dod[1],s1[80];
int i,n,k=0;
char choice,vihid;
float bac;
clrscr();bac=0;
dо
{ clrscr();
printf(" MENU\n");
printf("1.- Vvedennya danih\n");
printf("2.- Rishennya zadachi\n");
printf("3.- vivedennya danih\n");
printf("4.- Zavershennya roboti\n");
scanf("%d",&choice);
switch(choice)
{
case 1:
{
clrscr();
printf("Vi vibrali punkt -vvedennya danih\n");
printf("vveditye recennya:\n");
gets(dod);
gets(s1);
bac++;
}
break;
case 2:
{ clrscr();
if (!(bac>0))
{
printf("viberity pershiy punkt i vvedit zminni\n");
getch();
break;
}
printf("znahodgennya kilkosti sliv\n");
if (s1[0] != ' '&&s1[0] != '\0') k=1;
n=strlen(s1);
for(i=0;i<n-1;i++)
if (s1[i]==' '&&s1[i+1]!=' ')
k++;
printf(«Virishuyu zadachu à»);
for(i=0;i<10;i++)
{
printf(«O»);
delay(500);
}
printf(«\n zadachu uspishno virisheno!!!\n»);
getch();
k=k;
break;
}
case 3:
{
clrscr();
printf(«vivod danih\n»);
printf(«string s=%s\n»,s1); k=k;
printf(«dovgina l=%d\n»,strlen(s1)); k=k;
printf(«kilkisty sliv k=%d\n»,k);
break;
}
case 4:
printf(«vi vibrali vihid\n»);
break;
default:
printf(«\n\n Illegal choice!!!/n»);
}
if (choice==1)
printf(«Chi bagayete rozvyazati zadachu?\n»);
else
printf(«chi bagayete dali prachuvati?\n»);
printf(«1-Tak 2-Ni\n»);
scanf(«%d»,&vihid);
}
while(vihid==1);
if (vihid==2)
printf(«Bagayemo uspihu!\n»);
else
printf(«\n\n Illegal choice!!!\n»);
getch();
return choice;
}
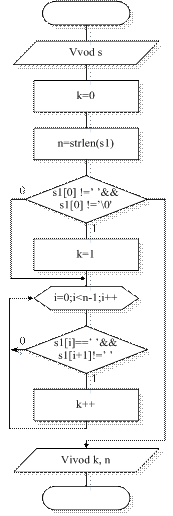
Рисунок 6.1–Логічна схема програми визначення кількості слів у тексті
На рис. 6.2 наведено алгоритм другого способу розв’язання задачі визначння кількості слів у тексті.

Рисунок 6.2 - Логічна схема програми визначення кількості слів у тексті
Розробка тексту програми
#include <stdio.h>
#include <ctype.h>
#include <conio.h>
#include <string.h>
#include <stdlib.h>
#include <dos.h>
int main()
{
char dod[1],s1[80];
int i,n,k=0;
char choice,vihid;
float bac;
clrscr();bac=0;
dо
{ clrscr();
printf(" MENU\n");
printf("1.- Vvedennya danih\n");
printf("2.- Rishennya zadachi\n");
printf("3.- vivedennya danih\n");
printf("4.- Zavershennya roboti\n");
scanf("%d",&choice);
switch(choice)
{
case 1:
{
clrscr();
printf("Vi vibrali punkt -vvedennya danih\n");
printf("vveditye recennya:\n");
gets(dod);
gets(s1);
bac++;
}
break;
case 2:
{ clrscr();
if (!(bac>0))
{
printf("viberity pershiy punkt i vvedit zminni\n");
getch();
break;
}
printf("znahodgennya kilkosti sliv\n");
if (s1[0] != ' '&&s1[0] != '\0') k=1;
n=strlen(s1);
for(i=0;i<n-1;i++)
if (s1[i]==' '&&s1[i+1]!=' ')
k++;
printf("Virishuyu zadachu -->");
for(i=0;i<10;i++)
{ printf("O");
delay(500);
}
printf("\n zadachu uspishno virisheno!!!\n");
getch();
k=k;
break;
}
case 3:
{
clrscr();
printf("vivod danih\n");
printf("string s=%s\n",s1); k=k;
printf("dovgina l=%d\n",strlen(s1)); k=k;
printf("kilkisty sliv k=%d\n",k);
break;
}
case 4:
printf("vi vibrali vihid\n");
break;
default:
printf("\n\n Illegal choice!!!/n");
}
if (choice==1)
printf("Chi bagayete rozvyazati zadachu?\n");
else
printf("chi bagayete dali prachuvati?\n");
printf("1-Tak 2-Ni\n");
scanf("%d",&vihid);
}
while(vihid==1);
if (vihid==2)
printf("Bagayemo uspihu!\n");
else
printf("\n\n Illegal choice!!!\n");
getch();
return choice;
}
6.5 Функції для обробки текстової інформації
Приклади розробки функцій для обробки текстової інформації
Приклад 6.13.
Функція обчислення довжини рядка. Наступна нижче функція має старомодну і форму, що не рекомендується стандартом, заголовка (у стандартній бібліотеці їй відповідає функція strlen( )):
int len(e)
char e[ ] ;
{
int m;
for (m=0; e[m]!='\0'; m++) ;
return m;
}
Відповідно до ANSI-стандарту і зі стандартом ISO заголовок повинний мати, наприклад, такий вид:
int len (char e[ ])
У цьому прикладі й у заголовку, і в тілі функції немає навіть згадувань про споріднення масивів і вказівників. Однак компілятор завжди сприймає масив як вказівник на його початок, а індекс як зсув відносно початку масиву. Наступний варіант тієї ж функції (тепер заголовок відповідає стандартам мови) явно реалізує механізм роботи з вказівниками:
int len (char *s)
{
int m;
for (m=0; *s++! = '\0' ; m++)
return m;
}
Для формального параметра-вказівника s всередині функції виділяється ділянка пам'яті, куди записується значення фактичного параметра. Так як s не константа, то значення цього вказівника може змінюватися. Саме тому припустимо вираз s++
Приклад 6.14.
Функція інвертування рядка-аргументу з параметром-масивом (заголовок відповідає стандарту):
void invert(char e[ ])
{
char s;
int і, j , m;
/*m - номер позиції символу '\0' у рядку е */
for (m=0; e[m]!='\0'; m++) ;
for (i=0, j=m-l; i<j; i++, j--)
{
s=e[i];
e[i]=e[j];
e[j]=s;
}
}
У визначенні функції invert() за допомогою ключового слова void зазначено, що функція не повертає значення.
В якості вправи можна переписати функцію invert(), замінивши параметр-масив параметром-вказівником типу char*.
При виконанні функції invert() рядок - фактичний параметр, наприклад, "сироп" перетвориться в рядок "порис". При цьому символ '\0' залишається на своєму місці наприкінці рядка. Приклад використання функції invert():
#include <stdio.h>
void main( )
{
char ct[ ]="0123456789";
/*Прототип функції: */
void invert(char [ ]);
/* Виклик функції: */
invert(ct)/
printf ("\n%s",ct) ;
}
Результат виконання програми:
Приклад 6.15.
Функція пошуку в рядку найближчого ліворуч входження іншого рядка (у стандартній бібліотеці є подібна функція strstr())
/*Пошук рядка СТ2 у рядку СТ1 */
int index (char * СТ1, char * CT2)
{
int і, j , ml, m2;
/* Обчислюються m1 і m2 - довжини рядків */
for (m1=0; CT1[m1] !='\0'; m1++);
for (m2=0; CT2[m2] !='\0'; m2++);
if (m2>m1)
return -1;
for (i=0; i<=m1-m2; i++)
{
for (j=0; j<m2; j++) /*Цикл порівняння */
if (СT2[j] !=СT1[i+j])
break;
if (j==m2)
return i;
} /* Кінець циклу по і */
return -1;
}
Функція index() повертає номер позиції, починаючи з якої СТ2 цілком збігається з частиною рядка СТ1. Якщо рядок СТ2 не входить у СТ1, то повертається значення -1.
Приклад звертання до функції index( ):
#include <stdio.h>
void main( )
{
char C1[ ]="сума мас";
/* Прототип функції: */
int index(char [ ], char [ ]);
char C2[ ]="ма"/
char C3[ ]="ам";
printf("\nДля %s індекс=%d",C2,index(C1,C2) );
printf("\nДля %s індекс=%d",C3,index(C1,C3));
}
Результат виконання програми:
Для ма індекс=3 Для ам індекс=-1
У функції index() параметри специфіковані як вказівники на тип char,а в тілі функції звертання до символів рядків виконується за допомогою індексованих змінних. Замість параметрів-вказівників підставляють як фактичні параметри імена символьних масивів С1[ ], С2[ ], С3[ ]. Ніякої неточності тут немає: до масивів припустимі обидві форми звертання - і за допомогою індексованих змінних, і з використанням розіменованих вказівників.
Приклад 6.16.
Функція порівняння рядків. Для порівняння двох рядків можна написати наступну функцію (у стандартній бібліотеці мається близька до цієї функція strcmp()):
int row(char C1[ ], char C2[ ])
{
int і,m1,m2; /* m1,m2 - довжини рядків С1,С2 */
for (m1=0;*(C1+m1)= '\0'; m1++) ;
for (m2=0;*(C2+m2)= '\0'; m2++);
if (m1!=m2) return -1;
for (i=0; i<m1; i++)
if (*C1++ != *C2++) return (i+1);
return 0;
}
У тілі функції звертання до елементів масивів-рядків реалізовано через розіменування вказівників. Функція row() повертає: значення -1, якщо довжини рядків-аргументів С1, С2 різні; 0 - якщо всі символи рядків збігаються. Якщо довжини рядків однакові, але символи не збігаються, то повертається порядковий номер (ліворуч) перших незбіжних символів.
Особливість функції row() - специфікація параметрів як масивів і звертання до елементів масивів всередині тіла функції за допомогою розіменування. При цьому за рахунок операцій С1++ і С2++ змінюються початкові "настроювання" вказівників на масиви. Одночасно в тій же функції до тих же масивів-параметрів виконується звертання і за допомогою виразів *(Cl+m1) і *(С2+m2), при обчисленні яких значення С1 і С2 не міняються.
Приклад 6.17.
Функція з'єднання рядків. Наступна функція дозволяє "приєднати" до першого рядку-аргументу другий рядок-аргумент (у стандартній бібліотеці є подібна функція : strncat()):
/* З'єднання (конкатенація) двох рядків: */
void cone(char *C1, char *C2)
{
int i,m; /* m - довжина 1-го рядка */
for (m=0; *(C1+m)!='\0'; m++);
for (i=0; *(C2+i)!='\0'; i++)
*(C1+m+i)=*(C2+i);
*(C1+m+і)='\0';
}
Результат повертається як значення першого аргументу C1. Другий аргумент C2 не змінюється. Зверніть увагу на те, що при використанні функції соnс() довжина рядка, що заміняє параметр C1, повинна бути достатньої для прийому результуючого рядка.
Приклад 6.18.
Функція виділення підстроки. Для виділення з рядка С1 фрагмента заданої довжини (підстроки) можна запропонувати таку функцію:
void substr(char *C1, char *C2, int n, int k)
/* Cl - вихідний рядок */
/* C2 - підстрока, що виділяється */
/* n - початок підстроки, що виділяється */
/* k - довжина підстроки, що виділяється*/
{
int і,m; /* m - довжина вихідного рядка */
for (m=0; C1 [m] ! =' \0 ' ; m++) ;
if (n<0 || n>m || k<0 || k>m-n)
{
C2[0]='\0';
return;
}
for (i=n; i<k+n; i++)
C2[i-n]=C1[i-1];
C2[i-n]='\0';
return;
}
Результат виконання функції - рядок C2 [ ] з k символів, виділених з рядка C1[ ], починаючи із символу, що має номер n. При невірному сполученні значень параметрів повертається порожній рядок, використаний як параметр С2.
Приклад 6.19.
Функція копіювання вмісту рядка. Так як в мові Сі відсутній оператор присвоювання для рядків, то корисно мати спеціальну функцію, що дозволяє "переносити" вміст рядка в інший рядок (така функція strcpy() є в стандартній бібліотеці, але вона має інше значення, що повертається):
/* Копіювання вмісту рядка С2 в С1 */
void copy(char *С1, char *C2) /* С2 - оригінал,С1 - копія */
{
int і;
for (i=0; C2[i]!='\0'; i++)
C1[i]=C2[i];
C1[i]='\0';
}
Розробка алгоритму вирішення

Рисунок 6.3– Логічна схема програми, яка міняє і-ту стрічку з і+1
Розробка тексту програми
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <conio.h>
#include <alloc.h>
void ChangeStr(char **,int);
int main()
{
char s[1],**str;
int n,i;
clrscr();
while (1)
{
printf("\n vveditye kilkisty strichok n=");
scanf("%d",&n);
if (n>=1&&n<=10)
break;
printf("\n ERRORS!!! 1<=n<=10 \n");
}
str=(char**)malloc(n*sizeof(char*));
for(i=0;i<n;i++)
str[i]=(char*)malloc(80*sizeof(char));
printf("vvedity %d strok \n",n);
gets(s);
for(i=0;i<n;i++)
{printf("string[%d]=",i+1);
gets(str[i]);
}
printf("\n-----------pislya zminu strichok mayemo takuy masiv----------\n");
ChangeStr(str,n);
for(i=0;i<n;i++)
{
printf("string[%d]=",i+1);
puts(str[i]);
}
free(str);
getch();
return 0;
}
void ChangeStr(char **s1,int m)
{
char ss[80];
int j;
for (j=0;j<m-1;j++)
{
strcpy(ss,s1[j]);
// puts(ss);
strcpy(s1[j],s1[j+1]);
strcpy(s1[j+1],ss);
} }
6.6 Контрольні запитання
1. Які бібліотеки необхідно підключати для роботи зі стрічками?
2. Які є способи ініціалізації стрічок?
3. За допомогою яких функцій відбувається введення символів?
4. Як відбувається введення стрічок, які функції бібліотеки string.h при цьому використовуються?
5. За допомогою яких стандартних функцій відбувається введення стрічок?
6. За допомогою яких стандартних функцій відбувається виведення стрічок?
7. Які стандартні функції використовуються для визначення довжини стрічки?
8. Як відбувається пошук в стрічці входження під стрічки?
9. Напишіть, які ви знаєте стандартні функції для роботи зі стрічками?
10. Яка стандартна функція з бібліотеки string.h призначена для копіювання стрічки? Навести приклад.
11. За допомогою якої стандартної функції відбувається інвертування стрічки?
12. Як використати стрічку в якості параметрів функцій? Навести приклад.
13. Яка різниця між функцією strcmpi() і функцією strcmp()?
6.7 Практикум з програмування
1. Написати фрагмент програми для визначення кількості цифр в рядку, введеному з клавіатури.
2. Написати фрагмент програми у для інвертування заданого рядка.
3. Написати фрагмент програми для визначення кількості слів у тексті, що вводиться з клавіатури.
4. Написати фрагмент програми для поділу рядка на підстроки довжиною в 5 символів кожна, не враховуючи пробіл.
5. Написати фрагмент програми для копіювання з заданого тексту даної частини в рядок.
6. Написати фрагмент програми для злиття заданих рядків з тексту, що вводиться з клавіатури.
7. Написати фрагмент програми для визначення рядка максимальної довжини в тексті, що вводиться з клавіатури,.
8. Написати фрагмент програми для пошуку в рядку STR кількість входжень підстроки STR1.
9. Написати фрагмент програми для знаходження кількості однакових символів у слові, що вводиться з клавіатури.
10. Написати фрагмент програми яка визначає максимальну і мінімальну довжини стрічок в масиві і міняє їх місцями
7 РОБОТА З БАЗАМИ ДАНИХ
7.1 Загальні відомості
Відомі два підходи до організації інформаційних масивів: файлова організація та організація у вигляді бази даних. Файлова організація передбачає спеціалізацію та збереження інформації, орієнтованої, як правило, на одну прикладну задачу, та забезпечується прикладним програмістом. Така організація дозволяє досягнути високої швидкості обробки інформації, але характеризується рядом недоліків.
Характерна риса файлового підходу - вузька спеціалізація як обробних програм, так і файлів даних, що служить причиною великої надлишковості, тому що ті самі елементи даних зберігаються в різних системах. Оскільки керування здійснюється різними особами (групами осіб), відсутня можливість виявити порушення суперечливості збереженої інформації. Розроблені файли для спеціалізованих прикладних програм не можна використовувати для задоволення запитів користувачів, які перекривають дві і більше області. Крім того, файлова організація даних внаслідок відмінностей структури записів і форматів передання даних не забезпечує виконання багатьох інформаційних запитів навіть у тих випадках, коли всі необхідні елементи даних містяться в наявних файлах. Тому виникає необхідність відокремити дані від їхнього опису, визначити таку організацію збереження даних з обліком існуючих зв'язків між ними, яка б дозволила використовувати ці дані одночасно для багатьох застосувань. Вказані причини обумовили появу баз даних.
База даних може бути визначена як структурна сукупність даних, що підтримуються в активному стані та відображає властивості об'єктів зовнішнього (реального) світу. В базі даних містяться не тільки дані, але й описи даних, і тому інформація про форму зберігання вже не схована в сполученні "файл-програма", вона явним чином декларується в базі.
База даних орієнтована на інтегровані запити, а не на одну програму, як у випадку файлового підходу, і використовується для інформаційних потреб багатьох користувачів. В зв'язку з цим бази даних дозволяють в значній мірі скоротити надлишковість інформації. Перехід від структури БД до потрібної структури в програмі користувача відбувається автоматично за допомогою систем управління базами даних (СУБД).
Основними та невід'ємними властивостями БД є такі:
- для даних допускається така мінімальна надлишковість, яка сприяє їх оптимальному використанню в одному чи кількох застосуваннях;
- незалежність даних від програм;
- для пошуку та модифікації даних використовуються спільні механізми;
- як правило, у складі БД існують засоби для підтримки її цілісності та захисту від неавторизованого доступу.
Основні принципи створення БД: цілісність, вірогідність, контроль, захист від несанкціонованого доступу , єдність і гнучкість, стандартизація та уніфікація, адаптивність, мінімізація введення і виведення інформації (однократність введення інформації, принцип введення - виведення тільки змін).
7.2 Особливості розробки програм для роботи з базами даних
на мові С
Звичайно програми для роботи з базами даних (DB – data base) є частиною програмних комплексів для автоматизованих систем керування підприємствами, технологічними процесами, деякими об'єктами. Однією з головних особливостей таких програм є організація збереження, відновлення, обробки великих обсягів інформації, тому при розробці таких програм необхідно вирішити визначене коло задач. До них відносяться:
1) Визначити кінцеву мету, тобто які задачі необхідно вирішувати за допомогою цих програм, а так само – яку інформацію й у якому виді можна одержати з їх допомогою;
2) Визначити набір функцій, виконуваних програмою. Наприклад, за допомогою програми необхідно:
- створити б.д. (тобто інформаційне сховище);
- накачати б.д. даними;
- дозаписати дані в базу;
- видаляти деякі дані з бази;
- редагувати дані в базі (коректування);
- сортувати дані в базі за заданими критеріями.
3) Визначити набір вихідної інформації (вхідні дані), необхідний для рішення поставлених задач.
4) Вибрати (визначити) кількість файлів у базі, об’єднавши інформацію з груп і спроектувати базу даних.
5) Розробити структуру керуючої програми, включивши в неї основний клас розв'язуваних задач.
6) Розробити ієрархічну структуру розв'язуваних підзадач, деталізувавши її до рівня програмувальних функцій.
Наприклад найпростіша керуюча програма для роботи з б.д. може працювати з такими задачами:
· Задача «Роботи з б.д.»;
· Задача «Формування звітних документів за заданими критеріями»
Задача «Робота з б.д.» може містити такі підзадачі:
- створення б.д.
- дозапис у б.д.
- накачування б.д.
- редагування записів у б.д.
- видалення запису
7.3 Приклад проектування бази даних
У Сі базу даних зручно записувати як файл структур (struct). Кожен запис є елементом структурного типу даних із членами, що представляють рядки полів фіксованого розміру, цілі, речовинні значення й ін. Усе, що можна записати в структурі, можна записати в двійковий файл із довільним доступом і прочитати з нього.
Проектування баз даних
1) Першим кроком у написанні програми створення, обробки, ведення бази даних є розробка структури запису файлу. Наприклад, для задачі «Телефонний абонент» структура запису основного файлу може мати вид:
Typedef struct
{ char name [NAMELEN];
char addr [ADDRLEN];
char csz [CSZLEN];
char phone [PHONELEN];
double balance;
} Record;
2) Другим кроком є планування набору функцій по веденню б.д. і розробка їх прототипів. З прототипів функцій зручно створити заголовний файл, наприклад, db.h (database), а потім у файлі db.с скомпонувати всі ці функції, що будуть викликатися функцією main()
/* Заголовний файл для роботи з базою даних db.h */
#include <stdio.h>
#include <limits.h>
#define FALSE 0
#define TRUE 1
#define NAMELEN 30
#define ADDRLEN 30
#define CSZLEN 30
#define PHONELEN 13
typedef struct record{
union{
long numrecs;/* Заголовок==число записів */
long custnum;/*Запис==номер клієнта */
}info;
char name[NAMELEN]; /* FIO клієнта */
char addr[ADDRLEN];/*Адрес клієнта */
char csz[CSZLEN];/* Місто, штат клієнта */
char phone[PHONELEN]; /*Телефон клієнта */
double balance;/* Поточний залишок */
}Record;
#define MAXREC (LONG_MAX / sizeof(Record))
// Створення нової бази даних з ім'ям path. Повертає FILE чи NULL і header
int CreateDB(const char *path);
// Відкриває базу даних з ім'ям path. Повертає FILE чи NULL і header
FILE *OpenDB(const char *path, Record *header);
// Читає запис з номером recnum у rec. Повертає TRUE/FALSE
int ReadRecord(FILE *f, long recnum, Record *recp);
// Записує запис з номером recnum з rec. Повертає TRUE/FALSE
int WriteRecord(FILE *f, long recnum, Record *recp);
// Додає запис у кінець файлу. Повертає TRUE/FALSE
int AppendRecord(FILE *f, long recnum, Record *recp);
// Відображає мітку і вводить символьний рядок
void InputLong(const char *label, long *lp);
// Відображає мітку і вводить значення типу double
void InputDouble(const char *label, double *dp);
void Іnрutсhаr(const char *label, char *cp, int len);
У структурі Record використовується об'єднання union, що допомагає організувати базу даних. Поля об'єднання запам'ятовуються одне поверх іншого, тобто незважаючи на те що оголошено в union два елементи типу long, в однин і той же час може використовуватися тільки одне з них. Призначення об'єднання складається в реєстрації номерів записів у файлі бази даних. Запис з нульовим номером запам'ятовує цю інформацію, використовуючи в структурі поле numrecs (і ніяке інше).
Записи з номерами 1 і вище містять значущу інформацію – у даному випадку, номер клієнта, його ім'я, адреса й інші дані.
Розглянемо організацію цього файлу.
Рисунок 7.1 - Приклад бази даних і запис інформаційного заголовка
//Файл db.c, що містить опис функцій, описаних у db.h
#include<stdio.h>
#include<string.h>
#include <stdlib.h>
#include "db.h"
// ***********************
//
int CreateDB(const char *path)
{
FILE *f;
Record rec;
int result;
f=fopen(path,"wb");//створення нового файлу б.д.
if (!f)
return FALSE;
memset(&rec,0,sizeof(Record));
rec.info.numrecs=0;//початкове значення запису numrec=0, тому що поки б.д.ще не містить ніяких записів
result=WriteRecord(f,0,&rec);
fclose(f);
return result;
}
FILE *OpenDB(const char *path, Record *header)
{
FILE *f=fopen(path,"r+b");//відкриття файлу f
if (f)
ReadRecord(f,0, header);//читання інформаційного запису файлу, визначаючи кількість записів, що містяться у файлі
return f;
}
//Читання запису з номером recnum з файлу f у рядок Record, що адресується покажчиком *recp.
int ReadRecord(FILE *f, long recnum, Record *recp) //
{
if(recnum>MAXREC)
return FALSE;
if(fseek(f,recnum * sizeof(Record),SEEK_SET)!=0)//переміщення покажчика в позицію
return FALSE;
return(fread(recp,sizeof(Record),1,f)==1);
}
//передає на диск структуру запису, що адресується покажчиком recp.
{
int WriteRecord(FILE *f, long recnum, Record *recp)
if (recnum > MAXREC)
return FALSE;
if(fseek(f,recnum* sizeof(Record),SEEK_SET)!=0) //позиціювання покажчика
return FALSE;
return(fwrite(recp,sizeof(Record),1,f)==1);
}
int AppendRecord(FILE *f, long *recnum, Record *recp)
{
if (fseek(f,0, SEEK_END)!=0)//установка файлового покажчика в кінець файлу
return FALSE;
*recnum = ftell(f) / sizeof(Record); // ftell(f)повертає значення покажчика у файлі
//визначення номера запису, що додається
return WriteRecord(f, *recnum, recp); //дозапис у кінець файлу
}
void InputLong(const char *label, long *lp)
{
char buffer[128];
printf(label);
gets(buffer);
*lp=atol(buffer);
}
void InputChar(const char *label, char *cp, int len)
{
char buffer[128];
printf(label);
gets(buffer);
strncpy(cp,buffer,len-1);
}
void InputDouble(const char*label, double *dp)
{
char buffer[128];
printf(label);
gets(buffer);
*dp=atof(buffer);
}
7.4 Створення файлів обробки бази даних
Після розробки структури бази даних і функцій ведення б.д., необхідно створити базу даних (тобто створити порожній файл б.д.). Розглянемо приклад програми для рішення цієї задачі. Оформимо її в окремий файл MAKEDB.C.
Дана програма обов'язково повинна включати заголовний файл db.h, що повідомляє структуру бази даних і прототипи функцій, описаних у модулі db.с. Щоб створити закінчену програму, необхідно:
1) скомпілювати MAKEDB.C. і db.с
2) скомпонувати об'єктні файли програм MAKEDB.Cіdb.с у закінчений виповнюючий файл MAKEDB.ЕХЕ
// Програма MAKEDB.C
#include <stdlib.h>
#include <string.h>
#include "db.h"
// Створення порожнього файлу бази даних
int FileExists(const char *path);
int main()
{
char path[128];
puts("Create new database file");
printf("Filename= ");
gets(path);
if (strlen(path)==0)
exit(0);
if (FileExists(path))
{
printf("%s **** already exists. \n", path);
puts("Delete file and try again");
exit(1);
}
if (!CreateDB(path)) //якщо файл існує, то програма не перезаписує його
perror(path);
else
printf("%s *** created. \n",path);
return 0;
}
int FileExists(const char path)//допоміжна функція, що повертає «істину», якщо заданий файл, обумовлений покажчиком path типасhаr*, існує
{
FILE *f = fopen(path, "r");
if (!f)
return FALSE;
else
{
fclose(f);
return TRUE;
}
}
// Програма додавання записів у б.д.
// файл ADDREC.c
#include <stdlib.h>
#include <string.h>
#include <memory.h>
#include "db.h"
void GetNewRecord(Record *recp);
int main()
{
char path[128];
FILE *dbf;
Record rec;
long numrecs;
//
printf(" ********* Database name = ");
gets(path);
dbf= OpenDB(path,&rec);
if (!dbf)
{
printf(" ********* Can't open %s file \n", path);
exit(1);
}
numrecs= rec.info.numrecs;
printf("********** Number of records ==%lu\n",numrecs);
GetNewRecord(&rec);
if (AppendRecord(dbf, &numrecs, &rec))
printf(" *********** Record #%lu added no database \n", numrecs);
memset(&rec,0,sizeof(Record));
rec.info.numrecs = numrecs;
WriteRecord(dbf,0,&rec);
fclose(dbf);
return 0;
}
void GetNewRecord(Record *recp);
{
memset(recp,0,sizeof(Record));
InputLong("Customer # : ", &recp->info.custnum);
InputChar("Name :", recp->name, NAMELEN);
InputChar("Address :", recp->addr, ADDRLEN);
InputChar("Sity, State, Zip :", recp->csz, CSZLEN);
InputChar("Telephone :", recp->phone, PHONELEN);
InputDouble("ACCOUNT balance :", recp->balance);
}
Ця програма додає тільки 1 запис у файл. Якщо необхідно дозаписати трохи записів, то необхідно додати цикл і, наприклад, після введення кожного запису запитувати користувача, чи не хоче він додати ще одну.
Більшість б.д. вимагають крім уведення нових записів, редагувати (коректувати, змінювати) вже існуючі у файлі деякі записи, не змінюючи інші.
У даній програмі використовуються методи довільного доступу після введення номера запису для редагування і після цього виповнююється відновлення інформації, змушуючи користувача повторно уводити всі поля обраного запису. Багато програмістів таке редагування називають недружелюбним.
// Програма редагування записів у файлі б.д.
// файл EDIREC.c
#include <stdlib.h>
#include <memory.h>
#include "db.h"
void EditRecord(FILE *f,long recnum, Record *recp);
int main()
{
char path[128];
FILE *dbf;
Record rec;
long numrecs, recnum;
printf("************ Database file name =");
gets(path);
dbf = OpenDB(path,&rec);
if (!dbf)
{
printf(" ******** Can't open %s file \n", path);
exit(1);
}
numrecs = rec.info.numrecs;
printf(" ****** Number of records == %lu \n",numrecs);
InputLong("*** Record number ?",&recnum);
if ((recnum<=0) || (recnum>numrecs))
{
puts("**** Record number out of range");
fclose(dbf);
exit(1);
}
EditRecord(dbf, recnum, &rec);
if (WriteRecord(dbf, recnum, &rec))
printf("**** Record namber #%lu writted to &s\n", recnum, path);
else
perror("Write record");
fclose(dbf);
return 0;
}
void EditRecord(FILE *f, long recnum, Record *recp)
{
if (!ReadRecord(f,recnum, recp))
{
perror("Reading record");
exit(1);
}
printf("***** Cstomer # : %lu\n",recp->info.custnum);
InputLong("Customer # : ",&recp->info.custnum);
printf("**** Name : %s\n",recp->name);
InputChar("Name : ", recp->name, NAMELEN);
printf("**** Address : %s\n", recp->addr);
InputChar("Adderss : ", recp->addr, ADDRLEN);
printf("**** City, State, Zip :", recp->csz);
InputChar(" City, State, Zip :", recp->csz, CSZLEN);
printf("**** Telephone : %s\n", recp->phone);
InputChar("Telephone :", recp->phone, PHONELEN);
printf(" ** Account balance : %8.2f\n", recp->balance);
InputDouble(" Account balance : " , &recp->balance);

Рисунок 7.1 – Алгоритм створення програми
Для роботи з базами даних можна використовувати програмне забезпечення, що характеризується певними структурами та функціями.
В першу чергу необхідно визначити типи фалів для збереження в них інформації та структури цих файлів, оскільки це спрощує та полегшує роботу з ними.
На прикладі розглянемо програмне забезпечення автоматизації роботи диспетчера торгової фірми по отриманню та виконанню замовлень від клієнтів. В даному випадку необхідно розробити бази даних, які будуть містити наступні таблиці:
- “Товари”;
- “Клієнти”;
- “Виконані замовлення”.
Таблиця 7. 1 – Опис файлів бази даних
| База
| Тип файлу
| Назва
|
| Товари
| Бінарний
| Prodbase.dat
|
| Клієнти
| Бінарний
| Klntbase.dat
|
| Виконані замовлення
| Бінарний
| Cmplbase.dat
|
База даних товарів містить у собі код, назву товару, назву фірми-виробника, характеристику товару, ціну за 1шт., кількість товару на складі та примітки.
Таблиця 7.2 – Структура файлу Prodbase.dat
| № поля
| Зміст поля
| Найменування (на Сі) поля
| Розмір
| Тип поля
|
|
| Код товару
| code
|
| char[3]
|
|
| Назва товару
| tovar
|
| char[15]
|
|
| Фірма-виробник
| producer
|
| char[15]
|
|
| Характеристика товару
| discription
|
| char[15]
|
|
| Ціна за 1шт.
| price
|
| char[5]
|
|
| Кількість товару на складі
| number
|
| char[5]
|
|
| Примітки
| notes
|
| char[8]
|
Структура файлу з програмної точки зору буде виглядати наступним чином:
struct Product//задаємо назву типу структури
{
char code[3];
char name[15];
char producer[10];
char description[30];
char price[5];
char number[5];
char notes[10];
}
База даних клієнта містить у собі повну назву фірми-клієнта (назва, адреса та телефон), покупця (ПІП, посада, та телефон) і заборгованість клієнта фірмі АСКО-Електрик.
Таблиця 7.3 – структура файлу Klntbase.dat
| № поля
| Зміст поля
| Найменування (на Сі) поля
| Розмір
| Тип поля
|
|
| Фірма
| Firma
| -
| Struct
|
|
| Ім'я покупця
| Pokupatel
| -
| Struct
|
|
| Борг
| Borg
|
| char[5]
|
struct Klient
{
struct Firma firma;
struct Pokupatel pokupatel;
char borg[5];
}
Для зручності роботи в структуру файла клієнта були включені наступні структури:
Таблиця 7.4 –Структура Firma
| № поля
| Зміст поля
| Найменування (на Сі) поля
| Розмір
| Тип поля
|
|
| Назва фірми
| name
|
| char[10]
|
|
| Адреса
| address
|
| char[10]
|
|
| Телефон фірми
| phone
|
| char[15]
|
struct Firma
{
char name[10];
char address[10];
char fphone[15];
}
Таблиця 7.5 –Структура Pokupatel
| № поля
| Зміст поля
| Найменування (на Сі) поля
| Розмір
| Тип поля
|
|
| Ім'я покупця
| name
|
| char[15]
|
|
| Посада
| posada
|
| char[10]
|
|
| Телефон покупця
| phone
|
| char[15]
|
struct Pokupatel
{
char name[15];
char posada[10];
char phone[15];
}
База даних замовлень містить у собі номер замовлення, код товару, дату замовлення, фірму-клієнта, ім'я покупця, назву товару, ціну одиниці товару, кількість купленого товару, загальну ціну (суму товару), оплату клієнта.
Таблиця 7.6 –Структура файлу Cmplbase.dat
| № поля
| Зміст поля
| Найменування (на Сі) поля
| Розмір
| Тип поля
|
|
| Номер замовлення
| znomer
|
| char[3]
|
|
| Код товару
| code
|
| char[3]
|
|
| Дата замовлення
| date
|
| char[10]
|
|
| Фірма (клієнт)
| zfirma
|
| char[10]
|
|
| Ім'я покупця
| FIO
|
| char[15]
|
|
| Назва товару
| tovar
|
| char[15]
|
|
| Ціна за 1 шт.
| Price
|
| char[5]
|
|
| Кількість купленого
| number
|
| char[5]
|
|
| Ціна загальна
| allprice
|
| char[5]
|
|
| Оплата клієнта
| Payment
|
| char[5]
|
|
| Заборгованість
| borg
|
| char[5]
|
struct Final
{
char znomer[3];
char code[3];
char date[10];
char zfirma[10];
char FIO[15];
char tovar [15];
char Price[5] ;
char number[5];
char allprice[5];
char Payment[5];
char borg[5];
}
Для роботи з базами насамперед були розроблені функці, що виконують наступні операції:
1. Створення файлу задля збереження інформації
2. Запис даних в файл
3. Зчитування даних з фалу
4. Видалення даних з фалу
Всі розглянуті вище бази даних відрізняються лише структурами файлів, тому для прикладу розглянемо лише базу даних товарів.
struct Product
{
char code[4]; // kod tovaru
char tovar[15]; // nazva tovaru
char producer[15]; //firma-virobnuk
char discription[15]; // haracteristica tovaru
char price[6]; // cina za 1-u sht
char number[6]; // kilkisty na skladi
char notes[9]; // prumitku
};
Розглянемо основні функції даного програмного забезпечення:
int dbf_exists(char *filename) – дана функція призначена для перевірки існування файлу. Якщо фал не існує (тобто файловий потік NULL), то функція повертає значення 0, в іншому випадку повертає значення 1.
Код даної функції приведений нижче:
int dbf_exists( char *filename )
{
FILE *instream=fopen(filename,"rb");// створення фалового потоку //*instream для роботи з фалом
// filename, що знаходиться на дискові
if (instream==NULL)
return 0;
else
{
fclose(instream);
return 1;
}
}
int dbf_records(char *fname, Product *prod) – функція призначена для підрахунку кількості записів структурного типу Product у файлі.
char *fname – назва файлу
Product *prod– тип структури
Код даної функції має такий вигляд:
int dbf_records(char *fname, Product *prod)
{
FILE *instream=fopen(fname,"rb");
if (instream==NULL)
return 0;
else
{
fseek(instream,0L,SEEK_END);//встановлення показника в кінець файлу
Int flen=ftell(instream);// визначення кількості байт в частині фалу //від його початку до показника
fclose(instream);
return flen/sizeof(*prod);// повертаємо число – кількість записів
}
}
void dbf_write_struct(char *filename,Product *prod) – функція призначена для запису структури типу Product у файл.
Код даної функції має такий вигляд:
void dbf_write_struct(char *filename,Product *prod)
{
FILE *istream=fopen(filename,"ab");
fseek(istream,0L,SEEK_END);//встановлюємо показник в кінець фалу
fwrite(prod,sizeof(Product),1,istream);//записуємо з джерела prod розміром Product 1-у порцію в файл
fclose(istream);
}
void dbf_rewrite_struct(char *filename,Product *prod,int record) – функція призначена для перезапису структури за заданим номером record типу Product у файлі.
Код даної функції має такий вигляд:
void dbf_rewrite_struct(char *filename,Product *prod,int record)
{
FILE *istream=fopen(filename,"r+b");
fseek(istream,record*sizeof(Product),SEEK_SET);//встановлення показника на місце заданого запису з початку файлу
fwrite(prod,sizeof(Product),1,istream);
fclose(istream);
}
void dbf_delete_record(char *filename, int record) – функція призначена для видалення запису за заданим номером record з файлу.
Код даної функції має такий вигляд:
void dbf_delete_record(char *filename, int record)
{
FILE *instream = fopen(filename,"rb");
FILE *onstream = fopen(temp_filename_s, "wb");
Product prod;
//int count=-1;
fseek(instream,0L,SEEK_END);//встановлюємо показник в кінець файлу
int flen = ftell(instream);//знаходимо розмір файлу в байтах
fseek(instream,0L,SEEK_SET);//встановлюємо показник на початокфайлу
for(int i=0;i<(flen/sizeof(Product));i++)
{
memset(&prod,0,sizeof(Product));
fread(&prod,sizeof(Product),1,instream);//зчитуємо з файлового потоку
// instream в prod одну порцію даних розміром sizeof(Product)
if (i != record)
fwrite(&prod,sizeof(Product),1,onstream);
}
fclose(instream);
fclose(onstream);
unlink(filename);// перевідкриття файлу
dbf_rename(temp_filename_s,filename);//перейменування файлу
}
void dbf_readrecord(char *fname, int record, Product *outdata) – функція призначена для зчитування запису за заданим номером record з файлу в структуру типу Product
Код даної функції має такий вигляд:
void dbf_readrecord(char *fname, int record, Product *outdata)
{
FILE *istream = fopen(fname,"rb");
fseek(istream,record*sizeof(Product),SEEK_SET);
read(outdata,sizeof(Product),1,istream);//зчитування з файлового потоку istream в комірку пам’яті outdata даних розміром
sizeof(Product) одиоразово
fclose(istream);
}
int dbf_search(char *fname, int field,char *keyword) – функція призначена для пошуку в файлі необхідних записів по даному ключовому слову і по даному полю. Тобто дана функція зчитує всі записи з файлу, шо знаходяться по даним критеріям (поле структуи field, ключове слово keyword) і записує всі знайдені записи (структури) в тимчасовий файл temp_filename_s.
Код даної функції має такий вигляд:
int dbf_search(char *fname, int field,char *keyword)
{
FILE *instream = fopen(fname ,"rb");
FILE *tmpstream = fopen(temp_filename_s,"wb");
Product prod;
char *pr, *num;
//обнуляємо структуру prod
memset(&prod,0,sizeof(Product));
//встановлюємо показник в кінець
//файлу, щоб визначити розмір файлу за допомогою ftell(instream)
fseek(instream, 0L, SEEK_END);
//визначаємо кількість записів
int flen = ftell(instream)/sizeof(Product);
fseek(instream, 0L, SEEK_SET);
//змінюємо всі великі символи стрічки на малі
strlwr(keyword); for (int i = 0, count = 0; i < flen; i++)
{
fread(&prod,sizeof(Product),1,instream);
//наступний код призначений для порівняння ключового слова
//з всіма властивостями структури
switch (field)
{
case 1:
//перевірка рівності двох стрічок - prod.code і keyword
if (strstr(strlwr(prod.code),keyword) != NULL)
{
//запис в тимчасовий файл знайденого поля
fwrite(&prod,sizeof(Product),1,tmpstream);
count++;
}
break;
case 2:
if (strstr(strlwr(prod.tovar),keyword) != NULL)
{
//запис в тимчасовий файл знайденого поля
fwrite(&prod,sizeof(Product),1,tmpstream);
count++;
}
break;
case 3:
if (strstr(strlwr(prod.producer),keyword) != NULL)
{
//запис в тимчасовий файл знайденого поля
fwrite(&prod,sizeof(Product),1,tmpstream);
count++;
}
break;
case 4:
if (strstr(strlwr(prod.discription),keyword) != NULL)