Традиційно вважається, що саме цей напрям виник від початкових витоків штучного інтелекту, однак в теперішній час він практично виділився окрему самостійну науку. Її основним підходом є опис класів об’єктів через певні значення визначних ознак. У відповідність кожному об’єкту ставиться матриця ознак, за якою відбувається його розпізнавання. Процедура розпізнавання використовує здебільшого спеціальні математичні процедури та функції, що розподіляють об’єкти на класи. Цей напрям є близьким до машинного навчання та тісно пов’язаний з нейрокібернетикою [Довідник зі ШІ, 1990].
3. Дані та знання
Під час вивчення інтелектуальних систем зазвичай виникає питання – що є знаннями і у чому полягає їх відмінність від звичайних даних, що їх ЕОМ обробляє вже протягом не одного десятиліття. Для того, щоб отримати відповідь, проаналізуймо декілька робочих визначень.
Дані — це окремі факти, що характеризують окремі факти, процеси та явища предметної області, а також їх властивості.
Трансформація даних в процесі їх обробки ЕОМ відбувається в декілька умовних етапів:
D1 — дані як результат вимірювань та спостережень;
D2 — дані на матеріальних носіях інформації (таблиці, протоколи, довідники);
D3 — моделі (структури) даних у вигляді діаграм, графіків, функцій;
D4 — дані в комп’ютері на мові опису даних;
D5 — бази даних на машинних носіях інформації
Знання ґрунтуються на даних, що отримані емпіричним шляхом. Вони є результатом розумової діяльності людини, яка спрямована на узагальнення отриманого в процесі практичної діяльності досвіду.
Знання — це отримані в результаті практичної діяльності та професійного досвіду закономірності предметної області (принципи, зв’язки, закони), що дозволяють спеціалістам ставити та вирішувати задачі в цій галузі.
Під час обробки на ЕОМ знання трансформуються аналогічно даним.
Z1 — знання в пам’яті людини як результат мислення;
Z2 — матеріальні носії знань (підручники, методичні посібники);
Z3 — поле знань — умовний опис основних об’єктів предметної області, а також атрибутів та закономірностей, що їх пов’язують;
Z4 — знання, що описані мовами представлення (продукційні мови, семантичні мережі, фрейми – див. далі);
Z5 — база знань на машинних носіях інформації.
Широко використовується також наступне визначення знань: Знання — це добре структуровані дані, або дані про дані, або метадані.
Існує безліч способів визначити поняття. Одним з найбільш уживаних є спосіб, що ґрунтується на ідеї інтенсіоналу.
Інтенсіонал поняття — це визначення його через співвідношення з поняттям більш високого рівня абстракції із зазначенням його специфічних властивостей. Інтенсіонали формулюють знання про об’єкти. Інший спосіб визначає поняття шляхом співвідношення його з поняттями більш низького рівня абстракції або шляхом перелічення фактів, що стосуються об’єкту, який має бути визначений. Цей спосіб є визначенням за даними, або екстенсіоналом поняття.
Приклад 1.1.
Поняття «персональний комп’ютер». Його інтенсіоналом є: "Персональний комп’ютер — це дружня ЕОМ, яку можна придбати менше, ніж за $2000-3000 та встановити на стіл".
Екстенсіоналом цього поняття є: «Персональний комп’ютер — це Mac, IBM PC, Sinkler...»
Для зберігання даних використовують бази даних - їм притаманний великий обсяг та відносно невелика питома вартість інформації. Для зберігання знань застосовують бази знань – попри доволі невеликий обсяг, вартість інформаційних масивів є винятково високою. База знань — це основа будь-якої інтелектуальної системи. Знання можна класифікувати за наступними категоріями:
• Поверхові — знання про видимі, наочні взаємозв’язки між окремими подіями та фактами предметної області.
• Глибинні — абстракції, аналогії, схеми, що відбивають структуру та природу процесів, що відбуваються в предметній області. Ці знання пояснюють явища і можуть бути використані для прогнозування поведінки об’єктів.
Приклад 1.2.
Поверхові знання: "Якщо натиснути кнопку дзвінка - пролунає звук. Якщо непокоїть головний біль - слід випити аспірин".
Глибинні знання: "Принципова електрична схема дзвінка та проведення. Знання фізіологів та лікарів високої кваліфікації про причини, види головного болю, та про методи його лікування".
Сучасні експертні системи працюють переважно з поверховими знаннями. Це пояснюється відсутністю на даний момент методик, що дозволили би виявляти глибинні структури знань та працювати з ними.
Крім вищезгаданих, в підручниках зі ШІ знання традиційно поділяють на процедурні та декларативні. Історично процедурні, тобто “розчинені” в алгоритмах, знання є первинними. Вони керували даними. Для їх зміни потрібно було змінювати програми. Однак, в процесі розвитку штучного інтелекту пріоритет даних поступово змінювався, дедалі більша частина знань була зосереджена в структурах даних (таблиці, списки, абстрактні типи даних), тобто роль декларативних знань ставала більш значною.
Сьогодні знання набули суто декларативної форми, тобто знаннями вважаються речення, які записані наближеними до природних та зрозумілими для неспеціалістів мовами представлення знань.
4. Моделі представлення знань
Існують десятки моделей (або мов) Существуют десятки моделей (или языков) представления знаний для различных предметных областей. Большинство из них может быть сведено к следующим классам:
• продукционные модели;
• семантические сети;
• фреймы;
• формальные логические модели.
Продукционная модель
Продукционная модель или модель, основанная на правилах, позволяет представить знания в виде предложений типа«Если (условие),то (действие)».
Под «условием» (антецедентом) понимается некоторое предложение-образец, по которому осуществляется поиск в базе знаний, а под «действием» (консеквен-том) — действия, выполняемые при успешном исходе поиска (они могут быть промежуточными, выступающими далее как условия и терминальными или целевыми, завершающими работу системы).
Чаще всего вывод на такой базе знаний бывает прямой (от данных к поиску цели) или обратный (от цели для ее подтверждения — к данным). Данные — это исходные факты, хранящиеся в базе фактов, на основании которых запускается машина вывода или интерпретатор правил, перебирающий правила из продукционной базы знаний (см. далее).
Продукционная модель чаще всего применяется в промышленных экспертных системах. Она привлекает разработчиков своей наглядностью, высокой модульностью, легкостью внесения дополнений и изменений и простотой механизма логического вывода.
Имеется большое число программных средств, реализующих продукционный подход (язык OPS 5; «оболочки» или «пустые» ЭС — EXSYS Professional, Kappa, ЭКСПЕРТ; ЭКО, инструментальные системы ПИЭС [Хорошевский, 1993] и СПЭИС [Ковригин, Перфильев, 1988] и др.), а также промышленных ЭС на его основе (например, ЭС, созданных средствами G2 [Попов, 1996]) и др.
Семантические сети
Термин семантическая означает «смысловая», а сама семантика — это наука, устанавливающая отношения между символами и объектами, которые они обозначают, то есть наука, определяющая смысл знаков.
Семантическая сеть — это ориентированный граф, вершины которого — понятия, а дуги — отношения между ними.
В качестве понятий обычно выступают абстрактные или конкретные объекты, а отношения — это связи типа: «это» («АКО — A-Kind-Of», «is»), «имеет частью» («has part»), «принадлежит», «любит». Характерной особенностью семантических сетей является обязательное наличие трех типов отношений:
• класс — элемент класса (цветок — роза);
• свойство — значение (цвет — желтый);
• пример элемента класса (роза — чайная).
Можно предложить несколько классификаций семантических сетей, связанных с типами отношений между понятиями.
По количеству типов отношений:
• Однородные (с единственным типом отношений).
• Неоднородные (с различными типами отношений). По типам отношений:
• Бинарные (в которых отношения связывают два объекта).
• N-арные (в которых есть специальные отношения, связывающие более двух понятий). Наиболее часто в семантических сетях используются следующие отношения:
• связи типа часть — целое, класс — подкласс, элемент —множество, и т. п.;
• функциональные связи (определяемые обычно глаголами «производит», «влияет»...);
• количественные (больше, меньше, равно...);
• пространственные (далеко от , близко от, за, под, над...);
• временные (раньше, позже, в течение...);
• атрибутивные связи (иметь свойство, иметь значение);
• логические связи (И, ИЛИ, НЕ);
• лингвистические связи и др.
Проблема поиска решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, отражающей поставленный запрос к базе.
Пример 1.3.
На рис. 1.1 изображена семантическая сеть. В качестве вершин тут выступают понятия «человек», «т. Иванов», «Волга», «автомобиль», «вид транспорта» и «двигатель».
Данная модель представления знаний была предложена американским психологом Куиллианом. Основным ее преимуществом является то, что она более других соответствует современным представлениям об организации долговременной па-мяти человека [Скрэгг, 1983].
Недостатком этой модели является сложность организации процедуры поиска и вывода на семантической сети.
Для реализации семантических сетей существуют специальные сетевые языки, например NET [Цейтин, 1985], язык реализации систем SIMER+MIR [Осипов, 1997] и др. Широко известны экспертные системы, использующие семантичес-кие сети в качестве языка представления знаний — PROSPECTOR, CASNE' TORUS [Хейес-Рот и др., 1987; Durkin, 1998].
Фреймы
Термин фрейм (от английского frame, что означает «каркас» или «рамка») был предложен Маренном Минским [Минский, 1979], одним из пионеров ИИ, в 70-е годы для обозначения структуры знаний для восприятия пространственных сцен. Эта модель, как и семантическая сеть, имеет глубокое психологическое oбоснование.
Фрейм — это абстрактный образ для представления некоего стереотипа восприятия.
В психологии и философии известно понятие абстрактного образа. Например, произнесение вслух слова «комната» порождает у слушающих образ комнаты: «жилое помещение с четырьмя стенами, полом, потолком, окнами и дверью, площадью 6-20 м2». Из этого описания ничего нельзя убрать (например, убрав окна, мы получим уже чулан, а не комнату), но в нем есть «дырки» или «слоты» — это незаполненные значения некоторых атрибутов — например, количество окон, цвет стен, высота потолка, покрытие пола и др.
В теории фреймов такой образ комнаты называется фреймом комнаты. Фреймом также называется и формализованная модель для отображения образа.
Различают фреймы-образцы, или прототипы, хранящиеся в базе знаний, и фреймы-экземпляры, которые создаются для отображения реальных фактических ситуаций на основе поступающих данных. Модель фрейма является достаточно универсальной, поскольку позволяет отобразить все многообразие знаний о мире через:
• фреймы-структуры, использующиеся для обозначения объектов и понятий (заем, залог, вексель);
• фреймы-роли (менеджер, кассир, клиент);
• фреймы-сценарии (банкротство, собрание акционеров, празднование именин);
• фреймы-ситуации (тревога, авария, рабочий режим устройства) и др. Традиционно структура фрейма может быть представлена как список свойств:
(ИМЯ ФРЕЙМА:
(имя 1-го слота: значение 1-го слота), (имя 2-го слота: значение 2-го слота), (имя N-ro слота: значение N-ro слота)). Ту же запись можно представить в виде таблицы, дополнив ее двумя столбцами.
Таблица 1. Структура фрейма
| Имя фрейма
|
| Имя слота
| Значение слота
| Способ получения значения
| Присоединенная процедура
|
| | | | |
В таблице дополнительные столбцы предназначены для описания способа получения слотом его значения и возможного присоединения к тому или иному слоту специальных процедур, что допускается в теории фреймов. В качестве значения слота может выступать имя другого фрейма, так образуются сети фреймов. Существует несколько способов получения слотом значений во фрейме-экземпляре:
• по умолчанию от фрейма-образца (Default-значение);
• через наследование свойств от фрейма, указанного в слоте АКО;
• по формуле, указанной в слоте;
• через присоединенную процедуру;
• явно из диалога с пользователем;
• из базы данных.
Важнейшим свойством теории фреймов является заимствование из теории семантических сетей — так называемое наследование свойств. И во фреймах, и в семантических сетях наследование происходит по АКО-связям (A-Kind-Of = это). Слот АКО указывает на фрейм более высокого уровня иерархии, откуда неявно наследуются, то есть переносятся, значения аналогичных слотов.
Пример 1.4.
Например, в сети фреймов на рис. 1.2 понятие «ученик» наследует свойства фреймов «ребенок» и «человек», которые находятся на более высоком уровне иерархии. Так, на .вопрос «любят ли ученики сладкое» следует ответ «да», так как этим свойством обладает все дети, что указано во фрейме «ребенок». Наследование свойств может быть частичным, так как возраст для учеников не наследуется из фрейма «ребенок», поскольку указан явно в своем собственном фрейме.
Основным преимуществом фреймов как модели представления знаний является то, что она отражает концептуальную основу организации памяти человека, а также ее гибкость и наглядность.
Специальные языки представления знаний в сетях фреймов FRL (Frame Representation Language), KRL (Knowledge Representation Language), фреймовая «оболочка» KAPPA и другие программные средства позволяют эффективно строить промышленные ЭС. Широко известны такие фрейм-ориентированные экспертные системы, как ANALYST, МОДИС, TRISTAN, ALTERID.
Формальные логические модели
Традиционно в представлении знаний выделяют формальные логические модели, основанные на классическом исчислении предикатов 1-го порядка, когда предметная область или задача описывается в виде набора аксиом. Мы же опустим описание этих моделей по следующим причинам. Исчисление предикатов 1-го порядка в промышленных экспертных системах практически не используется. Эта логическая модель применима в основном в исследовательских «игрушечных» системах, так как предъявляет очень высокие требования и ограничения к предметной области.
В промышленных же экспертных системах используются различные ее модификации и расширения, изложение которых выходит за рамки этого учебника.
5. Вывод на знаниях
Несмотря на все недостатки, наибольшее распространение получила продукционная модель представления знаний. При использовании продукционной модели база знаний состоит из набора правил. Программа, управляющая перебором правил, называется машиной вывода.
Машина вывода
Машина вывода (интерпретатор правил) выполняет две функции: во-первых, просмотр существующих фактов из рабочей памяти (базы данных) и правил из базы знаний и добавление (по мере возможности) в рабочую память новых фактов и, во-вторых, определение порядка просмотра и применения правил. Этот механизм управляет процессом консультации, сохраняя для пользователя информацию о полученных заключениях, и запрашивает у него информацию, когда для срабатывания очередного правила в рабочей памяти оказывается недостаточно данных.
В подавляющем большинстве систем, основанных на знаниях, механизм вывода представляет собой небольшую по объему программу и включает два компонента — один реализует собственно вывод, другой управляет этим процессом. Действие компонента вывода основано на применении правила, называемого modus ponens.
Правило modus ponens. Если известно, что истинно утверждение А и существует правило вида «ЕСЛИ А, ТО В», тогда утверждение В также истинно.
Правила срабатывают, когда находятся факты, удовлетворяющие их левой части: если истинна посылка, то должно быть истинно и заключение.
Компонент вывода должен функционировать даже при недостатке информации. Полученное решение может и не быть точным, однако система не должна останавливаться из-за того, что отсутствует какая-либо часть входной информации.
Управляющий компонент определяет порядок применения правил и выполняет четыре функции.
1. Сопоставление — образец правила сопоставляется с имеющимися фактами.
2. Выбор — если в конкретной ситуации может быть применено сразу несколько правил, то из них выбирается одно, наиболее подходящее по заданному критерию (разрешение конфликта).
3. Срабатывание — если образец правила при сопоставлении совпал с какими-либо фактами из рабочей памяти, то правило срабатывает.
4. Действие — рабочая память подвергается изменению путем добавления в нее заключения сработавшего правила. Если в правой части правила содержится указание на какое-либо действие, то оно выполняется (как, например, в системах обеспечения безопасности информации).
Интерпретатор продукций работает циклически. В каждом цикле он просматривает все правила, чтобы выявить те, посылки которых совпадают с известными -на данный момент фактами из рабочей памяти. После выбора правило срабатывает, его заключение заносится в рабочую память, и затем цикл повторяется сначала.
В одном цикле может сработать только одно правило. Если несколько правил успешно сопоставлены с фактами, то интерпретатор производит выбор по определенному критерию единственного правила, которое срабатывает в данном цикле. Цикл работы интерпретатора схематически представлен на рис. 1.3.
Информация из рабочей памяти последовательно сопоставляется с посылками правил для выявления успешного сопоставления. Совокупность отобранных правил составляет так называемое конфликтное множество. Для разрешения конфликта интерпретатор имеет критерий, с помощью которого он выбирает единственное правило, после чего оно срабатывает. Это выражается в занесении фактов, образующих заключение правила, в рабочую память или в изменении критерия выбора конфликтующих правил. Если же в заключение правила входит название какого-нибудь действия, то оно выполняется.
Работа машины вывода зависит только от состояния рабочей памяти и от состава базы знаний. На практике обычно учитывается история работы, то есть поведение механизма вывода в предшествующих циклах. Информация о поведении механизма вывода запоминается в памяти состояний (рис. 1.4). Обычно память состояний содержит протокол системы.
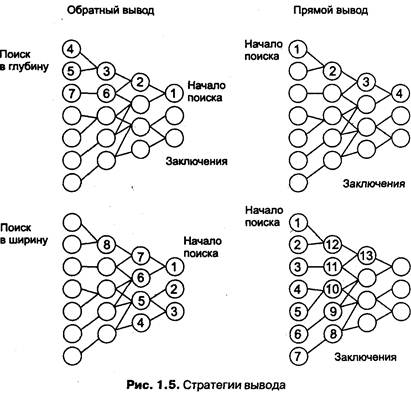
Стратегии управления выводом
От выбранного метода поиска, то есть стратегии вывода, будет зависеть порядок применения и срабатывания правил. Процедура выбора сводится к определению направления поиска и способа его осуществления. Процедуры, реализующие поиск, обычно «зашиты» в механизм вывода, поэтому в большинстве систем инженеры знаний не имеют к ним доступа и, следовательно, не могут в них ничего изменять по своему желанию.
При разработке стратегии управления выводом важно определить два вопроса:
1. Какую точку в пространстве состояний принять в качестве исходной? От выбора этой точки зависит и метод осуществления поиска — в прямом или обратном направлении.
2. Какими методами можно повысить эффективность поиска решения? Эти методы определяются выбранной стратегией перебора — глубину, в ширину, по подзадачам или иначе.
Прямой и обратный вывод
При обратном порядке вывода вначале выдвигается некоторая гипотеза, а затем механизм вывода как бы возвращается назад, переходя к фактам, пытаясь найти те, которые подтверждают гипотезу (рис. 1.5, правая часть). Если она оказалась правильной, то выбирается следующая гипотеза, детализирующая первую и являющаяся по отношению к ней подцелью. Далее отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями, или управляемым консеквентами. Обратный поиск применяется в тех случаях, когда цели известны и их сравнительно немного.
В системах с прямым выводом по известным фактам отыскивается заключение, которое из этих фактов следует (см. рис. 1.5, левая часть). Если такое заключение удается найти, то оно заносится в рабочую память. Прямой вывод часто называют выводом, управляемым данными, или выводом, управляемым антецедентами. Существуют системы, в которых вывод основывается на сочетании упомянутых выше методов — обратного и ограниченного прямого. Такой комбинированный метод получил название циклического.
Пример 1.5.
Имеется фрагмент базы знаний из двух правил:
П1. Если «отдых — летом» и «человек — активный», то «ехать в горы».
П2. Если «любит солнце», то «отдых летом».
Предположим, в систему поступили факты — «человек активный» и «любит солнце».
ПРЯМОЙ ВЫВОД — исходя из фактических данных, получить рекомендацию.
1-й проход.
Шаг 1. Пробуем П1, не работает (не хватает данных «отдых — летом»).
Шаг 2. Пробуем П2, работает, в базу поступает факт «отдых — летом».
2-й проход.
Шаг 3. Пробуем П1, работает, активируется цель «ехать в горы», которая и выступает как совет, который дает ЭС.
ОБРАТНЫЙ ВЫВОД — подтвердить выбранную цель при помощи имеющихся правил и данных.
1-й проход.
Шаг 1. Цель — «ехать в горы»: пробуем П1 — данных «отдых — летом» нет, они становятся новой целью и ищется правило, где цель в левой части. Шаг 2. Цель «отдых — летом»: правило П2 подтверждает цель и активирует ее.
2-й проход.
Шаг 3. Пробуем П1, подтверждается искомая цель.
Методы поиска в глубину и ширину
В системах, база знаний которых насчитывает сотни правил, желательным является использование стратегии управления выводом, позволяющей минимизировать время поиска решения и тем самым повысить эффективность вывода. К числу таких стратегий относятся: поиск в глубину, поиск в ширину, разбиение на подзадачи и альфа-бета алгоритм.
При поиске в глубину в качестве очередной подцели выбирается та, которая соответствует следующему, более детальному уровню описания задачи. Например, диагностирующая система, сделав на основе известных симптомов предположение о наличии определенного заболевания, будет продолжать запрашивать уточняющие признаки и симптомы этой болезни до тех пор, пока полностью не опровергнет выдвинутую гипотезу.
При поиске в ширину, напротив, система вначале проанализирует все симптомы, находящиеся на одном уровне пространства состояний, даже если они относятся к разным заболеваниям, и лишь затем перейдет к симптомам следующего уровня детальности.
Разбиение на подзадачи — подразумевает выделение подзадач, решение которых рассматривается как достижение промежуточных целей на пути к конечной цели. Примером, подтверждающим эффективность разбиения на подзадачи, является поиск неисправностей в компьютере — сначала выявляется отказавшая подсистема (питание, память и т. д.), что значительно сужает пространство поиска. Если удается правильно понять сущность задачи и оптимально разбить ее на систему иерархически связанных целей-подцелей, то можно добиться того, что путь к ее решению в пространстве поиска будет минимален.
Альфа-бета алгоритм позволяет уменьшить пространство состояний путем удаления ветвей, неперспективных для успешного поиска. Поэтому просматриваются только те вершины, в которые можно попасть в результате следующего шага, после чего неперспективные направления исключаются. Альфа-бета алгоритм нашел широкое применение в основном в системах, ориентированных на различные игры, например в шахматных программах.
6. Нечеткие знания
При попытке формализовать человеческие знания исследователи вскоре столкнулись с проблемой, затруднявшей использование традиционного математического аппарата для их описания. Существует целый класс описаний, оперирующих качественными характеристиками объектов (много, мало, сильный, очень сильный и т. п.). Эти характеристики обычно размыты и не могут быть однозначно интерпретированы, однако содержат важную информацию (например, «Одним из возможных признаков гриппа является высокая температура»).
Кроме того, в задачах, решаемых интеллектуальными системами, часто приходится пользоваться неточными знаниями, которые не могут быть интерпретированы как полностью истинные или ложные (логические true/false или 0/1). Существуют знания, достоверность которых выражается некоторой промежуточной цифрой, например 0,7.
Как, не разрушая свойства размытости и неточности, представлять подобные знания формально? Для разрешения таких проблем в начале 70-х американский математик Лотфи Заде предложил формальный аппарат нечеткой (fuzzy) алгебры и нечеткой логики. Позднее это направление получило широкое распространение и положило начало одной из ветвей ИИ под названием — мягкие вычисления (soft computing).
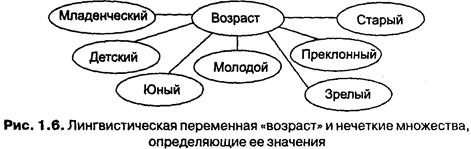
Л. Заде ввел одно из главных понятий в нечеткой логике — понятие лингвистической переменной.
Лингвистическая переменная (ЛП) — это переменная, значение которой определяется набором вербальных (то есть словесных) характеристик некоторого свойства.
Например, ЛП «рост» определяется через набор {карликовый, низкий, средний, высокий, очень высокий}.
6.1. Основы теории нечетких множеств
Значения лингвистической переменной (ЛП) определяются через так называемые нечеткие множества (НМ), которые в свою очередь определены на некотором базовом наборе значений или базовой числовой шкале, имеющей размерность. Каждое значение ЛП определяется как нечеткое множество (например, НМ «низкий рост»).
Нечеткое множество определяется через некоторую базовую шкалу В и функцию принадлежности НМ — 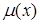 ,
, 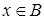 принимающую значения на интервале [0...1]. Таким образом, нечеткое множество В — это совокупность пар вида
принимающую значения на интервале [0...1]. Таким образом, нечеткое множество В — это совокупность пар вида 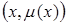 где . Часто встречается и такая запись:
где . Часто встречается и такая запись:
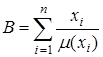 ,
,
где  —
— 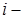 e значение базовой шкалы.
e значение базовой шкалы.
Функция принадлежности определяет субъективную степень уверенности эксперта в том, что данное конкретное значение базовой шкалы соответствует определяемому НМ. Эту функцию не стоит путать с вероятностью, носящей объективный характер и подчиняющейся другим математическим зависимостям.
Например, для двух экспертов определение НМ «высокая» для ЛП «цена автомобиля» в условных единицах может существенно отличаться в зависимости от их социального и финансового положения.
«Высокая_цена_автомобиля_1» = 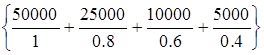 .
.
«Высокая_цена_автомобиля_2» = 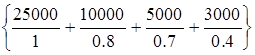 .
.
Пример 1.6.
Пусть перед нами стоит задача интерпретации значений ЛП «возраст», таких как «молодой» возраст, «преклонный» возраст или «переходный» возраст. Определим «возраст» как ЛП (рис. 1.6). Тогда «молодой», «преклонный», «переходный» будут значениями этой лингвистической переменной. Более полно, базовый набор значений ЛП «возраст» следующий:
В = {младенческий, детский, юный, молодой, зрелый, преклонный, старческий}.
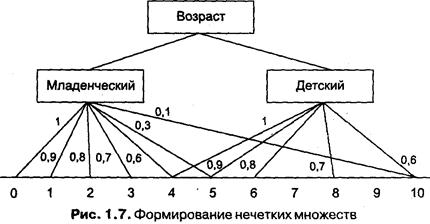
Для ЛП «возраст» базовая шкала — это числовая шкала от 0 до 120, обозначающая количество прожитых лет, а функция принадлежности определяет, насколько мы уверены в том, что данное количество лет можно отнести к данной категории возраста. На рис. 1.7 отражено, как одни и те же значения базовой шкалы могут участвовать в определении различных НМ.
Например, определить значение НМ «младенческий возраст» можно так:
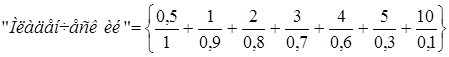 .
.
Рисунок 1.8 иллюстрирует оценку НМ неким усредненным экспертом, который ребенка до полугода с высокой степенью уверенности относит к младенцам ( 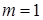 ). Дети до четырех лет тоже причисляются к младенцам, но с меньшей степенью уверенности (
). Дети до четырех лет тоже причисляются к младенцам, но с меньшей степенью уверенности ( 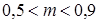 ), а в десять лет ребенка называют так только в очень редких случаях. К примеру, для девяностолетней бабушки и 15 лет может считаться младенчеством. Таким образом, нечеткие множества позволяют при определении понятия учитывать субъективные мнения отдельных индивидуумов.
), а в десять лет ребенка называют так только в очень редких случаях. К примеру, для девяностолетней бабушки и 15 лет может считаться младенчеством. Таким образом, нечеткие множества позволяют при определении понятия учитывать субъективные мнения отдельных индивидуумов.
6.2. Операции с нечеткими знаниями
Для операций с нечеткими знаниями, выраженными при помощи лингвистических переменных, существует много различных способов. Эти способы являются в основном эвристиками. Мы не будем останавливаться на этом вопросе подробно, укажем лишь для примера определение нескольких операций. К примеру, операция «ИЛИ» часто задается так:
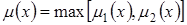 (так называемая логика Заде)
(так называемая логика Заде)
или так:
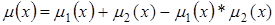 (вероятностный подход).
(вероятностный подход).
Усиление или ослабление лингвистических понятий достигается введением специальных квантификаторов. Например, если понятие «старческий возраст» определяется как
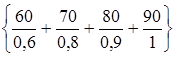
то понятие «очень старческий возраст» определится как
 .
.
То есть "очень старческий возраст" равен
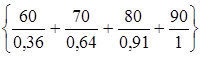
Для вывода на нечетких множествах используются специальные отношения и операции над ними (подробнее – в курсе лекций "Теория систем"). Одним из первых применений теории НМ стало использование коэффициентов уверенности для вывода рекомендаций медицинской системы MYCIN.
Этот метод использует несколько эвристических приемов. Он стал примером обработки нечетких знаний, повлиявших на последующие системы. В настоящее время в большинство инструментальных средств разработки систем, основанных на знаниях, включены элементы работы с НМ, кроме того, разработаны специальные программные средства реализации так называемого нечеткого вывода, например «оболочка» FuzzyCLIPS, или известным приложением FuzzyLogic из пакета MATLAB.
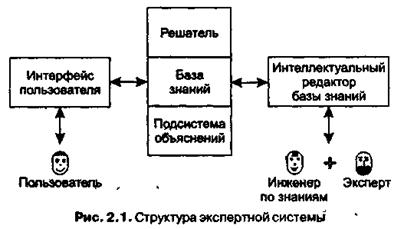
7. Определение и структура экспертной системы
В качестве рабочего определения экспертной системы примем следующее.
Экспертные системы (ЭС) — это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и тиражирующие этот эмпирический опыт для консультаций менее квалифицированных пользователей.
Обобщенная структура экспертной системы представлена на рис. 2.1. Следует учесть, что реальные ЭС могут иметь более сложную структуру, однако блоки, изображенные на рисунке, непременно присутствуют в любой действительно экспертной системе, поскольку представляют собой стандарт de facto структуры современной ЭС.
В целом процесс функционирования ЭС можно представить следующим образом: пользователь, желающий получить необходимую информацию, через пользовательский интерфейс посылает запрос к ЭС; решатель, пользуясь базой знаний, генерирует и выдает пользователю подходящую рекомендацию, объясняя ход своих рассуждений при помощи подсистемы объяснений.
Так как терминология в области разработки ЭС постоянно модифицируется, определим основные термины в рамках данной работы.
Пользователь — специалист предметной области, для которого предназначена система. Обычно его квалификация недостаточно высока, и поэтому он нуждается в помощи и поддержке своей деятельности со стороны ЭС.
Инженер по знаниям — специалист в области искусственного интеллекта, выступающий в роли промежуточного буфера между экспертом и базой знаний. Синонимы: когнитолог, инженер-интерпретатор, аналитик.
Интерфейс пользователя— комплекс программ, реализующих диалог пользователя с ЭС как на стадии ввода информации, так и при получении результатов.
База знаний (БЗ) — ядро ЭС, совокупность знаний предметной области, записанная на машинный носитель в форме, понятной эксперту и пользователю (обычно на некотором языке, приближенном к естественному). Параллельно такому «человеческому» представлению существует БЗ во внутреннем «машинном» представлении.
Решатель— программа, моделирующая ход рассуждений эксперта на основании знаний, имеющихся в БЗ. Синонимы: дедуктивная машина, машина вывода, блок логического вывода.
Подсистема объяснений — программа, позволяющая пользователю получить ответы на вопросы: «Как была получена та или иная рекомендация?» и «Почему система приняла такое решение?» Ответ на вопрос «как» — это трассировка всего процесса получения решения с указанием использованных фрагментов БЗ, то есть всех шагов цепи умозаключений. Ответ на вопрос «почему» — ссылка на умозаключение, непосредственно предшествовавшее полученному решению, то есть отход на один шаг назад. Развитые подсистемы объяснений поддерживают и другие типы вопросов.
Интеллектуальный редактор БЗ — программа, представляющая инженеру по знаниям возможность создавать БЗ в диалоговом режиме. Включает в себя систему вложенных меню, шаблонов языка представления знаний, подсказок («help» — режим) и других сервисных средств, облегчающих работу с базой.
Еще раз следует подчеркнуть, что представленная на рис. 2.1 структура является минимальной, что означает обязательное присутствие указанных на ней блоков. Если система объявлена разработчиками как экспертная, только наличие всех этих блоков гарантирует реальное использование аппарата обработки знаний. Однако промышленные .прикладные ЭС могут быть существенно сложнее и дополнительно включать базы данных, интерфейсы обмена данными с различными пакетами прикладных программ, электронными библиотеками и т. д.
8. Классификация систем, основанных на знаниях
Класс ЭС сегодня объединяет несколько тысяч различных программных комплексов, которые можно классифицировать по различным критериям.