1. Как описывается заголовок процедуры и функции?
2. Что входит в тело процедуры?
3. Отличия процедуры и функции.
4. Понятия локальной и глобальной переменной.
5. Обращение к подпрограммам.
6. Какие параметры являются фактическими, какие формальными?
7. Параметры процедур и функций.
8. Соответствие между формальными и фактическими параметрами.
ПРОГРАМУВАННЯ ТА АЛГОРИТМІЧНІ МОВИ
- Візуальне проектування програмних засобів.
Трудомісткість процесу програмування зростає випереджаючими темпами в міру збільшення розмірів програм, що складаються. Великі програми, які складаються з десятків та навіть сотень тисяч машинних команд, потребують для своєї розробки та експлуатації додаткових засобів. Складність сучасних обчислювальних систем, а також висока вартість створення якісного та надійного програмного забезпечення ЕОМ стимулюють розвиток теоретично обгрунтованих методів та засобів розробки програмних систем. Особливо актуальним є застосування таких методів та засобів при об'єктно-орієнтованому підході до створення програмних систем.
Однією з основних тенденцій у галузі комп'ютерних технологій протягом останніх десятиріч був швидкий розвиток засобів візуалізації різноманітної інформації. Графічний інтерфейс користувача, візуальне програмування та візуалізація даних віддзеркалюють природне прагнення людини мати справу з графічними сутностями. Графічне зображення краще відповідає людським можливостям сприйняття, аналізу та обробки візуальної інформації порівняно з її звичайним представленням у вигляді текстів та таблиць.
Візуальне програмування та візуалізація програмного забезпечення призначені для поліпшення процесу програмування, особливо для програмістів-непрофесіоналів. Формалізовані візуальні мови набули широкого використання при проектуванні та розробці складних програмних систем. Вони є складовою частиною CASE технології.
Проблеми традиційного неітеративного життєвого циклу програмного забезпечення, який не враховує потреб повторного використання та уніфікованої інтеграції фаз розробки програмного забезпечення (ПЗ), призвели до створення об'єктно орієнтованого аналізу, об'єктно орієнтованого проектування та об'єктно орієнтованого програмування.
Об'єктно-орієнтовані методи розробки програмного забезпечення широко застосовують візуальні мови для аналізу, проектування, реалізації, супроводження та повторного використання програмних систем. Об'єктно орієнтований підхід (ООП) стосовно розробки ПЗ записується формулою
ООП = об'єкти + класи + наслідування.
Другий з вищеперелічених компонентів із заміною слова "класи" на "типи" є характерним також для теорії абстрактних типів даних.
Використання об'єктів та структур даних як основи для поділу системи на компоненти дає можливість покращити такі характеристики якості програмних систем як сполучуваність, можливість повторного використання та стабільність. Сполучуваність не може бути забезпечена, якщо комбінуються дії, які використовують неузгоджені структури даних. Для будь-якої програми, що використовує нетривіальні дані, неможливо побудувати придатні для повторного використання модулі, якщо вони відбивають тільки дії та не враховують дані. При об'єктно орієнтованому підході дані групують разом з діями, створюючи узгоджене представлення об'єктів, що розширюється. Об’єкти та структури даних, що розглядаються на різних рівнях абстракції, – це найстабільніший елемент програмної системи.
В нинішній час методи та засоби візуального проектування об'єктно-орієнтованих програмних систем, розподілених у мережах ЕОМ, детально не розроблені. Необхідність розв'язання цієї проблеми обгрунтована виникненням розподілених програмних систем у різних галузях народного господарства України.
- Середовище візуального програмування. Форма. Інспектор об’єктів. Редактор коду. Палітра компонентів.
Візуа́льне програмува́ння — спосіб створення програм шляхом маніпулювання графічними об'єктами замість написання програмного коду в текстовому вигляді.
Мови візуального програмування можуть бути додатково класифіковані в залежності від типу і ступеня візуального вираження, на типи:
Мови на основі об'єктів, коли візуальне середовище програмування надає графічні або символьні елементи, якими можна маніпулювати інтерактивним чином згідно з деякими правилами;
Мови на основі форм, коли програмування здійснюється шляхом поміщення на спеціальні форми об'єктів і настроюванням їх властивостей та поведінки. Приклади: Delphi і C++ Builder фірми «Borland».
Мови схем, що базуються на ідеї «фігур і ліній», де фігури (прямокутники, овали та ін.) розглядаються як суб'єкти і з'єднуються лініями (стрілками, дугами тощо), які представляють собою відношення. Приклад: UML.
Візуально-перетворені мови є невізуальними мовами з накладеним візуальним представленням (наприклад, середовище Visual C++ для мови C++). Природно-візуальні мови мають невід'ємне візуальне вираження, для якого немає очевидного текстового еквіваленту (наприклад, графічна мова G в середовищі LabVIEW).
Інтегроване Середовище Розробки (ІСР)-це комп’ютерна програма, що допомагає програмістові розробляти новепрограмне забезпечення чи модифікувати (удосконалювати) вже існуюче.
Інтегровані середовища розробки зазвичай складаються з редактору вихідного коду, компілятора чи/або інтерпретатора, засобів автоматизації збірки
Іноді сюди також входять системи контролю версій, засоби для профілювання, а також різноманітні засоби та утиліти для спрощення розробки графічного інтерфейсу користувача. Багато сучасних ІСР також включають оглядач класів, інспектор об'єктів та діаграм ієрархії класів для використання об'єктно-орієнтованого підходу у розробці програмного забезпечення. Хоча існують та використовуються ІСР, що підтримують розробку на декількох мовах програмування, зазвичай ІСР призначене для розробки на одній мові програмування.
- Поняття і структура програми та проекту.
Комп'ю́терна програ́ма (англ. Computer program) — докладний план дії обчислювальної машини, що складається з послідовних команд (інструкцій), за якими машина виконує весь процес обчислень. По іншому визначають, як низку команд для комп'ютера, що становлять запис алгоритму однією з мов програмування.
Програма — заздалегідь затверджена (визначена) дія.
Проект (системний підхід) — процес переходу з одного (початкового) стану в інший (кінцевий) стан за участі ряду обмежень.
Проект може бути розбитий як на підпроекти, так і на фази. Сукупність фаз представляє собою життєвий цикл проекту.
- Типи даних та їх представлення у комп’ютері.
Область зберігання даних в апаратній частині комп'ютера (пам'ять, регістри і зовнішні запам'ятовуючі пристрої) зазвичай мають доволі просту структуру в вигляді послідовності бітів, згрупованих в байти або слова. Проте в віртуальному комп'ютері, як правило, організовано більш складним чином — в різні моменти виконання програми використовуються такі форми зберігання даних, як стеки, масиви, числа, символьні рядки та інші. Один або декілька однотипних елементів даних, об'єднаних в одне ціле в віртуальному комп'ютері в певний момент виконання програми, прийнято називати об'єктом даних. При виконанні програми існує багато об'єктів даних різних типів. Тип даних — це деякий клас об'єктів даних разом з набором операцій для створення і роботи з ним. В кожній мові програмування є певний набір вбудованих примітивних типів даних. Додатково в мові можуть бути передбачені засоби, що дозволяють програмісту визначати нові типи даних.
Машинні типи даних
У всіх комп'ютерах, основаних на цифровій електроніці, інформація на найнижчому рівні представляється у вигляді бітів (із значенням 0 або 1). Найменша адресована одиниця інформації називається байт (зазвичай як октет, який містить 8 бітів). Одиниця інформації, яка оброблюється інструкціями машинного коду, називається словом (станом на 2006 рік, зазвичай по 32 або 64 біти). Більшість інструкцій сприймають слово як двійкове число, щоб 32-бітне слово могло бути представлене беззнаковим цілим числом від 0 до 232
Мови програмування представляють деякі прості типи даних, як базові блоки для програм та спеціалізованіших складних типів даних. Зазвичай прості типи даних включають цілі та дійсні числа та рядки.
Цілі числа (англ. integer) не можуть містити у собі дріб. Для від'ємного числа треба ставити знак мінус (-) перед значенням (числом). Неможна використовувати кому у введені такого числа, бо інакше буде викликана синтаксична помилка.
Дійсні числа можуть містити у собі як цілі, так і дробові значення з точкою відокремлення від цілої частини. Для від'ємного числа треба ставити знак мінус (-) перед значенням (числом).
Рядки (англ. string) — нечисловий тип даних, та використовується для збереження букв та слів. Усі рядки складаються з символів. Рядки можуть містити цифри та числа, але все одно будуть оброблятися як текст.
Складні типи даних — це типи, які складаються з елементів, що відносяться до простих типів. До складних типів даних відносяться: масиви; множини; рядки; записи; файли; динамічні змінні; вказівники; лінійні списки (стеки, черги); нелінійні списки (двійкові дерева, несиметричні дерева, тексти, графи); процедурний тип; об'єкти
- Оператори вибору.
Розробимо програму "найпростіший калькулятор" . Будемо використовувати змінну signop із значеннями 1, 2, 3 або 4, що познає знаки операцій відповідно "+", "-", "*", "/". Її значення, отримане в результаті читання, порівнюємо з 1, 2, 3, 4 та виконуємо відповідні їм дії:
if signop=1 then first:=first+second else
if signop=2 then first:=first-second else
if signop=3 then first:=first*second else
{signop=4}
first:=first/second;
Цей оператор задає вибір потрібного оператора з тих, які записано після слів then, залежно від значення змінної signop. Такий вибір у мові Паскаль можна задати інакше, використавши оператор вибору варіантів, або case-оператор (case – англійське "випадок"). У даній програмі він має вигляд:
case signop of
1: first:=first+second;
2: first:=first-second;
3: first:=first*second;
4: first:=first/second
end;
Вираз після слова case (тут це ім'я signop) називається селектором варіантів. Його значення послідовно порівнюється з числами, що "відмічають" оператори-варіанти. Як тільки значення селектора співпаде з числом, буде виконано відповідний оператор, і все закінчиться. Якщо ж значення селектора відрізняється від усіх чисел-відміток варіантів, то жодний із варіантів не виконується.
Селектором може бути довільний вираз будь-якого перелічуваного типу. Варіант може бути відмічений списком із кількох сталих відповідного типу; вони записуються через кому.
6. Оператори циклу.
Цикл — це процес виконання певного набору команд деяку кількість разів. Цикл реалізують або за допомогою конструкції if–goto, або, що значно ефективніше, за допомогою команд циклу. Є три види команд циклів: з параметром, з передумовою та з післяумовою.
1.1. Команда циклу з параметром (for)
параметром – for. Є два різновиди команди for. Розглянемо перший:
for< параметр >:=<вираз 1> to<вираз 2> do <команда 1>;
Тут параметр — це зміна цілого, символьного, логічного або перерахованого типу, а вирази 1 і 2 задають початкове та кінцеве значення параметра.
Дія команди. Параметрові циклу присвоюється значення виразу 1. якщо це значення менше-рівне, ніж значення виразу 2, то виконується команда 1. Після виконання команди 1 значення параметра автоматично збільшується на 1 і знову порівнюється зі значенням виразу 2 і т.д. Коли значення параметра стане більшим, ніж значення виразу 2, то виконується наступна після циклу команда.
Розглянемо другий різновид команди циклу for:
for< параметр >:=<вираз 1> downto<вираз 2> do <команда 1>;
Ця команда діє як попередня, але крок зміни параметра є -1.
1.2. Команда циклу з передумовою (while) має вигляд
while< логічний вираз > do<команда 1>;
Дія команди. Доки значення логічного виразу істинне, виконується команда 1. Істинний логічний вираз описує умову продовження процесу виконання команди циклу.
Приклад. Нехай змінні x, s мають значення х=4, s=0. Після виконання команди
while x<=8 do begin s:=s+x; x:= x +1 end;
вони набудуть значень s=4+5+6+7+8=30, x=9
1.3. Команда циклу з післяумовою (repeat) має вигляд
repit< команди > until< логічний вираз >;
Дія команди. Команди виконуються в циклі, доки значення логічного виразу не стане істинним. Істинний логічний вираз задає умову виходу з циклу.
Приклад. Нехай змінні x, y мають значення х=5, y=0. У результаті виконання команди
Repeaty:=y+x; z:=2*x-2 until x<=1;
Змінні у, z, x набудуть значень у=0+5+3=8, z=6, x=1.
- Робота з одновимірними та багатовимірними масивами.
Масив задає спосіб організації даних. Масивом називають впорядковану сукупність елементів одного типу. Кожен елемент масиву має індекси, що визначають порядок елементів. Число індексів характеризує розмір масиву.
Масив називається одновимірним, якщо для задання місцеположення елемента в масиві необхідно вказати значення лише одного індексу.
Це означає, що наш масив є ще й одновимірним.
Індексом називається порядковий номер елемента масиву.
Масив називається двовимірним, якщо для задання місцеположення елемента в масиві необхідно вказати значення двох індексів.
Запам'ятайте, що у двовимірних масивах перший індекс завжди вказує на номер рядка, а другий - на номер стовпчика в цьому рядку!
- Алгоритми обробки масивів. Упорядкування і пошук даних.
В програмуванні масив (англ. array) — одна з найпростіших структур даних, сукупність елементів одного типу даних, впорядкованих заіндексами, які зазвичай репрезентовані натуральними числами, що визначають положення елемента в масиві.
Масив може бути одновимірним (вектором), та багатовимірним (наприклад, двовимірною таблицею), тобто таким, де індексом є не одне число, а кортеж (сукупність) з декількох чисел, кількість яких збігається з розмірністю масива.
У переважній більшості мов програмування масив є стандартною вбудованою структурою даних.
Алгоритм упорядкування елементів одновимірного масиву.
Розглянемо невпорядкований набір з шести чисел: 3, 5, 6, 4, 2, 1. Ці числа введемо в одновимірний масив.
Завдання. Упорядкувати елементи масиву за зростанням (1, 2, 3, 4, 5, 6) або за спаданням (6, 5, 4, 3, 2, 1) значень.
Метод обміну.
Складемо алгоритм упорядкування елементів цього масиву за зростанням методом обміну, який інакше називають методом «бульбашки». Цей метод полягає в наступному:
розглядають першу пару елементів масиву. Якщо перший елемент більший, ніж другий, то їх міняють місцями. Другий елемент порівнюють з третім і, якщо потрібно, застосовують обмін, і т. ін. — максимальний елемент (тут 6) розташується в кінці масиву, тобто там, де потрібно (порівняння:максимальний елемент переміщується в кінець масиву подібно до бульки, яка, збільшуючись, випливає на поверхню під час кипіння води в чайнику). Після цього знову розглядають масив, але вже без останнього елемента, і застосовують до нього метод обміну — другий за величиною елемент (тут 5)опиниться в масиві на передостанній позиції і т. ін. Якщо масив має n елементів, то метод треба застосувати n - 1 разів кожного разу до меншої кількості елементів. Упорядковані елементи будуть нагромаджуватися в кінці масиву.
Наведемо словесний опис алгоритму розв'язування задачі
1. Порівняти перший елемент з другим. Якщо перший елемент більший, то поміняти їх місцями.
2. Порівняти другий елемент з третім. Якщо другий більший, то поміняти їх місцями і т. ін.
Після такого процесу найбільший елемент розташується в кінці масиву, але попередні елементи ще не будуть упорядковані. Тому треба
3. Повторити пункти 1-2 для п'яти перших елементів.
4. Повторити пункти 1-2 для чотирьох перших елементів.
5. Повторити пункти 1-2 для трьох перших елементів.
6. Повторити пункт 1 для двох перших елементів.
Розгляньте блок-схему даного алгоритму та його запис на навчальній алгоритмічній мові (НАМ) та мові Паскаль.
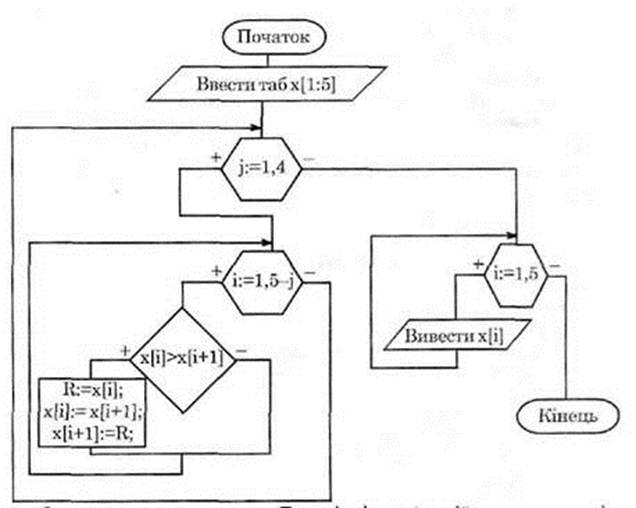
Запишемо даний алгоритм.
Тут змінні R, x[i] — дійсного типу, а змінна і — цілого типу.
програма sort_bubl;
змінні і: цілі;
R: дійсні;
x: масив[1..5] із дійсні;
початок
для і:=1 до 5 виконати
початок
вивести(' Введіть ',і,'-й елемент');
ввести(х[і])
кінець;
для j:=1 до 4 виконати
для i:=1 до 5-j виконати
якщо x[i]> x[i+1] то
початок
R:=x[i];
x[i]:= x[i+1];
x[i+1]:=R
кінець;
для i:=1 до 5 виконати
вивести (x [i])
кінець.
Перекладемо цей алгоритм мовою Паскаль.
program Sort;
const n = 7;
а : array [l..n] of integer = (75, 34, 18, 56, 45, 64, 23);
var і, j : integer;
dop : integer;
begin
for j := 1 to n - 1 do
for і := 1 to n - j do
if a[i] > a[i+1] then
begin
dop := a[i+1]; a[i+1] := a[i]; a[i] := dop
end;
writeln('виводимо результати');
for і := 1 to n do write(a[i] : 4)
end.
Інші методи впорядкування масивів.
Окрім алгоритму впорядкування масиву методом обміну, є чимало інших методів упоряд кування. Найпростіший (але найтриваліший) — цеметод мінімальних елементів. Цей метод полягає в такому: розглядають увесь масив, визначають мінімальний елемент та його номер і міняють його місцями з першим елементом. Розглядають масив без першого елемента. Застосовують до нього метод і так n -1 разів. Упорядковані елементи будуть поступово переноситися на початок масиву.
Інший метод упорядкування — метод вставки. У цьому випадку розглядають увесь масив, і перший елемент порівнюють з іншими, доки не знайдуть меншого від нього. Перша позиція в масиві стає позицією вставки. Знайдений менший елемент і його індекс запам'ятовують. Усі елементи масиву, починаючи від позиції вставки до того, що передує знайденому, зміщують праворуч. Значення знайденого елемента записують у позицію вставки і порівнюють його з елементами, що залишилися. Якщо буде виявлено ще менший елемент, то повторюють процедуру вставки і так доти, доки не дійдуть до кінця масиву — лише після цього перший елемент буде на місці. Розглядають масив без першого елемента і застосовують до нього описаний метод і т.п.
Обидва описані алгоритми вважаються простішими, ніж метод обміну, але менш ефективними, оскільки потребують більшої кількості операцій.
Лінійний пошук - алгоритм послідовного пошуку знаходження заданого значення довільної функції на деякому її відрізку. Цей алгоритм є найпростішим алгоритмом пошуку і на відміну, наприклад, від двійкового пошуку, не накладає жодних обмежень на функцію і має просту реалізацію. Пошук значення функції здійснюється простим порівнянням чергового розглянутого значення (як правило пошук відбувається зліва направо, тобто від менших значень аргументу до більших) і, якщо значення збігаються (з тією або іншою точністю), то пошук вважається завершеним.
Даний алгоритм порівнює кожен елемент масиву з певним ключем.
- Символьні рядки. Обробка текстових даних.
Мова С не має спецiального типу для оголошення символьних рядкiв, а розглядає символьний рядок як особливий вид масиву. Елементи масиву, який називають символьним рядком, мають тип char, їх значеннями є коди символiв, з яких складається цей рядок. Процеси опрацювання символьних рядкiв у С-програмах базуються на двох основних властивостях рядкiв:
1) iм’я символьного рядка є константним вказiвником на його перший символ;
2) кiнець рядка задається нуль-символом ‘\ 0’.
Бiблiотеки мови С мiстять набiр функцій, призначених для введення та виведення одиночних символiв i цiлих символьних рядкiв. Функцiї введення/виведення, прототипи яких оголошено в заголовному файлi <stdio.h>, належать до стандартних функцiй мови - вони є в усiх реалiзацiях С. Цi функції здiйснюють потокоорiєнтоване буферизоване введення/виведення даних. У процесi введення набрана на клавiатурi iнформацiя заноситься у спецiальний внутрiшнiй буфер i одночасно вiдображається на екранi. Додатковi можливостi надають функції консольного введення/виведення, які оголошено в заголовному файлi <conio.h>. Прототипи бiблiотечних функцiй, призначених для роботи з символьними рядками, оголошенi в заголовному файлi <string.h>.
Як уже згадувалось, в мові Pascal є два види текстових даних: символічні (char) та рядкові (string).
Для роботи з символічними даними є функції: Chr та Ord.
Функція Chr за кодом виробляє відповідний символ, наприклад, результатом функції Chr(66) буде символ ‘B’.
Функція Ord виробляє код свого аргументу: значенням функції Ord(‘B’) буде число 66.
Символічні дані можна об’єднувати в масив, наприклад:
Var P: array[1..50] of char;
Фактично P – це рядок з 50 символів. Його можна ввести в циклі.
Спеціальна функція Length(T) повертає ціле число – кількість символів в рядку. Рядок можна ввести з клавіатури за допомогою оператора Readln.
Наприклад:
Readln(Т);
Для рядкових даних допустима операція зчеплення, наприклад:
Q:=’ Великий ‘ + ‘ Дніпро ‘;
Але можливий і такий варіант:
LivePole:=’‘; {це пустий рядок}
For i:=1 to k do LivePole:= LivePole+’ ‘;
Після завершення циклу змінна LivePole буде мати k проміжків.
Для обробки даних типу String використовують спеціальні підпрограми.
Процедура Insert(S1, S2, Npoz) вставляє рядок S1у рядок S2, починаючи з позиції Npoz.
Приклад:
S2:=’ Приватизація ‘;
Insert (‘х’ , S2, 4); {в S2 буде – Прихватизація}
Процедура Delete(S1, Npoz, Kil) вилучає з рядку S1 підрядок із Kil символів, починаючи з позиції Npoz.
Приклад:
S1 := ‘Закріпити’;
Delete (S1,3,3); {в S1буде - запити}
Функція Copy(S1, Npoz,Kil) виконує копіювання послідовності із Kil символів з позиції Npoz рядку S1.
Приклад:
S2:=Copy(‘Металіст’,5,3); {в S2 буде – ліс}
Функція Pos(S1, S2) шукає в S2 (з лівого краю) підрядок S1. Результатом функції є ціле число – номер позиції, починаючи з якої підрядок S1 перший раз входить до S2. Якщо S1 в S2 немає, результат дорівнює нулю.
Приклад:
S2:=’ Влада чи Безвладдя‘;
Nom:=Pos(‘ ‘,S2); {Nom стане рівним 6}
Щоб знайти у тексті місце другого проміжку, треба щось зробити з першим, наприклад, замінити його на ‘*’.
S2[Pos(‘ ‘,S2)]:=’*’;
Функція Concat(S1,S2,…,SN) виконує зчеплення рядків S1, S2,…,SN в один рядок.
Приклад: Підрахувати кількість слів у заданому реченні.
Var s:String;
i,j:Byte;
Begin
Write('Input line : ');
Readln(s);
s:=s+' ';
j:=0;
For i:=2 to Length(s) do
If (s[i]=' ')and(s[i-1]<>' ') Then j:=j+1;
Writeln('Result = ',j);
End.
- Робота із записами.
Типізований файл являє собою файл з компонент певного типу, які називаються записами.
Запис - це структура даних, що складається з фіксованого числа компонентів, названих полями. Поля можуть бути різних типів. Кожному полю задається ім’я, так званий ідентифікатор поля. Ідентифікатор поля використовується при організації доступу до компонентів запису.
Визначення типу запису починається зарезервованим словом record (запис), за ним іде список полів запису. Наприкінці списку полів запису ставиться зарезервоване слово end (кінець).
Список полів являє собою послідовність розділів запису, відділених друг від друга крапкою з комою. Кожний розділ складається з одного або декількох ідентифікаторів, що відокремлюються один від одного комами, слідом за якими іде або двокрапка, або ідентифікатор типу, або опис типу (дескриптор). Таким чином, кожний розділ запису визначає тип одного або декількох полів.
- Файли. Поняття фізичного і логічного файлу. Методи доступу до файлів.
Файл - це одномірний масив байтів, що має як мінімум один твердий зв'язок (ім'я файлу). Файли можуть містити інформацію у двійковому або в текстовому виді. Файли містять дані, сценарії оболонки або програми. Крім того, деякі імена файлів являють собою такі абстрактні об'єкти, як сокети й драйвери пристроїв.
При роботі з файлами існує певний порядок дій, якого необхідно дотримуватися. От всі ці дії:
-Створення (опис) файлової змінної;
-Зв'язування цієї змінної з конкретним файлом на диску або із пристроєм вводу-висновку (екран, клавіатура, принтер і т.п.);
-Відкриття файлу для запису або читання;
-Дії з файлом: читання або запис;
-Закриття файлу.


- Типи файлів.
Програмування доступу до файлу в язиці Turbo Pascal починається з опису файлової змінної (змінної файлового типу). Цей опис будується за допомогою службового слова file, після якого може бути зазначений тип окремих елементів файлу.
Залежно від способу опису можна виділити текстові файли, двійкові або типізовані й нетипизовані. Вид файлу визначає спосіб зберігання інформації у файлі.
Текстовий файл є файлом послідовного доступу, і його можна представити як набір рядків довільної довжини. Логічно послідовний файл можна представити як іменований ланцюжок байтів, що має початок і кінець. Послідовний файл відрізняється від файлів з іншою організацією тим, що читання (або запис) з файлу (у файл) ведуться байт за байтом від початку до кінця.
Також існують так називані "типізовані" файли, тобто файли, що мають тип. Цей тип визначає, якого роду інформація втримується у файлі й задається в параметрі.
Нетипизований файл - файл, у якому ми вказуємо як тип файлу просто File, тобто без типу.
Те одержуємо "нетипизований" файл, читання й запис у який відрізняється від роботи з файлами інших типів. Ці дії виробляються шляхом вказівки кількості байт, які потрібно прочитати, а також вказівкою області пам'яті, у яку потрібно прочитати ці дані.
Кожній програмі доступні два стандартних файли input (клавіатура) і output (екран). Це - текстові файли. Будь-які інші файли стають доступними після виконання спеціальних процедур.
Любий файл має три характерні риси. По-перше, у нього є ім'я, що дає можливість програмі працювати одночасно з декількома файлами. По-друге, він містить компоненти одного типу. По-третє, довжина знову створюваного файлу ніяк не обмовляється при його оголошенні й обмежується тільки ємністю пристроїв пам'яті.
Відкриття файлу - це вже більше ускладнений процес, ніж зв'язування з ним змінної. Тут ураховується, навіщо відкривається файл - для запису або читання, а також залежно від типу файлу процедури виконують різні дії.
- Процедури і функції для роботи з файлами.
Файл - це одномірний масив байтів, що має як мінімум один твердий зв'язок (ім'я файлу). Файли можуть містити інформацію у двійковому або в текстовому виді. Файли містять дані, сценарії оболонки або програми. Крім того, деякі імена файлів являють собою такі абстрактні об'єкти, як сокети й драйвери пристроїв.
Передбачено безліч функцій для роботи з файлами. Більшість цих функцій можна віднести до однієї з наступних двох категорій:
Функції для створення файлів.
Функції для керування файлами.
Наприклад у паскалі робота з файлами здійснюється через спеціальні типи. Це файлові типи, які визначають тип файлу, тобто фактично вказують його вміст.
За допомогою цієї змінної, котрої привласнений необхідний тип, і здійснюється вся робота з файлами - відкриття, запис, читання, закриття й т.п.
При роботі з файлами існує певний порядок дій, якого необхідно дотримуватися. От всі ці дії:
Створення (опис) файлової змінної;
Зв'язування цієї змінної з конкретним файлом на диску або із пристроєм вводу-висновку (екран, клавіатура, принтер і т.п.);
Відкриття файлу для запису або читання;
Дії з файлом: читання або запис;
Закриття файлу.
Програмування доступу до файлу в язиці Turbo Pascal починається з опису файлової змінної (змінної файлового типу). Цей опис будується за допомогою службового слова file, після якого може бути зазначений тип окремих елементів файлу.
Залежно від способу опису можна виділити текстові файли, двійкові або типізовані й нетипизовані. Вид файлу визначає спосіб зберігання інформації у файлі.
Текстовий файл є файлом послідовного доступу, і його можна представити як набір рядків довільної довжини. Логічно послідовний файл можна представити як іменований ланцюжок байтів, що має початок і кінець. Послідовний файл відрізняється від файлів з іншою організацією тим, що читання (або запис) з файлу (у файл) ведуться байт за байтом від початку до кінця.
Також існують так називані "типізовані" файли, тобто файли, що мають тип. Цей тип визначає, якого роду інформація втримується у файлі й задається в параметрі.
Нетипизований файл - файл, у якому ми вказуємо як тип файлу просто File, тобто без типу.
Те одержуємо "нетипизований" файл, читання й запис у який відрізняється від роботи з файлами інших типів. Ці дії виробляються шляхом вказівки кількості байт, які потрібно прочитати, а також вказівкою області пам'яті, у яку потрібно прочитати ці дані.
Кожній програмі доступні два стандартних файли input (клавіатура) і output (екран). Це - текстові файли. Будь-які інші файли стають доступними після виконання спеціальних процедур.
Любий файл має три характерні риси. По-перше, у нього є ім'я, що дає можливість програмі працювати одночасно з декількома файлами. По-друге, він містить компоненти одного типу. По-третє, довжина знову створюваного файлу ніяк не обмовляється при його оголошенні й обмежується тільки ємністю пристроїв пам'яті.
Відкриття файлу - це вже більше ускладнений процес, ніж зв'язування з ним змінної. Тут ураховується, навіщо відкривається файл - для запису або читання, а також залежно від типу файлу процедури виконують різні дії.
Цей процес полягає у використанні однієї із трьох наявних процедур:
1. Відкриття файлу на читання. Це може бути текстовий, типізований або не типізований файл. У випадку з текстовим файлом, він відкривається тільки на читання. У випадку з типізованим і не типізованим файлом - він відкривається на читання й запис.
2. Процедура відкриття текстового файлу на запис. Вище було сказано, що при завданні параметра типу Text не дозволить писати в нього дані, відкривши файл лише для читання. Тобто якщо використається текстовий файл і необхідно робити в нього запис, використовується ця процедура.
3. Процедура створення нового файлу або перезаписування існуючого.
Читання файлів. Читання файлів виробляється за допомогою відмінно відомих нам процедур Read і Readln. Вони використаються також, як і при читанні інформації із клавітури. Відмінність лише в тім, що перед змінної, у яку міститься лічене значення, указується змінна файлового типу (дескриптор файлу).
Запис у файли вироблятися точно так само, як і запис на екран - за допомогою процедур Write і Writeln. Як і у випадку із читанням, перед записуваною у файл змінної вказується дескриптор файлу.
TURBO PASCAL уводить ряд процедур і функцій, застосовних для будь-яких типів файлів: Assign, Reset, Rewrite, Close, Rename, Erase, Eof,
Процедура Assign зв'язує логічний файл із фізичним файлом, повне ім'я якого задане в рядку FileName.
Процедура Reset відкриває логічний файл для наступного читання даних або, як говорять, відкриває вхідний файл. Після успішного виконання процедури Reset файл готовий до читання з нього першого елемента.
Процедура Rewrite відкриває логічний файл для наступного запису даних. Після успішного виконання цієї процедури файл готовий до запису в нього першого елемента.
Процедура Close закриває відкритий до цього логічний файл. Виклик процедури Close необхідний при завершенні роботи з файлом.
Логічна функція EOF Boolean повертає значення TRUE, коли при читанні досягнуть кінець файлу. Це означає, що вже прочитано останній елемент у файлі або файл після відкриття виявився порожній.
Процедура Rename дозволяє перейменувати фізичний файл на диску, пов'язаний з логічним файлом. Перейменування можливо після закриття файлу.
Процедура Erase знищує фізичний файл на диску, що був пов'язаний з файлової змінної. Файл до моменту виклику процедури Erase повинен бути закритий.
Пример. Запись текстового файла на диск и ввод в него текста.
program wtf;
type fil=text;
var f1:fil; name:string[35]; txt:string;
begin
write('Введите имя файла для записи текста>');
readln(name);
writeln;
assign(f1,name);
rewrite(f1);
writeln('Введите текст для записи (для окончания-Enter):');
writeln;
repeat
write(':>');
readln(txt);
writeln(f1,txt);
until txt='';
close(f1);
writeln;
writeln('Ввод окончен, нажмите Enter.');
readln;
end.
- Поняття підпрограми. Структура підпрограм.
Підпрограми призначені для реалізації окремих частин деякої складної задачі. Вони дають змогу реалізувати концепцію структурного програмування, суть якого полягає у розкладанні складної задачі на послідовність простих підзадач і у для алгоритмів розв'язування кожної задачі відповідних підпрограм.
В двох словах: підпрограми існують, щоб полегшувати життя програмісту.
Розрізняють 2 типи підпрограм:
підпрограми-процедури
підпрограми-функції
Підпрограми поділяються на:
стандартні
підпрограми користувача
Підпрограми користувача - це поіменована група команд, яку створюють і описують в основній прогрвамів розділах procedure або function. До підпрограми можна звернутись з будь-якого місця програми і будь-яку кількість раз.
В мові Паскаль використовується два види підпрограм - процедури та функції. Вони відрізняються між собою структурою та способом виклику.
При проектуванні програми визначається, які частини алгоритму треба реалізувати як процедури, а де знадобиться функція. В головній частині програми підпрограми розташовуються після розділу опису даних перед оператором Begin, а викликаються при потребі в процесі виконання головної програми або іншої підпрограми.
Структура процедури має вигляд:
Procedure ім’я (список формальних параметрів);
Розділ локальних даних
Begin
... {розділ виконавчих операторів}
End;
Перший рядок складає заголовок процедури, ім’я процедури вибирає програміст так як і ім'я змінної. В списку формальних параметрів описуються через ; параметри та інформація про їх тип. Деякі параметри призначені для передачі даних в процедуру, інші для повернення результатів з процедури до тієї програмної одиниці, яка її викликала.
В розділі локальних даних (який взагалі може бути відсутнім) описують ті дані, які використову ються тільки для «службових» цілей в самій процедурі (параметри циклів, робочі змінні та маси ви, тощо).
Всередині підпрограми записують послідовність операторів, які реалізують потрібний алгоритм. При цьому вони працюють з формальними параметрами, локальними та глобальними даними.
Зв'язок між окремими частинами програми здійснюється через списки формальних параметрів та за допомогою глобальних змінних.
Глобальні дані описуються в головній програмі вони не являються фактичними параметрами при виклику підпрограм, не описані в підпрограмах, а використовуються в одній з них і в головній програмі.
Результати роботи підпрограми можуть бути передані до головної програми через формальні параметри та глобальні дані.
Приклад. Програма обчислення суми десяткових цифр.
Програма:
Const N=5;
Var X:Array [1..N] of Integer;
SumX, Kill,I : Integer;
Procedure Sum(A:Integer; Var ISum:Integer);
Begin
ISum:=0;
While A<>0 do
Begin
Kill:=Kill+1;
ISum:=ISum+Abs(A) mod 10;
A:=A div 10;
End;
End;
Begin
Writeln(‘Введіть масив’);
For I:=1 to N do Read(X[i]);
Kill:=0;
For I:=1 to N do
Begin
Sum(X[I], SumX);
Writeln(X[I]:6, SumX:4);
End;
Writeln(‘Загальна кількість цифр’, Kill);
End.
Підпрограми-функції використовуються для реалізації алгоритму та повернення в головну програму одного результату в вигляді імені функції.
Ім'я функції вибирається довільно (як ім'я змінної).
Структура функції:
Function ім'я(список формальних параметрів): тип імені;
{локальні дані}
Begin
...
ім'я := ...;
...
End;
Типом функції може бути скалярний тип, тобто: цілий, дійсний, логічний, символьний та рядковий тип String.
Відносно формальних параметрів, локальних та глобальних даних в функції діють такі ж самі обмеження та вимоги, що і в процедурах.
В виконавчій частині підпрограми-функції повинен бути хоча б один оператор в якому імені функції: призначається значення.
Звернення до функції виконується з якого-небудь арифметичного виразу так, як і до стандартних функцій тину sin(x), ln(x), тощо. Результат роботи функції передається в місце її виклику.
Приклад. Використання функції для обчислення степені.
Програма:
Var x,y,z : Real ;
Function Step(a:real; b:real):real;
Begin
If a<=0 then
Begin
Writeln( 'перевірте дані');
Halt(0);
End;
If b=0 then Step:=1
else Step:=exp(b*ln(a));
End;
Begin
Readln(x:y);
Z:=Step(x,y)+Step(y,x);
Writeln(x,y,z);
End.
- Параметри в підпрограмах. Глобальні та локальні змінні.

Для організації підпрограм використовуються процедури та функції.
На сьогоднішньому уроці зупинимося на процедурах.
Процедура – це спеціальна незалежна частина програми, яка має своє ім'я, містить команди для виконання деякої послідовності дій і може використовуватися неодноразово.
Переваги підпрограм:
- полегшення розробки великих і складних програм;
- економія пам'яті (пам'ять для змінних виділяється тільки на час роботи підпрограми).
Щоб до процедури можна було звернутися з основної програми, її слід описати. Опис процедури розміщується у програмі після розділу опису змінних.
Форма запису:


Процедура нагадує звичайну програму, яка має заголовок і тіло, але починається не зі слова Рrogram, а зарезервованого слова і закінчується не крапкою, а крапкою з комою.
Після слова Procedure пишемо ідентифікатор (повторюємо правила запису ідентифікаторів)
Після назви (заголовка, імені, ідентифікатора) процедури йде необов’язковий список формальних параметрів.
Параметри в заголовку процедури використовуються для обміну інформацією між процедурою і програмою, яка її викликає. Вони визначають дані, які передаються на обробку до процедури, і дані, які отримуються у вигляді результатів.
Формальний параметр необов’язковий, якщо аргумент процедури не повертається в програму, яка його викликала.
Якщо ж він є, то в ньому повинні бути перераховані імена формальних параметрів і їх типи, який укладається у круглі дужки. У списку формальних параметрів змінні оголошують із зазначенням кожного типу, які повертатимуть результати обчислень у головну програму, і має бути словоvar.
- Рекурсивні підпрограми.
Часто кажуть, що рекурсивне означення – це коли щось означається з його ж допомогою. Фраза ця не зовсім точна, а вірніше, зовсім неточна. Кожнеозначення задає щось, і цим чимось є, як правило, об'єкти, що утворюють деяку множину.
Означення називається рекурсивним, якщо воно задає елементи множини за допомогою інших елементів цієї ж множини. Об'єкти, задані рекурсивним означенням, також називаються рекурсивними. Нарешті, рекурсія – це використання рекурсивних означень.
За правилами мови Паскаль щодо області дії означень, тіло підпрограми може мiстити виклики підпрограм, чиї заголовки записані вище в тексті програми. Звідси випливає, що підпрограма може містити виклики самої себе – рекурсивні виклики. Виконання такого виклику нічим не відрізняється від виконаннявиклику будь-якої іншої підпрограми. Підпрограма з рекурсивними викликами називається рекурсивною.
Приклад 9.6. Напишемо рекурсивну функцію f за таким означенням функції "факторіал": n!=n× (n-1)! за n>1, 1!=1 (вважається, що n>0).
functionf ( n : integer ) : integer;
Begin
ifn = 1 thenf := 1
elsef := n * f ( n-1 )
end; ç
При імітації виконання викликів рекурсивних підпрограм їх локальні змінні позначають у такий спосіб. Якщо підпрограма F викликана з програми, то її локальна змінна X позначається F.X. За виконання кожного рекурсивного виклику підпрограми F, указаного в її тiлi, з'являється нова змiнна X. Вона позначається дописуванням префікса "F." до позначення змінної X у попередньому виклику: F.F.X, F.F.F.X тощо.
Приклад 9.7. Імітацію виконання виклику f(2) функції з прикладу 9.6 можна податі таблицею:
| що виконується
| стан пам'яті
|
| Виклик f(2)
| f.n
| f.f
|
|
|
| ?
|
| обчислення n=1: false
|
| ?
|
| початок f := n*f(1)
|
| ?
|
| виклик f(1)
|
| ?
| f.f.n
| f.f.f
|
|
|
| ?
|
| ?
|
| обчислення n=1: true
|
| ?
|
| ?
|
| f := 1
|
| ?
|
|
|
| повернення з виклику f(1)
|
| ?
|
| закінчення f := n*f(1)
|
|
|
| | | | | | |
Приклад 9.8.Найбільший спiльний дільник НСД(a,b) натуральних a і b можна обчислити рекурсивно на основі таких рівностей:
якщо b = 0, то НСД(a, b) = a,
якщо a mod b = 0, то НСД(a, b) = b,
якщо a mod b > 0, то НСД(a, b) = НСД( b, a mod b ).
Цьому означенню відповідає така рекурсивна функція обчислення НСД:
function GCD ( a, b : integer) : integer;
{ Greatest Common Divisor – Найбільший Спiльний Дільник}
Begin
ifb=0 then GCD:=a else
if a mod b=0 then GCD := b
else GCD := GCD ( b, a mod b)
end;
ç
З рекурсивними підпрограмами пов'язано два важливих поняття – глибина рекурсії та загальна кількість викликів, породжених викликом рекурсивної підпрограми.
Розглянемо перше з них. У прикладі 9.6 наведено функцію обчислення n!. Очевидно, що її виклик із аргументом, наприклад, 4, закінчується лише після закінчення виклику з аргументом 3, а той, у свою чергу, після виклику з аргументом 2 тощо. Такі виклики називаються вкладеними. Отже, виклик із аргументом 4 породжує ще три вкладені виклики.
Взагалі, за виклику з аргументом n породжується ще n-1 виклик, і загальна кількість незакінчених викликів досягає n. Отже, максимальна кількість незакінчених рекурсивних викликів при виконанні виклику підпрограми називається глибиною рекурсії цього виклику.
За виконання виклику з глибиною рекурсії m одночасно "існують" m екземплярів локальної пам'яті. Кожний екземпляр має певний розмір, і якщо глибина буденадто великою, то автоматичної пам'яті, яку надано процесу виконання програми, може не вистачити.
Друге поняття можна назвати загальною кількістю вкладених викликів, породжених викликом рекурсивної підпрограми. Ця кількість значною мірою впливає на час виконання виклику. Проілюструємо це наступним прикладом.
Приклад 9.9. За властивостями трикутника Паскаля, біноміальний коефіцієнт C(m,n)=1 при m£ 1або n=0 або n=m; у противному разі
C(m,n)=C(m-1,n-1)+C(m-1,n).
Згідно цього означення напишемо рекурсивну функцію обчислення за m, n, де 0£ n£ m,біноміального коефіцієнта C(m,n):
function C(m, n : integer) : integer;
Begin
if (m<=1) or (n=0) or (n=m) then C:=1
else C:= C(m-1, n-1)+C(m-1, n)
end;
Як бачимо, кожний виклик, у якому значення аргументів m>1, 0<n<m, породжує два вкладені виклики. У результаті відбуваються повторні обчислення тих самих величин. Наприклад, виконання виклику з аргументами (5,2) веде до того, що виклик із аргументами (3,1) виконується двічі, з аргументами (2,1), (1,0) та (1,1) – по тричі, а загальна кількість вкладених викликів сягає 18.
Неважко збагнути, що чим більше m і чим ближче n до m/2, тим більшою буде загальна кількість вкладених викликів. Ми не будемо точно означати її залежність від аргументів. Скажемо лише, що за n=mdiv2 або n=mdiv2+1 вона більше, ніж 2m/2. Наприклад, за m=60 це 230, або приблизно 109. Якщо навіть припустити, що за секунду можна виконати 106 викликів, то треба більше 1000 секунд, тобто приблизно 20 хвилин. Проте неважко написати рекурсивну функцію, виклик якої з аргументом m породжує не більше, ніж m/2 вкладених викликів (задача 9.7).
Отже, вживання рекурсивних підпрограм вимагає обережності та вміння оцінити можливу глибину рекурсії та загальну кількість викликів. Не завжди слід писати рекурсивні підпрограми безпосередньо за рекурсивним означенням. Принаймні, для обчислення біноміальних коефіцієнтів узагалі краще скористатися циклом (розділ 5.2). Справа в тім, що виконання кожного виклику підпрограми потребує додаткових дій комп'ютера, описаних у розділі 8. Тому "циклічний" варіант описання обчислень виконується, як правило, швидше від рекурсивного. Також не слід уживати рекурсію для обчислення елементів рекурентних послідовностей. За великої глибини рекурсії це взагалі може призвести до вичерпання автоматичної пам'яті та аварійного завершення програми.
У цьому розділі ми розглядаємо лише так звану пряму рекурсію, коли підпрограма містить виклики самої себе. У програмуванні зустрічається також і непряма рекурсія, коли підпрограма містить виклики інших підпрограм, а ті – виклики цієї підпрограми.
- Динамічні структури даних. Незв’язані динамічні дані.