Проекция отношения А на атрибуты X, Y,..., Z (А [X, Y,.. , Z]), где множество {X, Y,..., Z} является подмножеством полного списка атрибутов заголовка отношения А, представляет собой отношение с заголовком X, Y,..., Z и телом, содержащим кортежи отношения А, за исключением повторяющихся кортежей. Повторение одинаковых атрибутов в списке X, Y,..., Z запрещается. Операция проекции допускает следующие дополнительные варианты записи: отсутствие списка атрибутов подразумевает указание всех атрибутов (операция тождественной проекции); выражение вида R[ ] означает пустую проекцию, результатом которой является пустое множество; операция проекции может применяться к произвольному отношению, в том числе и к результату выборки. Примеры 4. Проекции.
Р [Тип, Город_Д]
Тип
Город_Д
каленый
Москва
мягкий
Киев
твердый
Ростов
твердый
Киев
(S WHERE Город_П="Киев") [П#]
П#
Город_П
S2
Киев
S3
Киев
Результатом деления отношения R1 с атрибутами А и В на отношение R2 с атрибутом В (R1 DIVIDEBY R2), где А и В простые или составные атрибуты, причем атрибут В - общий атрибут, определенный на одном и том же домене (множестве доменов составного атрибута), является отношение R с заголовком А и телом, состоящим из кортежей г таких, что в отношении R1 имеются кортежи (г, s), причем множество значений s включает множество значений атрибута В отношения R2. Пример 5. Деление отношения. Пусть R1 - проекция SP [П#, Д#], a R2 - отношение с заголовком Д# и телом {Р2, Р4}, тогда результатом деления R1 на R2 будет отношение R с заголовком П# и телом {S1, S4}.
R1
П#
Д#
S1
P1
S1
P2
S1
P3
S1
P4
S1
P5
S1
P6
S2
P1
S2
P2
S3
P2
S4
P2
S4
P4
S4
P5
Д#
P2
P4
R (R1 UNION R2)
П#
S1
S4
Соединение С (R1, R2) отношений R1 и R2 по условию, заданному формулой f, представляет собой отношение R, которое можно получить путем Декартова произведения отношений R1 и R2 с последующим применением к результату операции выборки по формуле f. Правила записи формулы f такие же, как и для операции селекции. Другими словами, соединением отношения R1 по атрибуту А с отношением R2 по атрибуту В (отношения не имеют общих имен атрибутов) является результат выполнения операции вида: (R1 TIMES R2) WHERE A 0 В, где Q, - логическое выражение над атрибутами, определенными на одном (нескольких - для составного атрибута) домене. Соединение C ((R1, R2), где формула f имеет произвольный вид (в отличие от частных случаев, рассматриваемых далее), называют также f-соединением. Важными с практической точки зрения частными случаями соединения являются эквисоединение и естественное соединение. Операция эквисоединения характеризуется тем, что формула задает равенство операндов. Приведенный выше пример демонстрирует частный случай операции эквисоединения по одному столбцу. Иногда эквисоединение двух отношений выполняется по таким столбцам, атрибуты которых в обоих отношениях имеют соответственно одинаковые имена и домены. В этом случае говорят об эквисоединении по общему атрибуту. Операция естественного соединения (операция JOIN) применяется к двум отношениям, имеющим общий атрибут (простой или составной). Этот атрибут в отношениях имеет одно и то же имя (совокупность имен) и определен на одном и том же домене (доменах). Результатом операции естественного соединения является отношение R, которое представляет собой проекцию эквисоединения отношений R1 и R2 по общему атрибуту на объединенную совокупность атрибутов обоих отношений. Пример 6. Q-соединение. Необходимо найти соединение отношений S и Р по атрибутам Город_П и Город_Д соответственно, причем кортежи результирующего отношения должны удовлетворять отношению "больше" (в смысле лексикографического порядка - по алфавиту).
(S TIMES P) WHERE Город_П > Город_Д
П#
Имя
Статус
Город_П
Д#
Название
Тип
Вес
Города
S2
Иван
Киев
P1
гайка
каленый
Москва
S2
Иван
Киев
P4
винт
каленый
Москва
S2
Иван
Киев
P6
шпилька
каленый
Москва
S3
Борис
Киев
P1
гайка
каленый
Москва
S3
Борис
Киев
P4
винт
каленый
Москва
S3
Борис
Киев
P6
шпилька
каленый
Москва
Пример 7. Эквисоединение. Пусть необходимо найти естественное соединение отношений S и Р по общему атрибуту, характеризующему город (в отношении S - это Город_П, а в отношении Р - Город_Д). Поскольку условие операции требует одинаковости имен атрибутов, по которым выполняется соединение, то применяется операция RENAME переименования атрибутов.
(S RENAME Город_П AS Город) JOIN (P RENAME Город_Д AS Город)
П#
Имя
Статус
Город_П
Д#
Название
Тип
Вес
S1
Сергей
Москва
P1
гайка
каленый
S1
Сергей
Москва
P4
винт
каленый
S1
Сергей
Москва
P6
шпилька
каленый
S2
Иван
Киев
P2
болт
мягкий
S2
Иван
Киев
P5
палец
твердый
S3
Борис
Киев
P2
болт
мягкий
S3
Борис
Киев
P5
палец
твердый
S4
Николай
Москва
P1
гайка
каленый
S4
Николай
Москва
P4
винт
каленый
S4
Николай
Москва
P6
шпилька
каленый
Дополнительные операции реляционной алгебры,предложенные Дейтом, включают следующие операции. Операция переименования позволяет изменить имя атрибута отношения и имеет вид: RENAME <исходное отношение> <старое имя атрибута> AS <новое имя атрибута>, где <исходное отношение> задается именем отношения либо выражением реляционной алгебры. В последнем случае выражение заключают в круглые скобки. Например: RENAME Город_П AS Город_размещения_Поставщика. Замечание. Для удобства записи выражений одновременного переименования нескольких атрибутов Дейтом введена операция множественного переименования, которая представима следующим образом: RENAME <отн.> <ст. имя атр.1> AS <нов. имя атр.1>,<ст. имя атр.2> AS <нов. имя атр.2>,... ,<ст. имя arp.N> AS <нов. имя aTp.N>. Операция расширения порождает новое отношение, похожее на исходное, но отличающееся наличием добавленного атрибута, значения которого получаются путем некоторых скалярных вычислений. Операция расширения имеет вид: EXTEND <исходное отношение> ADD <выражение> AS <новый атрибут>, где к исходному отношению добавляется (ключевое слово ADD) <новый атрибут>, подсчитываемый по правилам, заданным <выражением>. Исходное отношение может быть задано именем отношения и с помощью выражения реляционной алгебры, заключенного в круглые скобки. При этом имя нового атрибута не должно входить в заголовок исходного отношения и не может использоваться в <выражении>. Помимо обычных арифметических операций и операций сравнения, в выражении можно использовать различные функции, называемые итоговыми, такие как: COUNT (количество), SUM (сумма), AVG (среднее), МАХ (максимальное), MIN (минимальное). Например: EXTEND (PJOIN SP) ADD (Вес * Количество) AS Общий_Вес. Замечания. Пользуясь операцией расширения, можно выполнить переименование атрибута. Для этого нужно в выражении указать имя атрибута, в конструкции AS определить новое имя этого атрибута, затем выполнить проекцию полученного отношения на множество атрибутов, исключая старый атрибут. Таким образом, запись (EXTEND S ADD Город_П AS Город) [П#, Имя, Статус, Город] эквивалента конструкции S RENAME Город_П AS Город. Подобно тому, как это сделано для операции переименования, Дейт определил операцию множественного расширения, которая позволяет в одной синтаксической конструкции вычислять несколько новых атрибутов. Формально операция пред-ставима следующим образом: EXTEND <отн.> ADD <выр.1> AS <атр.1>, <выр.2> AS <атр.2>,... ,<выр.N> AS <атр.N>. Операция подведения итогов SUMMARIZE выполняет "вертикальные" или групповые вычисления и имеет следующий формат: SUMMARIZE <исх. отн> BY (<список атрибутов;") ADD <выр.> AS <новый атрибут>, где исходное отношение задается именем отношения либо заключенным в круглые скобки выражением реляционной алгебры, <список атрибутов> представляет собой разделенные запятыми имена атрибутов исходного отношения A1, A2, ..., AN, <выр.> - скалярное выражение, аналогичное выражению операции EXTEND, а <новый атрибут> - имя формируемого атрибута. В списке атрибутов и в выражении не должен использоваться <новый атрибут>. Результатом операции SUMMARIZE является отношение R с заголовком, состоящим из атрибутов списка, расширенного новым атрибутом. Для получения тела отношения R сначала выполняется проецирование (назовем проекцию R1) исходного отношения на атрибуты A1, A2,..., AN, после чего каждый кортеж проекции расширяется новым (N+1)-M атрибутом. Поскольку проецирование, как правило, приводит к сокращению количества кортежей по отношению к исходному отношению (удаляются одинаковые кортежи), то можно считать, что происходит своеобразное группирование кортежей исходного отношения: одному кортежу отношения R1 соответствует один или более (если было дублирование при проецировании) кортежей исходного отношения. Значение (N+1)-гo атрибута каждого кортежа отношения R формируется путем вычисления выражения над соответствующей этому кортежу группой кортежей исходного отношения. Пример 8. Подведение итогов. Пусть требуется вычислить количество поставок по каждому из поставщиков.
SUMMARIZE SP BY (П#) ADD COUNT AS Количество_поставок
П#
Количество_поставок
S1
S2
S3
S4
Отметим, что функция COUNT определяет количество кортежей в каждой из групп исходного отношения. Операция множественного подведения итогов, подобно соответствующим операциям переименования и расширения, выполняет одновременно несколько "вертикальных" вычислений и записывает результаты в отдельные новые атрибуты. Простейшим примером такой операции может служить следующая запись: SUMMARIZE SP BY (Д#) ADD SUM Количество AS Общее_число_прставок AVG Количество AS Среднее_число_поставок. К основным операторам, позволяющим изменять тело существующего отношения, отнесем операции: реляционного присвоения, вставки, обновления, удаления. Операцию присвоения можно представить следующим образом: <выражение-цель>:= <выражение-источник>, где оба выражения задают совместимые (точнее, эквивалентные) по структуре отношения. Типичный случай выражений: в левой части - имя отношения, а в правой - некоторое выражение реляционной алгебры. Выполнение операции присвоения сводится к замене предыдущего значения отношения на новое (начальное значение, если тело отношения было пустым), определенное выражением-источником. С помощью операции присвоения можно не только полностью заменить все значения отношения-цели, но и добавить или удалить кортежи. Приведем пример, в котором в отношение S дописывается один кортеж: S:=S UNION {{< П# : 'S6' >, < Имя: 'Борис' >, < Статус: '50' >, <Город_П : 'Мадрид' >}}. Более удобными операциями изменения тела отношения являются операции вставки, обновления и удаления. Операция вставки INSERT имеет следующий вид: INSERT <выражение-источник> INTO <выражение-цель>, где оба выражения должны быть совместимы по структуре. Выполнение операции сводится к вычислению <выражение-источник> и вставке полученных кортежей в отношение, заданное <выражение-цель>. Пример: INSERT (S WHERE Город_П='Москва') INTO Temp. Операция обновления UPDATE имеет следующий вид: UPDATE <выражение-цель> <список элементов>, где <список элементов> представляет собой последовательность разделенных запятыми операций присвоения <атрибут> := <скалярное выражение>. Результатом выполнения операции обновления является отношение, полученное после присвоения соответствующих значений атрибутам отношения, заданного целевым выражением. Например, UPDATE P WHERE Тип='каленый' Город := 'Киев'. Эта операция предписывает изменить значение атрибута Город (независимо от того, каким оно было) на новое значение - 'Киев' таких кортежей отношения P, атрибут Тип которых имеет значение 'каленый'. Операция удаления DELETE имеет следующий вид: DELETE <выражение-цель>, где <выражение-цель> представляет собой реляционное выражение, описывающее удаляемые кортежи. Например, DELETE S WHERE Статус < 20. Операция реляционного сравнения может использоваться для прямого сравнения двух отношений. Она имеет синтаксис: <выражение1> ? <выражение2>, где оба выражения задают совместимые по структуре отношения, а знак ? - один из следующих операторов сравнения: = (равно), ? (не равно), < (собственное подмножество), < (подмножество), >. (надмножество), > (собственное надмножество). Например, сравнение: "Совпадают ли города поставщиков и города хранения деталей?" можно записать так: S [Город_П] = Р [Город_Д]. Основные правила записи выражений. Как отмечалось, результатом произвольной реляционной операции является отношение, которое, в свою очередь, может участвовать в другой реляционной операции. Это свойство реляционной алгебры называется свойством замкнутости. Свойство замкнутости позволяет записывать вложенные выражения реляционной алгебры, основой которых выступают рассмотренные ранее элементарные операций: объединение проекция пересечение выборка и т. д. При записи произвольного выражения реляционной алгебры надо принимать во внимание следующее: 1. В реляционной алгебре должен быть определен приоритет выполнения операций (например, операция пересечение более приоритетна чем операция объединение), который нужно учитывать при записи выражений. Для изменения порядка выполнения операций в выражениях можно использовать круглые скобки. 2. Существуют тождественные преобразования, позволяющие по-разному записывать одно и то же выражение. Например, следующие выражения эквивалентны (здесь А - отношение, С, C1, C2 - выражения): A WHERE C1 AND C2 и (A WHERE C1) INTERSECT (A WHERE C2), A WHERE C1 OR C2 и (A WHERE C1) UNION (A WHERE C2), A WHERE NOT С и A MINUS (A WHERE C). 3. Составляя выражение, нужно обеспечивать совместимость участвующих в операциях отношений. При необходимости изменения заголовков следует выполнять переименование атрибутов.
3.7. Структурированный язык запросов SQL
Структурированный язык запросов SQL основан на реляционном исчислении с переменными кортежами. Язык имеет несколько стандартов, наиболее распространенными из которых являются SQL-89 и SQL-92 (подраздел 9.3).
Общая характеристика языка
Язык SQL предназначен для выполнения операций над таблицами (создание, удаление, изменение структуры) и над данными таблиц (выборка, изменение, добавление и удаление), а также некоторых сопутствующих операций. SQL является непроцедурным языком и не содержит операторов управления, организации подпрограмм, ввода-вывода и т. п. В связи с этим SQL автономно не используется, обычно он погружен в среду встроенного языка программирования СУБД (например, FoxPro СУБД Visual FoxPro, ObjectPAL СУБД Paradox, Visual Basic for Applications СУБД Access). В современных СУБД с интерактивным интерфейсом можно создавать запросы, используя другие средства, например QBE. Однако применение SQL зачастую позволяет повысить эффективность обработки данных в базе. Например, при подготовке запроса в среде Access можно перейти из окна Конструктора запросов (формулировки запроса по образцу на языке QBE) в окно с эквивалентным оператором SQL. Подготовку нового запроса путем редактирования уже имеющегося в ряде случае проще выполнить путем изменения оператора SQL. В различных СУБД состав операторов SQL может несколько отличаться. Язык SQL не обладает функциями полноценного языка разработки, а ориентирован на доступ к данным, поэтому его включают в состав средств разработки программ. В этом случае его называют встроенным SQL. Стандарт языка SQL поддерживают современные реализации следующих языков программирования: PL/I, Ada, С, COBOL, Fortran, MUMPS и Pascal. В специализированных системах разработки приложений типа клиент-сервер среда программирования, кроме того, обычно дополнена коммуникационными средствами (установление и разъединение соединений с серверами БД, обнаружение и обработка возникающих в сети ошибок и т. д.), средствами разработки пользовательских интерфейсов, средствами проектирования и отладки. Различают два основных метода использования встроенного SQL: статический динамический. При статическом использовании языка (статический SQL) в тексте программы имеются вызовы функций языка SQL, которые жестко включаются в выполняемый модуль после компиляции. Изменения в вызываемых функциях могут быть на уровне отдельных параметров вызовов с помощью переменных языка программирования. При динамическом использовании языка (динамический SQL) предполагается динамическое построение вызовов SQL-функций и интерпретация этих вызовов, например, обращение к данным удаленной базы, в ходе выполнения программы. Динамический метод обычно применяется в случаях, когда в приложении заранее неизвестен вид SQL-вызова и он строится в диалоге с пользователем. Основным назначением языка SQL (как и других языков для работы с базами данных) является подготовка и выполнение запросов. В результате выборки данных из одной или нескольких таблиц может быть получено множество записей, называемое: представлением. Представление по существу является таблицей, формируемой в результате выполнения запроса. Можно сказать, что оно является разновидностью хранимого запроса. По одним и тем же таблицам можно построить несколько представлений. Само представление описывается путем указания идентификатора представления и запроса, который должен быть выполнен для его получения. Для удобства работы с представлениями в язык SQL введено понятие курсора. Курсор представляет собой своеобразный указатель, используемый для перемещения по наборам записей при их обработке. Описание и использование курсора в языке SQL выполняется следующим образом. В описательной части программы выполняют связывание переменной типа курсор (CURSOR) с оператором SQL (обычно с оператором SELECT). В выполняемой;, части программы производится открытие курсора (OPEN <имя курсора>), перемещение курсора по записям (FETCH <имя курсора>...), сопровождаемое соответствующей обработкой, и, наконец, закрытие курсора (CLOSE <имя курсора>).
Основные операторы языка
Опишем минимальное подмножество языка SQL, опираясь на его реализацию в стандартном интерфейсе ODBC (Open Database Connectivity - совместимость открытых баз данных) фирмы Microsoft. Операторы языка SQL можно условно разделить на два подъязыка: язык определения данных (Data Definition Language - DDL) и язык манипулирования данными (Data Manipulation Language - DML). Основные операторы языка SQL представлены в табл. 3.3. Рассмотрим формат и основные возможности важнейших операторов, за исключением специфических операторов, отмеченных в таблице символом "*". Несущественные операнды и элементы синтаксиса (например, принятое во многих системах программирования правило ставить ";" в конце оператора) будем опускать. 1. Оператор создания таблицы имеет формат вида: CREATE TABLE <имя таблицы> (<имя столбца> <тип данных> [NOT NULL] [,<имя столбца> <тип данных> [NOT NULL]] ... ) 5. Оператор удаления индекса имеет формат вида: DROP INDEX <имя индекса> Этот оператор позволяет удалять созданный ранее индекс с соответствующим именем. Так, например, для уничтожения индекса main_indx к таблице emp достаточно записать оператор DROP INDEX main_indx. 6. Оператор создания представления имеет формат вида: CREATE VIEW <имя представления> [(<имя столбца> [,<имя столбца> ]... )] AS <оператор SELECT> Данный оператор позволяет создать представление. Если имена столбцов в представлении не указываются, то будут использоваться имена столбцов из запроса, описываемого соответствующим оператором SELECT. Пример 4. Создание представления. Пусть имеется таблица companies описания производителей товаров с полями: comp_id (идентификатор компании) comp_name (название организации) comp_address (адрес) и phone (телефон) а также таблица goods производимых товаров с полями: type (вид товара), comp_id (идентификатор компании), name (название товара) и price (цена товара). Таблицы связаны между собой по полю comp_id. Требуется создать представление rерr с краткой информацией о товарах и их производителях: вид товара, название производителя и цена товара. Оператор определения представления может иметь следующий вид: CREATE VIEW rерr AS SELECT goods.type, companies.comp_name, goods.price FROM goods, companies WHERE goods.comp_id = companies.comp_id 7. Оператор удаления представления имеет формат вида: DROP VIEW <имя представления> Оператор позволяет удалить созданное ранее представление. Заметим, что при удалении представления таблицы, участвующие в запросе, удалению не подлежат. Удаление представления rерr производится оператором вида: DROP VIEW repr. 8. Оператор выборки записей имеет формат вида: SELECT [ALL | DISTINCT] <список данных> FROM <список таблиц> [WHERE <условие выборки>] [GROUP BY <имя столбца> [,<имя столбца>]... ] [HAVING <условие поиска>] [ORDER BY <спецификация> [,<снецификация>] ...] Это наиболее важный оператор из всех операторов SQL. Функциональные возможности его огромны. Рассмотрим основные из них. Оператор SELECT позволяет производить выборку и вычисления над данными из одной или нескольких таблиц. Результатом выполнения оператора является ответная таблица, которая может иметь (ALL), или не иметь (DISTINCT) повторяющиеся строки. По умолчанию в ответную таблицу включаются все строки, в том числе и повторяющиеся. В отборе данных участвуют записи одной или нескольких таблиц, перечисленных в списке операнда FROM. Список данных может содержать имена столбцов, участвующих в запросе, а также выражения над столбцами. В простейшем случае в выражениях можно записывать, имена столбцов, знаки арифметических операций (+, -,*,/), константы и круглые скобки. Если в списке данных записано выражение, то наряду с выборкой данных выполняются вычисления, результаты которого попадают в новый (создаваемый)' '. столбец ответной таблицы. При использовании в списках данных имен столбцов нескольких таблиц для указания принадлежности столбца некоторой таблице применяют конструкцию вида: <имя та6лицы>.<имя столбца>. Операнд WHERE задает условия, которым должны удовлетворять записи в результирующей таблице. Выражение <условие выборки> является логическим. Его элементами могут быть имена столбцов, операции сравнения, арифметические oneрации, логические связки (И, ИЛИ, НЕТ), скобки, специальные функции LIKE, NULL, IN и т. д. Операнд GROUP BY позволяет выделять в результирующем множестве записей группы. Группой являются записи с совпадающими значениями в столбцах, перечисленных за ключевыми словами GROUP BY. Выделение групп требуется для использования в логических выражениях операндов WHERE и HAVING, а также для выполнения операций (вычислений) над группами. В логических и арифметических выражениях можно использовать следующие групповые операции (функции): AVG (среднее значение в группе), МАХ (максимальное значение в группе), MIN (минимальное значение в группе), SUM (сумма значений в группе), COUNT (число значений в группе). Операнд HAVING действует совместно с операндом GROUP BY и используется для дополнительной селекции записей во время определения групп. Правила записи <условия поиска> аналогичны правилам формирования <условия выборки> операнда WHERE. Операнд ORDER BY задает порядок сортировки результирующего множества. Обычно каждая <спецификация> аналогична соответствующей конструкции оператора CREATE INDEX и представляет собой пару вида: <имя столбца> [ ASC | DESC ]. Замечание. Оператор SELECT может иметь и другие более сложные синтаксические конструкции, которые мы подробно рассматривать не будем; а поясним их смысл. Одной из таких конструкций, например, являются так называемые подзапросы. Они позволяют формулировать вложенные запросы, когда результаты одного оператора SELECT используются в логическом выражении условия выборки операнда WHERE другого оператора SELECT. Вторым примером более сложной формы оператора SELECT является оператор, в котором отобранные записи в дальнейшем предполагается модифицировать (конструкция FOR UPDATE OF). СУБД после выполнения такого оператора обычно блокирует (защищает) отобранные записи от модификации их другими пользователями. Еще один случай специфического использования оператора SELECT - выполнение объединений результирующих таблиц при выполнении нескольких операторов SELECT (операнд UNION). Пример 5. Выбор записей. Для таблицы ЕМР, имеющей поля: NAME (имя), SAL (зарплата), MGR (руководитель) и DEPT (отдел), требуется вывести имена сотрудников и размер их зарплаты, увеличенный на 100 единиц. Оператор выбора можно записать следующим образом: SELECT name, sal+100 FROM emp. Пример 6. Выбор с условием. Вывести названия таких отделов таблицы ЕМР, в которых в данный момент отсутствуют руководители. Оператор SELECT для этого запроса можно записать так: SELECT dept FROM emp WHERE mgr is NULL. Пример 7. Выбор с группированием. Пусть требуется найти минимальную и максимальную зарплаты для каждого из отделов (по таблице ЕМР). Оператор SELECT для этого запроса имеет вид: SELECT dept, MIN(sal), MAX(sal) FROM emp GROUP BY dept. 9. Оператор изменения записей имеет формат вида: UPDATE <имя та6лицы> SET <имя столбца> " {<выражение> , NULL } [, SET <имя столбца> ° {<выражение> , NULL }... ] [WHERE <условие>] Выполнение оператора UPDATE состоит в изменении значений в определенных операндом SET столбцах таблицы для тех записей, которые удовлетворяют условию, заданному операндом WHERE. Новые значения полей в записях могут быть пустыми (NULL), либо вычисляться в соответствии с арифметическим выражением. Правила записи арифметических и логических выражений аналогичны соответствующим правилам оператора SELECT. Пример 8. Изменение записей. Пусть необходимо увеличить на 500 единиц зарплату тем служащим, которые получают не более 6000 (по таблице ЕМР). Запрос, сформулированный с помощью оператора SELECT, может выглядеть так: UPDATE emp SET sal = 6500 WHERE sal <= 6000. 10. Оператор вставки новых записей имеет форматы двух видов: INSERT INTO <имя таблицы> [(<список столбцов>)] VALUES (<список значений?-) и INSERT INTO <имя таблицы> [(<список столбцов>)] <предложение SELECT> В первом формате оператор INSERT предназначен для ввода новых записей с заданными значениями в столбцах. Порядок перечисления имен столбцов должен со-. ответствовать порядку значений, перечисленных в списке операнда VALUES. Если <список столбцов> опущен, то в <списке значений> должны быть перечислены все значения в порядке столбцов структуры таблицы. Во втором формате оператор INSERT предназначен для ввода в заданную таблицy новых строк, отобранных из другой таблицы с помощью предложения SELECT. Пример 9. Ввод записей. Ввести в таблицу ЕМР запись о новом сотруднике. Для этого можно записать, такой оператор вида: INSERT INTO emp VALUES ("Ivanov", 7500, "Lee", "cosmetics"). 11. Оператор удаления записей имеет формат вида: DELETE FROM <имя таблицы> [WHERE <условие>] Результатом выполнения оператора DELETE является удаление из указанной таблицы строк, которые удовлетворяют условию, определенному операндом WHERE. Если необязательный операнд WHERE опущен, т. е. условие отбора удаляемых записей отсутствует, удалению подлежат все записи таблицы. Пример 10. Удаление записей. В связис ликвидацией отдела игрушек (toy), требуется удалить из таблицы ЕМР всех сотрудников этого отдела. Оператор DELETE для этой задачи будет выглядеть так: DELETE FROM emp WHERE dept = "toy". В заключение отметим, что, по словам Дейта, язык SQL является гибридом реляционной алгебры и реляционного исчисления. В нем имеются элементы алгебры (оператор объединения UNION) и исчисления (квантор существования EXISTS). Кроме того, язык SQL обладает реляционной полнотой.
НАВЕРХ
4. Информационные системы в сетях
Создание и применение информационных систем в сетях компьютеров, с одной стороны дает заметные преимущества, с другой стороны, вызывает ряд проблем. В частности, возникают проблемы администрирования и защиты информации. В разделе рассматриваются основные понятия, связанные с сетями компьютеров и информационными системами в них, варианты архитектуры клиент-сервер, управление данными и доступ к ним, особенности информационных систем в локальных сетях, Internet и intranet.
3.7. Основные понятия
Основные понятия сетей ЭВМ раскроем, рассматривая виды и состав сетей, используемое программное и аппаратное обеспечение, а также методы управления ресурсами.
Виды и состав сетей
Сетью называется совокупность компьютеров или рабочих станций (PC), объединенных средствами передачи данных. Средства передачи данных, в свою очередь, в общем случае могут состоять из следующих элементов: связных компьютеров, каналов связи (спутниковых, телефонных, цифровых, волоконно-оптических, радио- и / других), коммутирующей аппаратуры, ретрансляторов, различного рода преобразователей сигналов и других элементов и устройств. Современные сети можно классифицировать по различным признакам: по удаленности компьютеров, топологии, назначению, перечню предоставляемых услуг, принципам управлений (централизованные и децентрализованные), методам коммутации (без коммутации, телефонная коммутация, коммутация цепей, сообщений, пакетов и дейтаграмм), видам среды передачи и т.д. В зависимости от удаленности компьютеров сети условно разделяют на локальные и глобальные. Произвольная глобальная сеть может включать другие глобальные сети, локальные сети, а также отдельно подключаемые к ней компьютеры (удаленные компьютеры) или отдельно подключаемые устройства ввода-вывода. Глобальные сети различают четырех основных видов: городские, региональные, национальные и транснациональные. В качестве устройств ввода-вывода могут использоваться, например, печатающие и копирующие устройства, кассовые и банковские аппараты, дисплеи (терминалы) и факсы. Перечисленные элементы сети могут быть удалены друг от друга на значительное расстояние. Примером глобальной сети служит одна из первых в мире сеть ARPANET, а также сеть Интернет. В локальных вычислительных сетях (ЛВС) компьютеры расположены на расстоянии до нескольких километров и обычно соединены при помощи скоростных линий связи со скоростью обмена от 1 до 10 и более Мбитов/с (не исключается соединение компьютеров и с помощью низкоскоростных телефонных линий). ЛВС обычно развертываются в рамках некоторой организации (корпорации, учреждения). Поэтому их иногда называют корпоративными системами или сетями. Компьютеры при этом, как правило, находятся в пределах одного помещения, здания или соседних зданий. В глобальной сети основным видом взаимодействия между независимыми компьютерами является обмен сообщениями. Более интенсивный обмен информацией происходит в локальных сетях. В них, по существу, организовано управление аппаратно-программными ресурсами всех входящих в сеть компьютеров. Реализует эти функции сетевое ПО. Вкратце остановимся на программно-аппаратных ресурсах и методах управления ими в ЛВС.
Программное обеспечение ЛВС
Независимо от того, в какой сети работает некоторый компьютер, функции установленного на нем программного обеспечения условно можно разделить на две группы: управление ресурсами самого компьютера (в том числе и в интересах решения задач для других компьютеров) управление обменом с другими компьютерами (сетевые функции). Собственными ресурсами компьютера традиционно управляет ОС. Функции сетевого управления реализует сетевое ПО, которое может быть выполнено как в виде отдельных пакетов сетевых программ, так и виде сетевой ОС (СОС). При разработке сетевого ПО используется иерархический подход, предполагающий определение совокупности сравнительно независимых уровней и интерфейсов между ними. Это позволяет легко модифицировать алгоритмы программ произвольного уровня без существенного изменения других уровней. В общем случае допускается упрощение функций некоторого уровня или даже его полная ликвидация. Для упорядочения разработки сетевого ПО и обеспечения возможности взаимодействия любых вычислительных систем, Международная Организация по Стандартизации (International Organization for Standardization - ISO) разработала Эталонную Модель взаимодействия открытых систем (Open System Interconnection Reference model - модель OSI). Эталонная Модель определяет следующие семь функциональных уровней: физический (physical layer); канальный или управления линией (звеном) передачи (data link); сетевой (network layer); транспортный (transport layer); сеансовый (session layer); представительный (presentation layer); прикладной или уровень приложений (application layer). Отличия сетей друг от друга вызваны особенностями используемого аппаратного и программного обеспечения, различной интерпретацией рекомендаций фирмами-разработчиками, различием требований к системе со стороны решаемых задач (требования защищенности информации, скорости обмена, безошибочности передачи данных и т.д.) и другими причинами. В сетевом ПО локальных сетей часто наблюдается сокращение числа реализуемых уровней.
Аппаратные средства ЛВС
Основными аппаратными компонентами ЛВС являются: рабочие станции, серверы, интерфейсные платы и кабели. Рабочие станции (PC) - это, как правило, персональные ЭВМ, которые являются рабочими местами пользователей сети. Иногда в PC, непосредственно подключенной к сетевому кабелю, могут отсутствовать накопители на магнитных дисках. Такие PC называют бездисковыми рабочими станциями. Основным преимуществом бездисковых PC является низкая стоимость, а также высокая защищенность от несанкционированного проникновения в систему пользователей и компьютерных вирусов. Недостаток бездисковой PC заключается в невозможности работать в автономном режиме (без подключения к серверу) и иметь собственные архивы данных и программ. Серверы в ЛВС выполняют функции распределения сетевых ресурсов. Обычно его функции возлагают на достаточно мощный ПК, мини-ЭВМ, большую ЭВМ или специальную ЭВМ-сервер. В одной сети может быть один или несколько серверов. Каждый из серверов может быть отдельным или совмещенным с PC. В последнем случае только часть ресурсов сервера оказывается общедоступной. При наличии в ЛВС нескольких серверов, каждый из них управляет работой подключенных к нему PC. Совокупность компьютеров сервера и относящихся к нему PC часто называют доменом. Иногда в одном домене находится несколько серверов. Обычно один из них является главным, а другие - выполняют роль резерва (на случай отказа главного сервера) или логического расширения основного сервера. Используемые сетевые адаптеры имеют три основные характеристики: тип шины компьютера, к которому они подключаются (ISA, EISA, Micro Channel и пр.), разрядность (8, 16, 32, 64) и используемый метод доступа к сетевому каналу данных. Существуют различные схемы объединения компьютеров в ЛВС. Классическими считаются топологии "звезда", "кольцо" и "общая шина". Наиболее широко используются следующие стандартизованные методы доступа к сетевому каналу: Ethernet (поддерживает шинную топологию); Arcnet (поддерживает звездную топологию); Token-Ring (поддерживает кольцевую топологию). Конфигурация соединения элементов в сеть (топология) во многом определяет такие важнейшие характеристики сети, как ее надежность, производительность, стоимость, защищенность и т.д. Одним из подходов к классификации топологий ЛВС является выделение двух основных классов топологий: широковещательныхпоследовательных. В широковещательных конфигурациях каждый персональный компьютер передает сигналы, которые могут быть восприняты остальными компьютерами. К таким конфигурациям относятся топологии "общая шина", "дерево", "звезда с пассивным центром". Сеть типа "звезда с пассивным центром" можно рассматривать как разновидность "дерева", имеющего корень с ответвлением к каждому подключенному устройству. В последовательных конфигурациях каждый физический подуровень передает информацию одному компьютеру. Примерами последовательных конфигураций являются: произвольная (произвольное соединение компьютеров), иерархическая, "кольцо", "цепочка", "звезда с интеллектуальным центром", "снежинка". Для соединения компьютеров в ЛВС чаще всего используют коаксиальный кабель (тонкий и толстый). Помимо коаксиального кабеля может применяться "витая пара" и оптоволокно. В последнее время ведутся интенсивные работы по разработке и внедрению беспроводных радиосетей. Известные системы на их основе, по сравнению с кабельными системами, пока значительно уступают по скорости передачи данных и дальности приема (сотни метров), но позволяют создавать мобильные распределенные системы. К дополнительному оборудованию ЛВС относят источники бесперебойного питания, модемы, трансиверы, повторители, а также различные разъемы (коннекторы, терминаторы).
Принципы управления
Существует два основных метода (принципа) управления в ЛВС: централизованное децентрализованное. В централизованных сетях одна или несколько ПЭВМ являются центральными, а остальные - рабочими станциями (PC). Центральный узел сети, часто называемый компьютером-сервером (КС), может находиться на отдельном компьютере или совмещаться с PC. В первом случае говорят о выделенном КС, а во втором - о совмещенном КС. Основное назначение КС - управление передачей данных в сети и хранение файлов, используемых многими PC. Исходя из этого, под КС обычно выделяют наиболее производительную и имеющую значительную память ПЭВМ. Кроме того, к КС обычно подключается дорогостоящее оборудование (лазерные принтеры, факсы, модемы, сканеры и т. д.). Существует множество сетевых ОС, реализующих централизованное управление. Среди них Microsoft Windows NT Server, Novell NetWare (версии З.Х и 4.Х), Microsoft Lan Manager, OS/2 Warp Server Advanced, VINES 6.0 и другие. Преимуществом централизованных сетей является высокая защищенность сетевых ресурсов от несанкционированного доступа, удобство администрирования сети, возможность создания сетей с большим числом узлов. Основной недостаток состоит в уязвимости системы при нарушении работоспособности файл-сервера (это преодолевается при наличии нескольких серверов или принятии других мер), а также в предъявлении довольно высоких требований к ресурсам серверов. Сети с децентрализованным управлением (одноранговые сети) не содержат КС. В них функции управления сетью в соответствии с некоторой дисциплиной поочередно передаются от одной PC к другой. Децентрализованное управление, как правило, применяется в сетях со слабыми компьютерами и простейшими обменами между ними" на уровне файлов, а также без серьезного контроля прав доступа к ресурсам сети. Основные ресурсы всех PC обычно оказываются общедоступными, хотя система не всегда обеспечивает корректное их совместное использование на прикладном уровне. Наиболее распространенными программными продуктами, позволяющими строить одноранговые сети, являются следующие программы и пакеты: Novell NetWare Lite, Windows for Workgroups, Windows 95/98, Artisoft LANtastic, LANsmart, Invisible Software NET-30 и другие. Развертывание одноранговой сети для небольшого числа PC часто позволяет построить более эффективную и живучую распределенную вычислительную среду. Сетевое программное обеспечение в них является более простым по сравнению с централизованными сетями. Здесь не требуется установка файл-сервера (компьютера и соответствующих программ), что существенно удешевляет систему. Однако, такие сети слабее с точки зрения защиты информации и администрирования. Говоря о сетях, часто используют термины "сервер" и "клиент". Любое взаимодействие в сети предполагает как минимум два элемента: потребляющий и предоставляющий ресурсы (сервис или услуги). Потребитель ресурсов называется клиентом, а предоставляющий ресурсы компонент - сервером (см. раздел 1). Основными видами ресурсов являются следующие: аппаратные (целая ЭВМ, дисковый накопитель, устройство печати и т. д.), программные и информационные. Если в качестве ресурса рассматривается вся ЭВМ, то говорят о компьютере-клиенте и компьютере-сервере. Если подразумевается некоторый аппаратный ресурс, то используют такие термины как: диск-сервер (файловый сервер или файл-сервер), сервер печати. Типичными клиентами в сетях являются: ЭВМ, пользователь или программа. Возможно уточнение назначения компьютера при обработке информации. Тогда говорят о серверах сообщений (обработка поступающих сообщений), серверах БД (обработка запросов к БД), серверах приложений (выполнение приложений пользователя) и т. д. Иногда одним термином называют разные (аппаратные, программные или аппаратно-программные) компоненты вычислительной системы. Так, сервером печати может служить компьютер с подключенным к нему принтером, программа печати или компьютер с программным обеспечением управления печатью.
НАВЕРХ
4.2. Модели архитектуры клиент-сервер
При построении распределенных ИС, работающих с БД, широко используется архитектура клиент-сервер. Ее основу составляют принципы организации взаимодействия клиента и сервера при управлении БД. Один из вариантов архитектуры клиент-сервер рассмотрен в подразделе 1.2. Чтобы охарактеризовать основные схемы взаимодействия процессов управления БД, воспользуемся Эталонной моделью Архитектуры открытых систем OSI. Согласно этой модели, функция управления БД относится к прикладному уровню. Остановимся на двух самых верхних уровнях: прикладном и представительном, которые в наибольшей степени являются предметом внимания со стороны разработчика и пользователя. Остальные функции будем считать связными функциями, необходимыми для реализации двух первых. При этом будем придерживаться широкого толкования термина СУБД, понимая под ним все программные системы, которые используют информацию из БД. Как поддерживающая интерфейс с пользователем программа, СУБД, в общем случае, реализует следующие основные функции: управление данными, находящимися в базе; обработка информации с помощью прикладных программ; представление информации в удобном для пользователя виде. Если система размещается на одной ЭВМ, то все функции собраны в одной программе и вызываются по схеме, подобной рассмотренной в разделе 1. При размещении СУБД в сети возможны различные варианты распределение функций по узлам. В зависимости от числа узлов сети, между которыми выполняется распределение функций СУБД, можно выделить двухзвенные модели, трехзвенные модели и т. д. Место разрыва функций соединяется коммуникационными функциями (средой передачи информации в сети).
Двухзвенные модели распределения функций
Двухзвенные модели соответствуют распределению функций СУБД между двумя узлами сети. Компьютер (узел сети), на котором обязательно присутствует функция управления данными, назовем компьютером-сервером. Компьютер, близкий к, пользователю и обязательно занимающийся вопросами представления информации, назовем компьютером-клиентом. Наиболее типичными вариантами (рис. 4.1) разделения функций между компьютером-сервером и компьютером-клиентом являются следующие: распределенное представление; удаленное представление; распределенная функция; удаленный доступ к данным; распределенная БД. Перечисленные способы распределения функций в системах с архитектурой клиент-сервер иллюстрируют различные варианты: от мощного сервера, когда практически вся работа производится на нем, до мощного клиента, когда большая часть функций выполняется на рабочей станции, а сервер обрабатывает поступающие к нему по сети SQL-вызовы. В моделях удаленного доступа к данным и удаленного представления производится строгое распределение функций между компьютером-клиентом и компьютером-сервером. В других моделях имеет место выполнение одной из следующих функций одновременно на двух компьютерах: управления данными (модель распределенной БД), обработки информации (модель распределенной функции), представления информации (модель распределенного представления). Рассмотрим сначала модели удаленного доступа к данным и удаленного представления (сервера БД) как наиболее широко распространенные. В модели удаленного доступа к данным (Remote Data Access - RDA) программы, реализующие функции представления информации и логику прикладной обработки, совмещены и выполняются на компьютере-клиенте. Обращение за сервисом управления данными происходит через среду передачи с помощью операторов языка SQL или вызовом функций специальной библиотеки API (Application Programming Interface - интерфейса прикладного программирования). Основное достоинство RDA-модели состоит в большом обилии готовых СУБД, имеющих SQL-ннтерфейсы, и существующих инструментальных средств, обеспечивающих быстрое создание программ клиентской части. Средства разработки чаще всего поддерживают графический интерфейс пользователя в MS Windows, стандарт интерфейса ODBC и средства автоматической генерации кода. Подавляющее большинство средств разработки использует языки четвертого поколения. Недостатками RDA-модели являются, во-первых, довольно высокая загрузка системы передачи данных вследствие того, что вся логика сосредоточена в приложении, а обрабатываемые данные расположены на удаленном узле. Как увидим далее, во время работы приложений обычно по сети передаются целые БД. Во-вторых, системы, построенные на основе модели RDA, неудобны с точки зрения разработки, модификации и сопровождения. Основная причина состоит в том, что в получаемых приложениях прикладные функции и функции представления тесно взаимосвязаны. Поэтому даже при незначительном изменении функций системы требуется переделка всей прикладной ее части, усложняющая разработку и модификацию системы. Модель сервера БД (DataBase Server - DBS) отличается от предыдущей модели тем, что функции компьютера-клиента ограничиваются функциями представления информации, в то время как прикладные функции обеспечиваются приложением, находящимся на компьютере-сервере. Эта модель является более технологичной, чем RDA-модель и применяется в таких СУБД, как Ingress, Sybase и Oracle. При этом приложения реализуются в виде хранимых процедур. Процедуры обычно хранятся в словаре БД и разделяются несколькими клиентами. В общем случае хранимые процедуры могут выполняться в режимах компиляции и интерпретации. Достоинствами модели DBS являются: возможность хорошего централизованного администрирования приложений на этапах разработки, сопровождения и модификации, а также эффективное использование вычислительных и коммуникационных ресурсов. Последнее достигается за счет того, что выполнение программ в режиме коллективного пользования требует существенно меньших затрат на пересылку данных в сети. Один из недостатков модели DBS связан с ограничениями средств разработки хранимых процедур. Основное ограничение - сильная привязка операторов хранимых процедур к конкретной СУБД. Язык написания хранимых процедур, по сути, является процедурным расширением языка SQL, и не может соперничать по выразительным средствам и функциональным возможностям с традиционными языками третьего поколения, такими, как С и Pascal. Кроме того, в большинстве СУБД нет удовлетворительных средств отладки и тестирования хранимых процедур, что делает их механизм опасным инструментом - неотлаженные программы могут приводить к некорректностям БД, зависаниям серверных и клиентских программ во время работы системы и т. п. Другим недостатком DBS-модели является низкая эффективность использования вычислительных ресурсов ЭВМ, поскольку не удается организовать управление входным потоком запросов к программам компьютера-сервера, а также обеспечить перемещение процедур на другие компьютеры-серверы. В модели распределенного представления имеется мощный компьютер-сервер, а клиентская часть системы практически вырождена. Функцией клиентской части является просто отображение информации на экране монитора и связь с основным компьютером через локальную сеть. СУБД подобного рода могут иметь место в сетях, поддерживающих работу так называемых Х-терминалов. В них основной компьютер (хост-машина) должен иметь достаточную мощность, чтобы обслуживать несколько Х-терминалов. X-терминал тоже должен обладать достаточно быстрым процессором и иметь достаточный объем оперативной памяти (дисковые накопители отсутствуют). Часто Х-терминалы создают на базе RISC-компьютеров (restricted [reduced] instruction set computer) - компьютеров с сокращенным набором команд. Все программное обеспечение находится на хост-машине. Программное обеспечение Х-терминала, выполняющее функции управления представлением и сетевые функции, загружается по сети с сервера при включении Х-терминала. Модель распределенного представления имели СУБД ранних поколений, которые работали на малых, средних и больших ЭВМ. В роли Х-терминалов выступали дисплейные станции и абонентские пункты (локальные и удаленные). В этом случае основную часть функций представления информации реализовывали сами СУБД, а окончательное построение изображении на терминалах пользователя выполнялось на оконечных устройствах. По модели распределенного представления построены системы обслуживания пользователей БД в гетерогенной (неоднородной) среде. Серверная часть таких систем обычно обеспечивает некоторый унифицированный интерфейс, а клиентские части реализуют функции учета специфики оконечного оборудования или преобразования одного формата представления информации в другой. Модель распределенного представления реализует централизованную схему управления вычислительными ресурсами. Отсюда следуют ее основные достоинства - простота обслуживания и управления доступом к системе и относительная дешевизна (ввиду невысокой стоимости оконечных терминалов). Недостатками модели являются уязвимость системы при невысокой надежности центрального узла, а также высокие требования к серверу но производительности при большом числе клиентов. В модели распределенной функции логика обработки данных распределена по двум узлам. Такую модель могут иметь ИС, в которых общая часть прикладных функций реализована на компьютере-сервере, а специфические функции обработки информации выполняются на компьютере-клиенте. Функции общего характера могут включать в себя стандартное обеспечение целостности данных, например, в виде хранимых процедур, а оставшиеся прикладные функции реализуют специальную прикладную обработку. Подобную модель имеют также ИС, использующие информацию из нескольких неоднородных БД. Модель распределенной БД предполагает использование мощного компьютера-клиента, причем данные хранятся на компьютере-клиенте и на компьютере-сервере. Взаимосвязь обеих баз данных может быть двух разновидностей: а) в локальной и удаленной базах хранятся отдельные части единой БД; б) локальная и удаленная БД являются синхронизируемыми друг с другом копиями. Достоинством модели распределенной БД является гибкость создаваемых па ее основе ИС, позволяющих компьютеру-клиенту обрабатывать локальные и удаленные БД. При наличии механизмов координации соответствия копий система в целом, кроме того, обладает высокой живучестью, так как разрыв соединения клиента и сервера не приводит к краху системы, а ее работа может быть восстановлена с возобновлением соединения. К недостатку модели можно отнести высокие затраты при выполнении большого числа одинаковых приложений на компьютерах-клиентах.
Трехзвенная модель распределения функций
Трехзеенная модель распределения функций представляет собой типовой вариант, при котором каждая из трех функций приложения реализуется на отдельном компьютере. Варианты распределения функций приложения на большее число компьютеров могут иметь место, но ввиду их редкого применения рассматриваться не будут. Рассматриваемая нами модель имеет название модель сервера приложений, или AS-модель (Application Server) и показана на рис. 4.2. Согласно трехзвенной AS-модели, отвечающий за организацию диалога с конечным пользователем процесс, как обычно, реализует функции представления информации и взаимодействует с компонентом приложения так же, как в модели DBS. Компонент приложения, располагаясь на отдельном компьютере, в свою очередь, связано компонентом управления данными подобно модели RDA. Центральным звеном AS-модели является сервер приложений. На сервере приложений реализуется несколько прикладных функций, каждая из которых оформлена как служба предоставления услуг всем требующим этого программам. Серверов приложений может быть несколько, причем каждый из них предоставляет свой вид сервиса. Любая программа, запрашивающая услугу у сервера приложений, является для него клиентом. Поступающие от клиентов к серверам запросы помещаются в очередь, из которой выбираются в соответствии с некоторой дисциплиной, например, по приоритетам. Компонент, реализующий функции представления и являющийся клиентом для сервера приложений, в этой модели трактуется более широко, чем обычно. Он может служить для организации интерфейса с конечным пользователем, обеспечивать прием данных от устройств, например, датчиков, или быть произвольной программой. Достоинством AS-модели является гибкость и универсальность вследствие разделения функций приложения на три независимые составляющие. Во многих случаях эта модель оказывается более эффективной по сравнению с двухзвенными. Основной недостаток модели - более высокие затраты ресурсов компьютеров на обмен информацией между компонентами приложения по сравнению с двухзвенными моделями.
Сложные схемы взаимодействия
Возможны более сложные схемы взаимодействия, например, схемы, в которых элемент, являющийся сервером для некоторого клиента, в свою очередь, выступает в роли клиента по отношению к другому серверу (рис. 4 3). Пример этого мы наблюдали в AS-модели. Возможно также, что в распределенной вычислительной системе при работе с БД имеются множественные связи (статические), когда один объект по отношению к одним является клиентом, а но отношению к другим - сервером (рис. 4.4). При рассмотрении взаимодействия объектов в динамике получаются еще более сложные схемы взаимодействия. Примером такой схемы является случай, когда в процессе работы роли объектов меняются: объект, являющийся в некоторый момент времени клиентом по отношению к другому объекту, в последующем становится сервером для другого объекта.
НАВЕРХ
4.3. Управление распределенными данными
С управлением данными в распределенных системах связаны следующие две группы проблем: поддержка соответствия БД вносимым изменениям и обеспечение совместного доступа нескольких пользователей к общим данным.
Поддержка соответствия БД вносимым изменениям
В современных распределенных системах информация может храниться централизовано или децентрализовано. В первом случае проблемы идентичности представления информации для всех пользователей не существует, так как все последние изменения хранятся в одном месте. На практике чаще информация изменяется одновременно в нескольких узлах распределенной вычислительной системы. В этом случае возникает проблема контроля за всеми изменениями информации и предоставления ее в достоверном виде всем пользователям. Существуют две основные технологии децентрализованного управления БД: распределенных БД (Distributed Database) тиражирования, или репликации, БД (Data Replication). Распределенная БД состоит из нескольких фрагментов, размещенных на разных узлах сети и, возможно, управляемых разными СУБД. С точки зрения программ и пользователей, обращающихся к распределенной БД, последняя воспринимается как единая локальная БД (рис. 4.6). Информация о местоположении каждой из частей распределенной БД и другая служебная информация хранится в так называемом глобальном словаре данных. В общем случае этот словарь может храниться на одном из узлов или тоже быть распределенным. Для обеспечения корректного доступа к распределенной БД в современных системах чаще всего применяется протокол (метод) двухфазной фиксации транзакций (two-phase commit). Суть этого метода состоит в двухэтапной синхронизации выполняемых изменений на всех задействованных узлах. На первом этапе в узлах сети производятся изменения (пока обратимые) в их БД, о чем посылаются уведомления компоненту системы, управляющему обработкой распределенных транзакций. На втором этапе, получив от всех узлов сообщения о правильности выполнения операций (что свидетельствует об отсутствии сбоев и отказов аппаратно-программного обеспечения), управляющий компонент выдает всем узлам команду фиксации изменений. После этого транзакция считается завершенной, а ее результат необратимым. Основным достоинством модели распределенной БД является то, что пользователи всех узлов (при исправных коммуникационных средствах) получают информацию с учетом всех последних изменений. Второе достоинство состоит в экономном использовании внешней памяти компьютеров, что позволяет организовывать БД больших объемов. К недостаткам модели распределенной БД относится следующее: жесткие требования к производительности и надежности каналов связи, а также большие затраты коммуникационных и вычислительных ресурсов из-за их связывания на все время выполнения транзакций. При интенсивных обращениях к распределенной БД, большом числе взаимодействующих узлов, низкоскоростных и ненадежных каналах связи обработка запросов по этой схеме становится практически невозможной. Модель тиражирования данных, в отличие от технологии распределенных БД, предполагает дублирование данных (создание точных копий) в узлах сети (рис. 4.7). Данные всегда обрабатываются как обычные локальные. Поддержку идентичности копий друг другу в асинхронном режиме обеспечивает компонент системы, называемый репликатором (replicator). При этом между узлами сети могут передаваться как отдельные изменения, так и группы изменений. В течение некоторого времени копии БД могут отличаться друг от друга. К основным достоинствам модели тиражирования БД (в сравнении с предыдущей моделью) относятся: более высокая скорость доступа к данным, так как они всегда есть в узле; существенное уменьшение передаваемого по каналам связи потока информации, поскольку происходит передача не всех операций доступа к данным, а только изменений в БД; повышение надежности механизмов доступа к распределенным данным, поскольку нарушение связи не приводит к потере работоспособности системы (предполагается буферизация потока изменений, позволяющая корректно возобновить работу после восстановления связи). Основной недостаток модели тиражирования БД заключается в том, что на некотором интервале времени возможно "расхождение" копий БД. Если отмеченный недостаток некритичен для прикладных задач, то предпочтительно иметь схему с тиражированием БД.
Доступ к общим данным
При обслуживании обращений к общим данным средства управления БД должны обеспечивать по крайней мере два основных метода доступа: монопольный и коллективный. Основными объектами доступа в различных системах могут быть целиком БД, отдельные таблицы, записи, поля записей. В СУБД, предоставляющих возможность разработки, объектами доступа также могут выступать спецификации отчетов и экранных форм, запросы и программы. Монопольный доступ обычно используется в двух случаях: во-первых, когда требуется исключить доступ к объектам со стороны других пользователей (например, при работе с конфиденциальной информацией); во-вторых, когда производятся ответственные операции с БД, не допускающие других действий, например, изменение структуры БД. В первом случае пользователь с помощью диалоговых средств СУБД или прикладной программы устанавливает явную блокировку. Во втором случае пользователь тоже может установить явную блокировку, либо положиться на СУБД. Последняя обычно автоматически устанавливает неявную (без ведома пользователя или приложения) блокировку, если это необходимо. В режиме коллективного доступа полная блокировка на используемые объекты как правило, не устанавливается. Коллективный доступ возможен, например, при одновременном просмотре таблиц. Попытки получить монопольный доступ к объектам коллективного доступа должны быть пресечены. Например, в ситуации, когда один или несколько пользователей просматривают таблицу, а другой пользователь собирается удалить эту же таблицу. Для организации коллективного доступа в СУБД применяется механизм блокировок. Суть блокировки состоит в том, что на время выполнения какой-либо операции в БД доступ к используемому объекту со стороны других потребителей временно запрещается или ограничивается. Например, при копировании таблицы она блокируется от изменения, хотя и разрешено просматривать ее содержимое. Рассмотрим некоторый типичный набор блокировок. В конкретных программах схемы блокирования объектов могут отличаться от описываемой. Выделим четыре вида блокировок, перечисленные в порядке убывания строгости ограничений на возможные действия: полная блокировка; блокировка от записи; предохраняющая блокировка от записи; предохраняющая полная блокировка. Полная блокировка. Означает полное запрещение всяких операций над основными объектами (таблицами, отчетами и экранными формами). Этот вид блокировки обычно применяется при изменении структуры таблицы. Блокировка от записи. Накладывается в случаях, когда можно использовать таблицу, но без изменения ее структуры или содержимого. Такая блокировка применяется, например, при выполнении операции слияния данных из двух таблиц. Предохраняющая блокировка от записи. Предохраняет объект от наложения на него со стороны других операций полной блокировки, либо блокировки от записи. Этот вид блокировки позволяет тому, кто раньше "захватил" объект, успешно завершить модификацию объекта. Предохраняющая блокировка от записи совместима с аналогичной блокировкой (предохраняющей блокировкой от записи), а также с предохраняющей полной блокировкой (см. далее). Примером необходимости использования этой блокировки является режим совместного редактирования таблицы несколькими пользователями. Предохраняющая полная блокировка. Предохраняет объект от наложения на него со стороны других операций только полной блокировки. Обеспечивает максимальный уровень совместного использования объектов. Такая блокировка может использоваться, например, для обеспечения одновременного просмотра несколькими пользователями одной таблицы. В группе пользователей, работающих с одной таблицей, эта блокировка не позволит никому изменить структуру общей таблицы. При незавершенной операции с некоторым объектом и запросе на выполнение новой операции с этим же объектом производится попытка эти операции совместить. Совмещение возможно тогда, когда совместимыми оказываются блокировки, накладываемые конкурирующими операциями. В отношении перечисленных выше четырех блокировок действуют следующие правила совмещения: при наличии полной блокировки над объектом нельзя производить операции, приводящие хотя бы к одному из видов блокировок (полная блокировка несовместима ни с какой другой блокировкой); блокировка от записи совместима с аналогичной блокировкой и предохраняющей полной блокировкой; предохраняющая блокировка от записи совместима с обеими видами предохраняющих блокировок; предохраняющая полная блокировка совместима со всеми блокировками, кроме полной. Обычно в СУБД каждой из выполняемых с БД операций соответствует определенный вид блокировки, которую эта операция накладывает на объект. Пользователям современных СУБД, работающим в интерактивном режиме, не нужно помнить все тонкости механизма блокировки, поскольку система достаточно "разумно" осуществляет автоматическое блокирование во всех случаях, когда это требуется. При этом система сама стремится предоставить всем пользователям наиболее свободный доступ к объектам. При необходимости пользователь и программист может воспользоваться командными или языковыми средствами явного определения блокировок. Например, в СУБД Paradox для явного блокирования отдельной записи во время редактирования таблицы используется команда Record | Lock.
Тупики
Если не управлять доступом к совместно используемым объектам, то между потребителями ресурсов могут возникать тупиковые ситуации (клинчи, "смертельные объятия" или блокировки). Следует отличать понятие блокировки в смысле контроля доступа к объектам (мы придерживаемся такого термина) от блокировки в смысле тупикового события. Существует два основных вида тупиков: взаимные (deadlock) односторонние (livelock). Простейшим случаем взаимного тупика является ситуация, когда каждый из двух пользователей стремится захватить данные, уже захваченные другим пользователем (рис. 4.8а). В этой ситуации пользователь-1 ждет освобождения ресурса N, в то время как пользователь-2 ожидает освобождения от захвата ресурса М. Следовательно, никто из них не может продолжить работу. В действительности могут возникать и более сложные ситуации, когда выполняются обращения трех и более пользователей к нескольким ресурсам. Пример одной из таких ситуаций приведен на рис. 4.86. Односторонний тупик возникает в случае требования получить монопольный доступ к некоторому ресурсу как только он станет доступным и невозможности удовлетворить это требование. Системы управления распределенными БД, очевидно, должны иметь соответствующие средства обнаружения или предотвращения конфликтов, а также разрешения возникающих конфликтов. Одной из наиболее сложных является задача устранения конфликтов в неоднородных системах в случае, если некоторая программа не обрабатывает или обрабатывает некорректно сигналы (уведомления) о наличии конфликтов. При этом важно не только сохранить целостность и достоверность данных в распределенных БД, но и восстановить вычислительный процесс, иногда парализующий пользователей и программы ожиданием чего-то. Пользователи и разработчики приложений в распределенной среде должны предусматривать обработку сигналов о тупиках.
4.4. Информационные системы в локальных сетях
Локальная вычислительная сеть дает пользователю прежде всего возможность более эффективной организации групповых работ и совместного использования аппаратных ресурсов: принтеров, факсов, модемов, сканеров, дисков и т. д., а также программно-информационных ресурсов, в том числе баз данных. Рассмотрим основные схемы организации работы с данными в ЛВС. Спектр возможных схем построения информационной системы в ЛВС существенно зависит от возможностей используемых СОС. Основным сервисом современных ЛВС, независимо от типа управления в них (централизованные или одноранговые), является предоставление доступа одного компьютера (компьютера-клиента) к дискам, каталогам (папкам) и файлам другого компьютера (компьютера-сервера). Так, при обращении к внешнему файлу СОС сначала передает по сети файл (часть файла) в оперативную память компьютера, а по завершении работы с ним при необходимости возвращает обновленную версию. Кроме того, полезной функцией является возможность запуска на компьютере программ, хранящихся на другом компьютере. Эти возможности примерно в равной мере предоставляются сетевыми ОС такими, как Novell NetWare З.х (4.х), Windows NT и Windows 95/98. Более слабые сетевые пакеты и утилиты могут предоставлять доступ к информации без автоматического запуска программ. В этом случае пользователь должен сначала скопировать программы и файлы с другого компьютера на свой, после чего запустить программу. Как и на отдельном компьютере, в ЛВС пользователь может управлять БД с помощью средств некоторой СУБД или работая с приложением. В общем случае приложение может выполняться под управлением СУБД или ее ядра, либо быть независимым и выполняться как автономная программа. Для удобства в дальнейшем под СУБД будем понимать любой из этих вариантов. В локальной сети персональных ЭВМ выделяют следующие три варианта создания информационной системы: типа файл-сервер; типа клиент-сервер; основанные на технологии intranet. Информационные системы типа файл-сервер можно строить двумя способами: с использованием несетевых СУБД, предназначенных для применения на отдельной машине; с использованием сетевых СУБД, разрабатываемых для применения в ЛВС. Под сетевой СУБД здесь понимается система с произвольной моделью данных (не обязательно сетевой), ориентированная на использование в сети. Программы несетевой СУБД и используемые ею данные могут храниться на компьютере-сервере (КС) и на компьютере-клиенте (КК). Запуск и функционирование несетевой СУБД, хранящейся на КК и работающей с локальными данными не отличается от обычного режима работы на отдельной ПЭВМ. Если используемые данные хранятся на КС, файловая система сетевой ОС "незаметно" для СУБД выполняет подгрузку нужного файла с удаленного компьютера. Заметим, что не каждая несетевая СУБД без проблем работает в среде любой сетевой ОС. Если несетевая СУБД используется несколькими пользователями сети, то ее программы, а также БД или ее часть в целях экономии дисковой памяти эффективнее хранить на КС. Хранимую на КС БД будем называть центральной БД (ЦБД), а хранимую на КК БД - локальной БД (ЛБД). При запуске СУБД в таком варианте на каждый КК обычно пересылается полная копия основной программы СУБД и один или несколько файлов ЦБД (рис. 4.9). После завершения работы файлы ЦБД должны пересылаться с КК обратно на КС для согласования данных. Существенным недостатком такого варианта применения несетевых СУБД является возможность нарушения целостности данных при одновременной работе с одной БД нескольких пользователей. Поскольку каждая копия СУБД функционирует "не зная" о работе других копий СУБД, то никаких мер по исключению возможных конфликтов не принимается. При этом элементарные операции чтения-записи одних и тех же файлов, как правило, контролирует сетевая ОС. В качестве примеров несетевых СУБД можно назвать первые версии системы dBase III Plus, dBase IY и FoxBase. Сетевые СУБД не имеют указанного недостатка, так как в них предусматривается "контроль соперничества" (concurrency control). Средства контроля позволяют осуществлять координацию доступа к данным, например, введением блокировок к файлам, записям и даже отдельным полям записей (рис. 4.10). В сетевых СУБД с коллективным использованием файлов БД по-прежнему вся обработка информации производится на КК, а функции КС сводятся к предоставлению большой дисковой памяти. Такой подход нельзя считать эффективным, так как для обеспечения приемлемой скорости процесса обработки информации КК должен обладать высоким быстродействием и иметь большую емкость оперативной памяти., Кроме того, пересылка копий файлов БД и команд управления блокировками по линиям связи существенно увеличивает нагрузку на подсистему передачи данных, что снижает общую производительность сети. Примерами сетевых СУБД являются: FoxPro 2.5 для Windows, dBase IY, Paradox. 3.5 для DOS. Информационные системы типа клиент-сервер отличаются от систем типа файл-сервер прежде всего тем, что программы СУБД функционально разделены на две части, называемые сервером и клиентом. Между клиентской и серверной частями системы возможны различные варианты распределения функций (подраздел 4.2). Клиент, или фронтальная программа, отвечает за интерфейс с пользователем, для чего преобразует его запросы в команды запросов к серверной части, а при получении результатов выполняет обратное преобразование и отображение информации для пользователя. В роли клиента выступает пользовательская (разрабатываемая для решения конкретной прикладной задачи программа) или готовая программа, имеющая интерфейс с серверной программой. В качестве готовых клиентских программ могут использоваться текстовые процессоры, табличные процессоры и даже СУБД (например, Access, FoxPro и Paradox). Сервер является основной программой, выполняющей функции управления и защиты данных в базе. В случаях, когда вызов функций сервера выполняется на языке SQL, а именно так часто и происходит, его называют SQL-сервером. В качестве сервера может использоваться ядро профессиональной реляционной СУБД (например, Informix 7.x и Sybase System 10) или некоторый SQL-сервер (например, Novell NetWare SQL и Microsoft SQL Server). Структуру информационных систем типа клиент-сервер упрощенно можно представить как показано на рис. 4.11. Основная часть обработки информации по формированию запросов, составлению отчетов, представлению данных в удобной для пользователя виде и т. д. выполняется на КК. Полные копии файлов БД из КС на КК и обратно (как в случае систем на базе сетевых СУБД) не пересылаются, поскольку для организации полноценного взаимодействия, как правило, достаточно иметь на КК необходимые в данный момент времени записи БД. Все это существенно снижает траффик в сети, ослабляет требования по ресурсам к КК, позволяет создавать более эффективные и надежные информационные системы. В последнее время на компьютере-сервере, кроме собственно данных, хранят Программы обработки данных и запросы. Это обеспечивает увеличение скорости обработки данных (программа обработки либо запрос находится "рядом" с данными), а также эффективность хранения и администрирования программ и запросов общего пользования в одном месте (на компьютере-сервере). Хранимые на компьютере-сервере программы (процедуры) обработки данных называют хранимыми процедурами. Разновидностью хранимой процедуры является так называемый триггер. Триггер (триггерная процедура) автоматически вызывается при возникновении определенных событий в БД. В качестве событий могут быть следующие: операции вставки, обновления и удаления отдельных записей, колонок и полей записей и другие. Примером триггера является программа, запускающая процесс посылки сообщения по электронной почте при достижении размера БД (количества записей) предельного значения. В БД сервера некоторых систем можно хранить и сами запросы, называемые хранимыми командами. Совокупность хранимых команд - это поименованная совокупность команд, получаемых в результате компиляции SQL-запроса. Хранимые команды выполняются значительно быстрее, чем соответствующий SQL-запрос Основная причина ускорения состоит в том, что при выполнении хранимых команд не требуется синтаксический разбор запросов. Дополнительное ускорение выполнения запросов может быть получено в тех случаях, когда сервер БД не просто сохраняет коды команд запросов, а производит оптимизацию сохраняемого кода. С хранимыми процедурами и командами связано понятие курсора, отличающееся от привычного понятия курсора как указателя текущей позиции на экране монитора. В разных СУБД - это близкие, но несколько отличающиеся понятия. Наиболее широко это понятие трактуется в СУБД SQLBase. Здесь курсор может означать следующее: идентификатор сеанса связи пользователя с СУБД; идентификатор хранимых команд и процедур; идентификатор результирующего множества; указатель текущей строки в результирующем множестве, обрабатываемом клиентским приложением. Программы сервера (основные, хранимые процедуры и триггеры) могут быть выполнены как обычные программы (Windows 95/98), либо как специально загружаемые модули сетевой ОС (NLM-модули в сети Novell). Программы клиента в общем случае хранятся на КС или на КК, или в обоих местах. В настоящее время среди программных продуктов существует огромное количество универсальных (в смысле пригодности работы с различными серверами БД) средств разработки систем типа клиент-сервер, к числу которых относятся: Delphi (Borland), Power Builder (Powersoft), ERwin (LogicWorks), Visual Basic (Microsoft), CA-Visual Objects (Computer Associates), SQL Windows (Gupta) и другие. Кроме того, существуют средства разработки в рамках определенных СУБД (например, для Oracle 7 - Designer/2000). Все подобные средства, как правило, относятся к CASE-системам (раздел 7). При построении информационных систем типа клиент-сервер возникает проблема доступа со стороны СУБД или приложений, разработанных в одной среде, к данным, порожденным другой СУБД. В среде Windows эта проблема решается с помощью стандартного интерфейса ODBC (Open Database Connectivity - совместимость . .открытых баз данных) фирмы Microsoft. Основное его назначение заключается в обеспечении унифицированного доступа к локальным и удаленным базам данных различных производителей. Схема доступа приложений к базам данных с помощью ODBC показана на рис.4.12. Доступ приложения к данным происходит путем вызова на языке SQL стандартных функций интерфейса ODBC. На компьютере-клиенте при этом должна функционировать операционная система MS Windows с интерфейсом ODBC.
Рис. 4.12. Схема доступа к БД с помощью ODBC
Взаимодействие приложения с данными производится с помощью менеджера (диспетчера) драйверов, который подключает необходимый драйвер в соответствии с форматом данных СУБД. Драйвер СУБД, используя сетевые средства, как правило, коммуникационные модули конкретной СУБД, передает SQL-операторы серверу СУБД. Результаты выполнения запросов на сервере передаются обратно в приложение. Рассмотренные схемы функционирования СУБД и внешних приложений касаются наиболее типичных вариантов их построения.
НАВЕРХ
4.5. Информационные системы в Internet и Intranet
Обработка информации в среде Internet существенно отличается от обработки информации в локальной сети и, тем более, на отдельном компьютере. Перечислим наиболее важные из них: 1. Большая протяженность коммуникационных линий, что сказывается на временных характеристиках обмена. Кроме того, большая удаленность лишает смысла загрузку программ с одного компьютера на другой и не позволяет выполнять пересылку больших объемов данных в реальном масштабе времени, как в сетевых СУБД локальных сетей. 2. Взаимодействие распределенных элементов ИС происходит с помощью обмена пакетами или сообщениями. Отдельные программные компоненты И С могут быть одного или различных производителей. В последнем случае особую роль приобретает решение проблемы поддержки стандартов на сетевые протоколы и на язык SQL. 3. Сеть Internet отличает от остальных глобальных сетей то, что по масштабам она больше всех других сетей (объединяет другие сети) и принципы ее организации оказывают существенное влияние на использование в сети баз данных. Перед рассмотрением моделей и механизмов использования БД дадим краткую характеристику Internet.
Характеристика Internet
Основными видами услуг (сервиса), предоставляемых пользователям при подключении к Internet, являются: электронная почта (E-mail); телеконференции (UseNet); система эмуляции удаленных терминалов (TelNet); поиск и передача двоичных файлов (FTP); поиск и передача текстовых файлов с помощью системы меню (Gopher); поиск и передача документов с помощью гипертекстовых ссылок (WWW или "Всемирная паутина"). Создание и развитие этих способов связано с историей Internet. Каждый из них характеризуется своими возможностями и различием в организации протоколов обмена информацией. Под протоколом, в общем случае, понимается набор инструкций, регламентирующих работу взаимосвязанных систем или объектов в сети. Электронная почта (E-mail) - наиболее простой и доступный способ доступа в сети Internet. Позволяет выполнять пересылку любых типов файлов (включая тексты, изображения, звуковые файлы) по адресам электронной почты в любую точку планеты за короткий промежуток времени в любое время суток. Для передачи сообщения необходимо знать электронный адрес получателя. Работа электронной почты основана на последовательной передаче информации по сети от одного почтового сервера к другому, пока сообщение не достигнет адресата. К достоинствам электронной почты относятся высокая оперативность и низкая стоимость. Недостаток электронной почты состоит в ограниченности объема пересылаемых файлов. Система телеконференций UseNet разработана как система обмена текстовой информацией. Она позволяет всем пользователям Internet участвовать в групповых дискуссиях, называемых телеконференциями, в которых обсуждаются всевозможные проблемы. Сейчас в мире насчитывается более 10 тысяч телеконференций. Информация, посылаемая в телеконференции, становится доступной любому пользователю Internet, обратившемуся в данную телеконференцию. В настоящее время телеконференции позволяют передавать файлы любых типов. Для работы с телеконференциями наиболее часто используются средства программ просмотра и редактирования Web-документов. TelNet - это протокол, позволяющий одному компьютеру использовать ресурсы другого (удаленного) компьютера. Другими словами - это протокол удаленного терминального доступа в сети. FTP (File Transfer Protocol) - это протокол, позволяющий передавать файлы произвольного формата между двумя компьютерами сети. Программное обеспечение FTP разработано по архитектуре "клиент-сервер" и разделено на две части: серверную (FTP-сервер) и клиентскую. FTP-клиент, в общем случае, позволяет пользователям просматривать файловую систему FTP-сервера и производить с ней обмен файлами (выгружать файлы своего компьютера, загружать, переименовывать и удалять файлы удаленного компьютера). Достоинством данного протокола является возможность передачи файлов любого типа, в том числе исполняемых программ. К недостатку протокола FTP следует отнести необходимость априорного знания местоположения отыскиваемой информации (FTP-адреса). Протокол Gopher реализующее его программное обеспечение предоставляют пользователям возможность работы с информационными ресурсами, не зная заранее их местонахождение. Для начала работы по этому протоколу достаточно знать адрес одного Gopher-сервера. В дальнейшем работа заключается в выборе команд, представленных в виде простых и понятных меню. При этом пункты меню одного сервера могут содержать ссылки на меню других серверов, что облегчает поиск требуемой информации в сети Internet. Во время работы с системой Gopher программа-клиент не поддерживает постоянного соединения с Gopher-сервером, что позволяет экономить сетевые ресурсы. WWW (World Wide Web - всемирная паутина) представляет собой самое популярное и современное средство организации сетевых ресурсов. Она строится на основе гипертекстового представления информации. Гипертекстовый документ {гипертекст) представляет собой текст, содержащий ссылки на другие фрагменты текстов произвольных документов, в том числе и этого документа. Гипертекстовый документ подготавливается на стандартизованном языке HTML (HyperText Markup Language - язык разметки гипертекста). Он состоит из страниц (web-страниц), доступ к которым основан на протоколе передачи гипертекста (HyperText Transfer Prococol, HTTP). HTML-документ представляет собой ASCII-файл, доступный для просмотра и редактирования в любом редакторе текстов. В отличие от обычного текстового файла, в нем присутствуют специальные команды - тэги, которые указывают правила форматирования документа. С помощью тэгов описываются различные элементы документа: заголовки, абзацы (параграфы), списки, ссылки, формы и т. д. Простейшим примером гипертекста является книга, оглавление которой содержит ссылки (внутренние) в виде номеров страниц на разделы, подразделы, пункты книги, кроме того, в книге имеются внешние ссылки на другие используемые источники информации. Фрагмент документа может включать в себя информацию в виде обычного текста, графического изображения, звука и движущегося изображения (анимации). Гипертекст с нетекстовыми документами часто называют гипермедиа. Важнейшим свойством гипертекста является наличие в нем ссылок на документы, размещаемые на территориально удаленных компьютерах. Документы могут создаваться и редактироваться различными людьми. Вся совокупность взаимосвязанных документов образует гигантскую "паутину". Эта модель подобна модели окружающего нас бесконечного информационного пространства, когда нет строгой иерархии связей, а есть множество связей без начала и конца. Работа сети Internet основана на использовании протокола TCP/IP (Transmission Control Protocol/Internet Protocol - Протокол управления передачей данных/Протокол Internet), который используется для передачи данных в глобальной сети и во многих локальных сетях. TCP/IP в основном реализует функции транспортного и сетевого уровней модели OSI (подраздел 4.1). Он представляет собой семейство коммуникационных протоколов, которые по назначению можно разделить на следующие группы: транспортные протоколы, служащие для управления передачей данных между двумя компьютерами; протоколы маршрутизации, обрабатывающие адресацию данных и определяющие кратчайшие доступные пути к адресату; протоколы поддержки сетевого адреса, предназначенные для идентификации компьютера по его уникальному номеру или имени; прикладные протоколы, обеспечивающие получение доступа к всевозможным сетевым услугам; шлюзовые протоколы, помогающие передавать по сети сообщения о маршрутизации и информацию о состоянии сети, а также обрабатывать данные для локальных сетей; другие протоколы, не относящиеся к указанным категориям, но обеспечивающие клиенту удобство работы в сети. Доступ пользователей к ресурсам Internet обычно производится с помощью программ-навигаторов, или броузеров (от англ. browser). В настоящее время к числу наиболее популярных программ этого класса относятся следующие: Netscape Navigator/ Communicator (Netscape) и MS Explorer (Microsoft). Хотя эти программы основаны на использовании протокола HTTP, они предоставляют простой доступ к другим сервисам Internet: электронной почте, новостям и т. д. Броузер, обеспечивая доступ пользователя к ресурсам сети, по существу является программой-клиентом (или Web-клиентом). Программой, предоставляющей информационные ресурсы, является Web-сервер. Именно он осуществляет основную работу по сбору и получению информации из разных источников, после чего в стандартном виде предоставляет ее Web-клиенту. Рассмотрим организацию выбора информации для пользователя, если она находится в базах данных.
Базы данных в Internet и Intranet
Технология intranet по существу представляет собой технологию Internet, перенесенную в среду корпоративных ИС. Архитектура информационных систем в Internet и intranet является результатом эволюционного перехода от первых многопользовательских централизованных вычислительных систем (мэйнфреймов) через системы типа клиент-сервер к распределенным системам с централизованной обработкой и подготовкой информации к непосредственному потреблению. Рассмотрим кратко указанные этапы эволюции. 1. В мэйнфреймах (рис. 4.13) вычислительные ресурсы, хранимые данные и программы обработки информации сконцентрированы в одной ЭВМ. Основным средством доступа был алфавитно-цифровой терминал (дисплей), управляемый ЭВМ. Вся обработка информации и подготовка ее к выдаче выполнялись на центральной ЭВМ. С терминалов, как правило, в машину передавались коды нажатия клавиш или содержимое буфера экрана, а обратно на терминал - пересылались отображаемые экраны с соответствующими кодами управления отображением. Достоинством системы является простота администрирования, защиты информации и модификации системы, к недостаткам можно отнести высокую загрузку процессоров и линий связи (как следствие - невысокую реакцию системы при большом количестве пользователей), низкую надежность (выход из строя ЭВМ приводит к полному отказу всей системы), сложность масштабирования системы и некоторые другие. 2. Исторически следующим решением в области информационных систем была архитектура клиент-сервер (рис. 4.14). В этих системах место терминала заняла ПЭВМ, а мэйнфрейма - компьютер-сервер. Ранее мы рассматривали спектр моделей подобных систем с различным распределением функций между компонентами. Если не брать во внимание модель "распределенного представления" (по сути повторяет модель централизованной многопользовательской системы), то можно заключить, что системы типа клиент-сервер имеют следующие достоинства: высокая живучесть и надежность легкость масштабирования качественный пользовательский интерфейс возможность одновременной работы с несколькими приложениями высокие характеристики оперативности обработки информации. Основным недостатком клиент-серверных систем является то, что они ориентированы на данные, а не на информацию. Это требует от пользователя знания не только предметной области, а и специфики используемой прикладной программы. Существенным недостатком можно считать также сложность переноса таких систем на другие компьютерные платформы и интеграцию с другими пакетами из-за "закрытое™" используемых протоколов взаимодействия компонентов систем. Еще один недостаток заключается в сложности администрирования системы и ее уязвимости при непредсказуемых или злонамеренных действиях пользователя или компьютерных вирусов. 3. Корпоративные системы Intranet, в отличие от систем клиент-сервер, ориентированы не на данные, а на информацию в ее окончательном и пригодном для использования неквалифицированным пользователем виде (рис. 4.15). Новые системы объединяют в себе преимущества централизованных многопользовательских систем и систем типа клиент-сервер. Им присущи следующие черты: на сервере порождается информация, пригодная для использования, а не данные (например, в случае СУБД - записи БД); при обмене между клиентской и серверной частями используется протокол открытого стандарта, а не какой-то конкретной фирмы; прикладная система находится на сервере, и поэтому для работы пользователя на компьютере-клиенте достаточно иметь программу-навигатор (могут быть и другие решения, когда часть обработки производится на компьютере-клиенте). В случае, когда источником информации в Internet и intranet являются БД, имеет место взаимодействие компонентов WWW и традиционных СУБД. Различают два следующих варианта функционирования программного обеспечения WWW по доступу к БД: на стороне Web-сервера (рис. 4.16а) и на стороне Web-клиента (рис. 4.16б). В модели доступа к БД на стороне сервера обращение к серверу БД обычно производится путем вызова программами Web-сервера внешних по отношению к ним программ в соответствии с соглашениями одного из интерфейсов: CGI (Common Gateway Interface - общий шлюзовый интерфейс), FastCGI или API (Application Program Interface - интерфейс прикладного программирования). Внешние программы взаимодействуют с сервером БД на языке SQL, непосредственно обращаясь к конкретному серверу или используя драйвер ODBC (см. подраздел 9.3). Внешние программы пишутся на обычных языках программирования типа Си, Си++ и Паскаль или специализированных языках типа Peri или РНР. Программы, разработанные в соответствии с интерфейсом CGI, называются CGI-сценариями или CGI-скриптами. Для поддержки этого механизма на стороне клиента в языке HTML имеется средство включения в документ форм (тэг <FORM> языка HTML) представления запросов к БД. Процедура доступа к БД с использованием интерфейса CGI включает в себя следующие этапы: 1. Запрос Web-клиентом у Web-сервера страницы, содержащей форму обращения к БД, если при просмотре документа пользователем Web-клиент встречает ссылку на такую страницу. 2. Заполнение Web-клиентом содержащейся на полученной странице формы запроса к БД и отправка ее Web-серверу. Правильность заполнения формы можно контролировать с помощью несложной программы, непосредственно находящейся в области HTML-страницы, в которой описана форма (обычно для этого используют языки VBScript HnnJavaScript). 3. Web-сервер, получив эту форму, запускает соответствующую внешнюю CGI-программу, передавая ей параметры (адрес и имя этой программы указывается в атрибуте ACTION тэга <FORM>). 4. Внешняя программа преобразует описанный в форме запрос к БД в соответствующий текст запроса на языке SQL, с которым обращается к серверу БД. 5. После получения результатов запроса внешняя программа формирует требуемую HTML-страницу, передает ее Web-серверу и завершает свое выполнение. 6. Web-сервер передает сформированную HTML-страницу Web-клиенту. Основными достоинствами применения спецификации CGI для организации доступа к данным базы являются следующие: языковая независимость - сценарий может быть написан практически на любом языке программирования, содержащем средства обработки строк; процессная изолированность - сценарий выполняется на сервере как отдельный процесс, не имеющий доступа к защищенной системной информации сервера; широкая распространенность, так как CGI-стандарт применим на каждом Web-сервере; архитектурная независимость - программы, разработанные в соответствии с CGI-стандартом, не зависят от архитектуры сервера. К главным недостаткам применения спецификации CGI относятся следующие: необходимость всякий раз устанавливать и разрывать соединение с базой данных, поскольку отсутствуют средства поддержания постоянного соединения Web-сервера и СУБД; ограничения на обработку исходной информации для запросов и результатов выполнения запросов; трудоемкость выполнения программ, связанная с запуском программы как отдельного процесса. Это замедляет обработку запросов к данным и снижает эффективность работы сервера. Для устранения недостатков CGI-спецификации разработана спецификация API. Программы, разработанные по этой спецификации, быстрее и эффективнее выполняются, поскольку организованы в виде динамических библиотек. Наиболее известными являются два интерфейса этого вида: NSAPI (компания Netscape) и ISAPI (компания Microsoft). Достоинством этой технологии является ускорение выполнения программ, так как программа выполняется в рамках основного серверного процесса. Сами программы имеют большую функциональность, чем CGI-сценарии, например, появилась возможность контролировать доступ к файлам сервера. К недостаткам спецификации API относятся следующие: языковая зависимость - программа может быть написана только на языке, поддерживаемом данным API. Чаще всего это языки С и C++ (язык Peri, широко применяемый при написании CGI-скриптов, не применяется); слабая защита сервера от ошибок прикладных программ и от возможности несанкционированного доступа к системным ресурсам, поскольку API-программа выполняется в адресном пространстве основного процесса сервера; программы, как правило, не переносимы на другие программно-аппаратные платформы, поскольку привязаны к интерфейсу и архитектуре сервера. Интерфейс FastCGI сочетает преимущества предыдущих технологий и более близок к интерфейсу CGI. Приложения, написанные в соответствии с ним, запускаются как отдельные изолированные процессы, но являются постоянно активными и не завершаются после обращения к данным как CGI-сценарии. При доступе к БД на стороне клиента основным средством реализации механизмов взаимодействия Web-клиента и сервера БД является язык Java. Кроме того, может использоваться JavaScript, разработанный для расширения возможностей декларативного языка HTML (нет операторов присваивания, сравнения, математических функций и пр.) на основе добавления процедурных средств. Программы на языке JavaScript выполняются на компьютере Web-броузером в режиме интерпретации. Если в HTML-документе, требуется получить данные из БД, то поступают следующим образом. 1. На языке Java пишутся дополнительные программы, называемые апплетами (Java-applets), которые затем компилируются. В результате получаются мобильные (машинно-независимые) программы. Последние могут выполняться в режиме интерпретации или служить исходной информацией для генерации программ, готовых к выполнению на разных аппаратно-программных платформах. 2. В тексте HTML-документа в нужных местах ставятся ссылки на соответствующие апплеты. Сами программы хранятся на сервере. 3. В процессе работы с гипертекстом при обнаружении в тексте ссылки на апплет происходит автоматическая пересылка Java-программы с сервера в среду выполнения броузера и загрузка на выполнение. Последняя в диалоге с пользователем уточняет параметры запроса к БД (средства поддержки графического пользовательского интерфейса в языке Java имеются). 4. Получив управление, Java-апплет осуществляет взаимодействие с сервером БД, в результате чего полученная из базы информация представляется пользователю. Для обращений к серверам БД разработан стандарт JDBC (Java DataBase Connectivity - совместимость баз данных для Java), основанный на концепции ODBC. Стандарт JDBC разработан фирмами Sun/JavaSoft и обеспечивает универсальный доступ к различным базам данных на языке Java. Из двух рассмотренных схем однозначного предпочтения тому или иному варианту отдать нельзя. Все зависит от целей и условий разработки клиент-серверных программ (наиболее существенной оказывается зависимость от ОС, а также от вида Web-сервера). Достоинством модели доступа на стороне сервер является сравнительная простота программ-навигаторов (Web-клиентов) и удобство администрирования системы, так как основная часть программного обеспечения находится на машине Web-сервера. Очевидным недостатком системы является возможное ухудшение характеристик оперативности получения информации при большой нагрузке на Web-сервер и нехватке его мощности. Во второй модели клиентская часть системы оказывается сложнее, чем в первой. Это усложняет навигатор, но в to же время разгружает Web-сервер. В сравнительно недавно выпущенных программных продуктах фирмы Microsoft поддерживаются обе схемы. Па стороне клиента (в среде Internet Explorer) существует возможность использовать динамический HTML, который реализуется на языке VBScript. Доступ к данным на стороне сервера осуществляется с помощью так называемых ASP-страниц (Active Server Pages - активные серверные страницы). ASP-страницы - это сценарии на языке VBScript, хранящиеся и выполняемые на Web-сервере (Internet Information Server).
5. Проектирование баз данных
5.1. Проблемы проектирования
Избыточное дублирование данных и аномалии
Следует различать простое (неизбыточное) и избыточное дублирование данных. Наличие первого из них допускается в базах данных, а избыточное дублирование данных может приводить к проблемам при обработке данных. Приведем примеры обоих вариантов дублирования. Пример неизбыточного дублирования данных представляет приведенное на рис. 5.1 отношение С_Т с атрибутами Сотрудник и Телефон. Для сотрудников, находящихся в одном помещении, номера телефонов совпадают. Номер телефона 4328 встречается несколько раз, хотя для каждого служащего номер телефона уникален. Поэтому ни один из номеров не является избыточным. Действительно, при удалении одного из номеров телефонов будет утеряна информация о том, по какому номеру можно дозвониться до одного из служащих.
С_Т
Сотрудник
Телефон
Иванов
Петров
Сидоров
Егоров
Рис. 5.1. Неизбыточное дублирование
Пример избыточного дублирования (избыточности) представляет приведенное на рис. 5.2а отношение С_Т_Н, которое, в отличие от отношения С_Т, дополнено атрибутом Н_комн (номер комнаты сотрудника). Естественно предположить, что все служащие в одной комнате имеют один и тот же телефон. Следовательно, в рассматриваемом отношении имеется избыточное дублирование данных. Так, в связи с тем, что Сидоров и Егоров находятся в той же комнате, что и Петров, их номера можно узнать из кортежа со сведениями о Петрове.
С_Т_Н а)
Сотрудник
Телефон
Н_комн
Иванов
Петров
Сидоров
Егоров
С_Т_Н б)
Сотрудник
Телефон
Н_комн
Иванов
Петров
Сидоров
---
Егоров
---
Рис. 5.2. Избыточное дублирование
На рис. 5.2б приведен пример неудачного отношения С_Т_Н, в котором вместо телефонов Сидорова и Егорова поставлены прочерки (неопределенные значения). Неудачность подобного способа исключения избыточности заключается в следующем. Во-первых, при программировании придется потратить дополнительные усилия на создание механизма поиска информации для прочерков таблицы. Во-вторых, память все равно выделяется под атрибуты с прочерками, хотя дублирование данных и исключено. В-третьих, что особенно важно, при исключении из коллектива Петрова кортеж со сведениями о нем будет исключен из отношения, а значит уничтожена информация о телефоне 111-й комнаты, что недопустимо. Возможный способ выхода из данной ситуации приведен на рис. 5.3. Здесь показаны два отношения С_Н и Н_Т, полученные путем декомпозиции исходного отношения С_Т_Н. Первое из них содержит информацию о номерах комнат, в которых располагаются сотрудники, а второе - информацию о номерах телефонов в каждой из комнат. Теперь, если Петрова и уволят из учреждения и, как следствие этого, удалят всякую информацию о нем из баз данных учреждения, это не приведет к утере информации о номере телефона в 111-й комнате.
Телефон
Н_комн
С_Н
Сотрудник
Н_комн
Иванов
Петров
Сидоров
Егоров
Рис. 5.3. Исключение избыточного дублирования
Процедура декомпозиции отношения С_Т_Н на два отношения С_Н и Н_Т является основной процедурой нормализации отношений. Избыточное дублирование данных создает проблемы при обработке кортежей отношения, названные Э. Коддом "аномалиями обновления отношения". Он показал, что для некоторых отношений проблемы возникают при попытке удаления, добавления или редактирования их кортежей. Аномалиями будем называть такую ситуацию в таблицах БД, которая приводит к противоречиям в БД, либо существенно усложняет обработку данных. Выделяют три основные вида аномалий: аномалии модификации (или редактирования), аномалии удаления и аномалии добавления. Аномалии модификации проявляются в том, что изменение значения одного данного может повлечь за собой просмотр всей таблицы и соответствующее изменение некоторых других записей таблицы. Так, например, изменение номера телефона в комнате 111 (рис. 5.2а), что представляет собой один единственный факт, потребует просмотра всей таблицы С_Т_Н и изменения поля Н_комн согласно текущему содержимому таблицы в записях, относящихся к Петрову, Сидорову и Егорову. Аномалии удаления состоят в том, что при удалении какого-либо данного из таблицы может пропасть и другая информация, которая не связана напрямую с удаляемым данным. В той же таблице С_Т_Н удаление записи о сотруднике Иванове (например, по причине увольнения или ухода на заслуженный отдых) приводит к исчезновению информации о номере телефона, установленного в 109-й комнате. Аномалии добавления возникают в случаях, когда информацию в таблицу нельзя поместить до тех пор, пока она неполная, либо вставка новой записи требует дополнительного просмотра таблицы. Примером может служить операция добавления нового сотрудника все в ту же таблицу С_Т_Н. Очевидно, будет противоестественным хранение сведений в этой таблице только о комнате и номере телефона в ней, пока никто из сотрудников не помещен в нее. Более того, если в таблице С_Т_Н поле Служащий является ключевым, то хранение в ней неполных записей с отсутствующей фамилией служащего просто недопустимо из-за неопределенности значения ключевого поля. Вторым примером возникновения аномалии добавления может быть ситуация включения в таблицу нового сотрудника. При добавлении таких записей для исключения противоречий желательно проверить номер телефона и соответствующий номер комнаты хотя бы с одним из сотрудников, сидящих с новым сотрудником в той же комнате. Если же окажется, что у нескольких сотрудников, сидящих в одной комнате, имеются разные телефоны, то вообще не ясно, что делать (то ли в комнате несколько телефонов, то ли какой-то из номеров ошибочный).
Формирование исходного отношения
Проектирование БД начинается с определения всех объектов, сведения о которых будут включены в базу, и определения их атрибутов. Затем атрибуты сводятся в одну таблицу - исходное отношение. Пример. Формирование исходного отношения. Предположим, что для учебной части факультета создается БД о преподавателях. На первом этапе проектирования БД в результате общения с заказчиком (заведующим учебной частью) должны быть определены содержащиеся в базе сведения о том, как она должна использоваться и какую информацию заказчик хочет получать в процессе ее эксплуатации. В результате устанавливаются атрибуты, которые должны содержаться в отношениях БД, и связи между ними. Перечислим имена выделенных атрибутов и их краткие характеристики: ФИО - фамилия и инициалы преподавателя. Исключаем возможность совпадения фамилии и инициалов у преподавателей. Должн - должность, занимаемая преподавателем. Оклад - оклад преподавателя. Стаж - преподавательский стаж. Д_Стаж - надбавка за стаж. Каф - номер кафедры, на которой числится преподаватель. Предм - название предмета (дисциплины), читаемого преподавателем. Группа - номер группы, в которой преподаватель проводит занятия. ВидЗан - вид занятий, проводимых преподавателем в учебной группе. Одно из требований к отношениям заключается в том, чтобы все атрибуты отношения имели атомарные (простые) значения. В исходном отношении каждый атрибут кортежа также должен быть простым. Пример исходного отношения ПРЕПОДАВАТЕЛЬ приведен на рис. 5.4.
ПРЕПОДАВАТЕЛЬ
ФИО
Должн
Оклад
Стаж
ДСтаж
Каф
Предм
Группа
ВидЗан
Иванов И.М.
преп
СУБД
Практ
Иванов И.М.
преп
ПЛ/1
Практ
Петров М.И.
ст. преп
СУБД
Лекция
Петров М.И.
ст. преп
Паскаль
Практ
Сидоров Н.Г.
преп
ПЛ/1
Лекция
Сидоров Н.Г.
преп
Паскаль
Лекция
Егоров В.В.
преп
ПЭВМ
Лекция
Рис. 5.4. Исходное отношение ПРЕПОДАВАТЕЛЬ
Указанное отношение имеет следующую схему ПРЕПОДАВАТЕЛЬ(ФИО, Должн, Оклад, Стаж, Д_Стаж, Каф, Предм, Группа, ВидЗан). Исходное отношение ПРЕПОДАВАТЕЛЬ содержит избыточное дублирование данных, которое и является причиной аномалий редактирования. Различают избыточность явную и неявную. Явная избыточность заключается в том, что в отношении ПРЕПОДАВАТЕЛЬ строки с данными о преподавателях, проводящих занятия в нескольких группах, повторяются соответствующее число раз. Например, в отношении ПРЕПОДАВАТЕЛЬ все данные по Иванову повторяются дважды. Поэтому, если Иванов И.М. станет старшим преподавателем, то этот факт должен быть отражен в обеих строках. В противном случае будет иметь место противоречие в данных, что является примером аномалии редактирования, обусловленной явной избыточностью данных в отношении. Неявная избыточность в отношении ПРЕПОДАВАТЕЛЬ проявляется в одинаковых окладах у всех преподавателей и в одинаковых добавках к окладу за одинаковый стаж. Поэтому, если при изменении окладов за должность с 500 на 510 это значение изменят у всех преподавателей, кроме, например, Сидорова, то база станет противоречивой. Это пример аномалии редактирования для варианта с неявной избыточностью. Средством исключения избыточности в отношениях и, как следствие, аномалий является нормализация отношений, рассмотрим ее более подробно.
НАВЕРХ
5.2. Метод нормальных форм
Проектирование БД является одним из этапов жизненного цикла информационной системы. Основной задачей, решаемой в процессе проектирования БД, является задача нормализации ее отношений. Рассматриваемый ниже метод нормальных форм является классическим методом проектирования реляционных БД. Этот метод основан на фундаментальном в теории реляционных баз данных понятии зависимости между атрибутами отношений.
Зависимости между атрибутами
Рассмотрим основные виды зависимостей между атрибутами отношений: функциональные, транзитивные и многозначные. Понятие функциональной зависимости является базовым, так как на его основе формулируются определения всех остальных видов зависимостей. Атрибут В функционально зависит от атрибута А, если каждому значению А соответствует в точности одно значение В. Математически функциональная зависимость В от А обозначается записью А->В. Это означает, что во всех кортежах с одинаковым значением атрибута А атрибут В будет иметь также одно и то же значение. Отметим, что А и В могут быть составными - состоять из двух и более атрибутов. В отношении на рис. 5.4 можно выделить функциональные зависимости между атрибутами ФИО->Каф, ФИО->Должн, Должн->Оклад и другие. Наличие функциональной зависимости в отношении определяется природой вещей, информация о которых представлена кортежами отношения. В отношении на рис. 5.4 ключ является составным и состоит из атрибутов ФИО, Предмет, Группа. Функциональная взаимозависимость. Если существует функциональная зависимость вида А->В и В->А, то между А и В имеется взаимно однозначное соответствие, или функциональная взаимозависимость. Наличие функциональной взаимозависимости между атрибутами А и В обозначим как А<->В или В<->А. Пример. Пусть имеется некоторое отношение, включающее два атрибута, функционально зависящие друг от друга. Это серия и номер паспорта (N) и фамилия, имя и отчество владельца (ФИО). Наличие функциональной зависимости поля ФИО от N означает не только тот факт, что значение поля N однозначно определяет значение поля ФИО, но и то, что одному и тому же значению поля N соответствует только единственное значение поля ФИО. Понятно, что в данном случае действует и обратная ФЗ: каждому значению поля ФИО соответствует только одно значение поля N. В данном примере предполагается, что ситуация наличия полного совпадения фамилий, имен и отчеств двух людей исключена. Если отношение находится в 1НФ, то все неключевые атрибуты функционально зависят от ключа с различной степенью зависимости. Частичной зависимостью (частичной функциональной зависимостью) называется зависимость неключевого атрибута от части составного ключа. В рассматриваемом отношении атрибут Должн находится в функциональной зависимости от атрибута ФИО, являющегося частью ключа. Тем самым атрибут Должн находится в частичной зависимости от ключа отношения. Альтернативным вариантом является полная функциональная зависимость неключевого атрибута от всего составного ключа. В нашем примере атрибут ВидЗан находится в полной функциональной зависимости от составного ключа. Атрибут С зависит от атрибута А транзитивно (существует транзитивная зависимость), если для атрибутов А, В, С выполняются условия А->В и В->С, но обратная зависимость отсутствует. В отношении на рис. 5.4 транзитивной зависимостью связаны атрибуты: ФИО->Должн->Оклад Между атрибутами может иметь место многозначная зависимость. В отношении R атрибут В многозначно зависит от атрибута А, если каждому значению А соответствует множество значений В, не связанных с другими атрибутами из R. Многозначные зависимости могут быть "один ко многим" (1:М), "многие к одному" (М: 1) или "многие ко многим" (М:М), обозначаемые соответственно: А=>В, А<=В и А<=>В. Например, пусть преподаватель ведет несколько предметов, а каждый предмет может вестись несколькими преподавателями, тогда имеет место зависимость ФИО<=>Предмет. Так, из таблицы 7.2, приведенной на рис. 5.4., видно, что преподаватель Иванов И.М. ведет занятия по двум предметам, а дисциплина СУБД - читается двумя преподавателями: Ивановым И.М. и Петровым М.И. Замечание. В общем случае между двумя атрибутами одного отношения могут существовать зависимости: 1:1,1:М,М:1 и М:М. Поскольку зависимость между атрибутами является причиной аномалий, стараются расчленить отношения с зависимостями атрибутов на несколько отношений. В результате образуется совокупность связанных отношений (таблиц) со связями вида 1:1,1:М, М:1 и М:М (подраздел 3.3). Связи между таблицами отражают зависимости между атрибутами различных отношений. Взаимно независимые атрибуты. Два или более атрибута называются взаимно независимыми, если ни один из этих атрибутов не является функционально зависимым от других атрибутов. В случае двух атрибутов отсутствие зависимости атрибута А от атрибута В можно обозначить так: А-.->В. Случай, когда А-.->В и B-i->A, можно обозначить А-.=В.
Выявление зависимостей между атрибутами
Выявление зависимостей между атрибутами необходимо для выполнения проектирования БД методом нормальных форм, рассматриваемого далее. Основной способ определения наличия функциональных зависимостей - внимательный анализ семантики атрибутов. Для каждого отношения существует, но не всегда, определенное множество функциональных зависимостей между атрибутами. Причем если в некотором отношении существует одна или несколько функциональных зависимостей, можно вывести другие функциональные зависимости, существующие в этом отношении. Пример. Пусть задано отношение R со схемой R(A1, A2, A3) и числовыми значениями, приведенными в следующей таблице:
А1
A2
A3
Априори известно, что в R существуют функциональные зависимости: А1-> A2 и А2-> A3. Анализируя это отношение, можно увидеть, что в нем существуют еще зависимости: А1-> A3, А1А2-> A3, А1А2АЗ-> А1А2, А1А2-> А2АЗ и т. п. В то же время в отношении нет других функциональных зависимостей, что во введенных нами обозначениях можно отразить следующим образом: А2-,->А1, АЗ-,->А1 и т. д. Отсутствие зависимости А1 от А2 (А2-.->А1) объясняется тем, что одному и тому же значению атрибута А2 (21) соответствуют разные значения атрибута А1 (12 и 17). Другими словами, имеет место многозначность, а не функциональность. Перечислив все существующие функциональные зависимости в отношении R, получим полное множество функциональных зависимостей, которое обозначим F +. Таким образом, для последнего примера исходное множество F = (А1-> А2, А2-> A3), а полное множество F += (А1-> А2, А2-> A3, А1-> A3, А1А2-> A3, А1А2АЗ-> А1А2, А1А2->А2АЗ,...). Для построения F+ из F необходимо знать ряд правил (или аксиом) вывода одних функциональных зависимостей из других. Существует 8 основных аксиом вывода: рефлексивности пополнения транзитивности расширения продолжения псевдотранзитивности объединения декомпозиции. Перечисленные аксиомы обеспечивают получение всех ФЗ, т. е. их совокупность применительно к процедуре вывода можно считать "функционально полной". Содержание аксиом и соответствующие примеры приведены в Приложении 1. Выявим зависимости между атрибутами отношения ПРЕПОДАВАТЕЛЬ, приведенного на рис. 5.4. При этом учтем следующее условие, которое выполняется в данном отношении: один преподаватель в одной группе может проводить один вид занятий (лекции или практические занятия). В результате анализа отношения получаем зависимости между атрибутами, показанные на рис. 5.5.
Рис. 5.5. Зависимости между атрибутами
ФИО->Oклад ФИО->Должн ФИО->Стаж ФИО->Д_Стаж ФИО->Каф Стаж->Д_Стаж Должн->0клад Оклад->Должк ФИО.Предм.Группа->ВидЗан К выделению этих ФЗ для рассматриваемого примера приводят следующие соображения. Фамилия, имя и отчество у преподавателей факультета уникальны. Каждому преподавателю однозначно соответствует его стаж, т. е. имеет место функциональная зависимость ФИО->Стаж. Обратное утверждение неверно, так как одинаковый стаж может быть у разных преподавателей. Каждый преподаватель имеет определенную добавку за стаж, т. е. имеет место функциональная зависимость ФИО->Д_Стаж, но обратная функциональная зависимость отсутствует, так как одну и ту же надбавку могут иметь несколько преподавателей. Каждый преподаватель имеет определенную должность (преп., ст.преп., доцент, профессор), но одну и ту же должность могут иметь несколько преподавателей, т. е. имеет место функциональная зависимость ФИО->Должн, а обратная функциональная зависимость отсутствует. Каждый преподаватель является сотрудником одной и только одной кафедры. Поэтому функциональная зависимость ФИО->Каф имеет место. С другой стороны, на каждой кафедре много преподавателей, поэтому обратной функциональной зависимости нет. Каждому преподавателю соответствует конкретный оклад, который одинаков для всех педагогов с одинаковыми должностями, что учитывается зависимостями ФИО->Oклад и Должн->Oклад. Нет одинаковых окладов для разных должностей, поэтому имеет место функциональная зависимость Оклад->Должн. Один и тот же преподаватель в одной группе по разным предметам может проводить разные виды занятий. Определение вида занятий, которые проводит преподаватель, невозможно без указания предмета и группы, поэтому имеет место функциональная зависимость ФИО, Предм, Группа->ВидЗан. Действительно, Петров М.И. в 256 группе читает лекции и проводит пратические занятия. Но лекции он читает по СУБД, а практику проводит по Паскалю. Нами не были выделены зависимости между атрибутами ФИО, Предм и Группа, поскольку они образуют составной ключ и не учитываются в процессе нормализации исходного отношения. После того, как выделены все функциональные зависимости, следует проверить их согласованность с данными исходного отношения ПРЕПОДАВАТЕЛЬ (рис. 5.4). Например, Должн.=преп и Оклад=500 всегда соответствуют друг другу во всех кортежах, т. е. подтверждается функциональная зависимость Должн<->Oклад. Так же следует верифицировать и остальные функциональные зависимости, не забывая об ограниченности имеющихся в отношении данных.
Нормальные формы
Процесс проектирования БД с использованием метода нормальных форм является итерационным и заключается в последовательном переводе отношений из первой нормальной формы в нормальные формы более высокого порядка по определенным правилам. Каждая следующая нормальная форма ограничивает определенный тип функциональных зависимостей, устраняет соответствующие аномалии при выполнении операций над отношениями БД и сохраняет свойства предшествующих нормальных форм. Выделяют следующую последовательность нормальных форм: первая нормальная форма (1НФ); вторая нормальная форма (2НФ); третья нормальная форма (3НФ); усиленная третья нормальная форма, или нормальная форма Бойса-Кодда (БКНФ); четвертая нормальная форма (4НФ); пятая нормальная форма (5НФ). Первая нормальная форма. Отношение находится в 1НФ, если все его атрибуты являются простыми (имеют единственное значение). Исходное отношение строится таким образом, чтобы оно было в 1НФ. Перевод отношения в следующую нормальную форму осуществляется методом "декомпозиции без потерь". Такая декомпозиция должна обеспечить то, что запросы (выборка данных по условию) к исходному отношению и к отношениям, получаемым в результате декомпозиции, дадут одинаковый результат. Основной операцией метода является операция проекции. Поясним ее на примере. Предположим, что в отношении R(A,B,C,D,E,...) устранение функциональной зависимости C->D позволит перевести его в следующую нормальную форму Для решения этой задачи выполним декомпозицию отношения R на два новых отношения R1(A,B,C,E,...) и R2(C,D). Отношение R2 является проекцией отношения R на атрибуты С и D. Исходное отношение ПРЕПОДАВАТЕЛЬ, используемое для иллюстрации метода, имеет составной ключ ФИО. Предм, Группа и находится в 1 НФ, поскольку все его атрибуты простые. В этом отношении в соответствии с рис. 5.5 можно выделить частичную зависимость атрибутов Стаж, Д_Стаж, Каф, Должн, Оклад от ключа - указанные атрибуты находятся в функциональной зависимости от атрибута ФИО, являющегося частью составного ключа. Эта частичная зависимость от ключа приводит к следующему: 1. В отношении присутствует явное и неявное избыточное дублирование данных, например: повторение сведений о стаже, должности и окладе преподавателей, проводящих занятия в нескольких группах и/или по разным предметам; повторение сведений об окладах для одной и той же должности или о надбавках за одинаковый стаж. 2. Следствием избыточного дублирования данных является проблема их редактирования. Например, изменение должности у преподавателя Иванова И.М. потребует просмотра всех кортежей отношения и внесения изменений в те из них, которые содержат сведения о данном преподавателе. Часть избыточности устраняется при переводе отношения в 2НФ. Вторая нормальная форма. Отношение находится в 2НФ, если оно находится в 1НФ и каждый неключевой атрибут функционально полно зависит от первичного ключа (составного). Для устранения частичной зависимости и перевода отношения в 2НФ необходимо, используя операцию проекции, разложить его на несколько отношений следующим образом: построить проекцию без атрибутов, находящихся в частичной функциональной зависимости от первичного ключа; построить проекции на части составного первичного ключа и атрибуты, зависящие от этих частей. В результате получим два отношения R1 и R2 в 2НФ (рис. 5.6).
В отношении R1 первичный ключ является составным и состоит из атрибутов ФИО, Предм, Группа. Напомним, что данный ключ в отношении R1 получен в предположении, что каждый преподаватель в одной группе по одному предмету может либо читать лекции, либо проводить практические занятия. В отношении R2 ключ ФИО. Исследование отношений R1 и R2 показывает, что переход к 2НФ позволил исключить явную избыточность данных в таблице R2 - повторение строк со сведениями о преподавателях. В R2 по-прежнему имеет место неявное дублирование данных. Для дальнейшего совершенствования отношения необходимо преобразовать его в 3НФ. Третья нормальная форма. Определение 1. Отношение находится в 3НФ, если оно находится в 2НФ и каждый неключевой атрибут нетранзитивно зависит от первичного ключа. Существует и альтернативное определение. Определение 2. Отношение находится в 3НФ в том и только в том случае, если все неключевые атрибуты отношения взаимно независимы и полностью зависят от первичного ключа. Доказать справедливость этого утверждения несложно. Действительно, то, что неключевые атрибуты полностью зависят от первичного ключа, означает, что данное отношение находится в форме 2НФ. Взаимная независимость атрибутов (определение приведено выше) означает отсутствие всякой зависимости между атрибутами отношения, в том числе и транзитивной зависимости между ними. Таким образом, второе определение 3НФ сводится к первому определению. Если в отношении R1 транзитивные зависимости отсутствуют, то в отношении R2 они есть: ФИО->Должн->Оклад, ФИО->Оклад->Должн, ФИО->Стаж->Д_Стаж Транзитивные зависимости также порождают избыточное дублирование информации в отношении. Устраним их. Для этого используя операцию проекции на атрибуты, являющиеся причиной транзитивных зависимостей, преобразуем отношение R2, получив при этом отношения R3, R4 и R5, каждое из которых находится в 3НФ (рис. 5.7а). Графически эти отношения представлены на рис. 5.7б. Заметим, что отношение R2 можно преобразовать по-другому, а именно: в отношении R3 вместо атрибута Должн взять атрибут Оклад. На практике построение 3НФ схем отношений в большинстве случаев является достаточным и приведением к ним процесс проектирования реляционной БД заканчивается. Действительно, приведение отношений к 3НФ в нашем примере, привело к устранению избыточного дублирования. Если в отношении имеется зависимость атрибутов составного ключа от неключевых атрибутов, то необходимо перейти к усиленной 3НФ. Усиленная 3НФ или нормальная форма Бойса-Кодда (БКНФ). Отношение находится в БКНФ, если оно находится в 3НФ и в нем отсутствуют зависимости ключей (атрибутов составного ключа) от неключевых атрибутов. У нас подобной зависимости нет, поэтому процесс проектирования на этом заканчивается. Результатом проектирования является БД, состоящая из следующих таблиц: Rl, R3, R4, R5. В полученной БД имеет место необходимое дублирование данных, но отсутствует избыточное. Четвертая нормальная форма. Рассмотрим пример нового отношения ПРОЕКТЫ, схема которого выглядит следующим образом: ПРОЕКТЫ (Номер_проекта, Код_сотрудника, Задание_сотрудника). Первичным ключом отношения является вся совокупность атрибутов: Номер_проекта, Код_сотрудника и Задание_сотрудника. В отношении содержатся номера проектов, для каждого проекта - список кодов сотрудников-исполнителей, а также список заданий, предусмотренных каждым проектом. Сотрудники могут участвовать в нескольких проектах, и разные проекты могут содержать одинаковые задания. Предполагается, что каждый сотрудник, участвующий в некотором проекте, выполняет все задания по этому проекту (предположение не всегда справедливо, но желательно для нашего примера). При такой постановке вопроса единственным возможным ключом отношения является составной атрибут Номер_проекта, Код_сотрудника, Задание_сотрудника. Он, естественно, и стал первичным ключом отношения. Отсюда следует, что отношение ПРОЕКТЫ, находится в форме БКНФ. Пусть исходная информация в этом отношении выглядит следующим образом: Главный недостаток отношения ПРОЕКТЫ состоит в том, что при подключении/отстранении от проекта некоторого сотрудника приходится добавлять/исключать из отношения столько кортежей, сколько заданий имеется в проекте. Внесение или исключение в отношении одного факта о некотором сотруднике требует серии элементарных операций из-за дублирования значений в кортежах. Отсюда возникают вопросы: зачем хранить в кортежах повторяющиеся значения кодов сотрудников? Нужно ли перечислять все задания по каждому проекту, да еще для каждого сотрудника-исполнителя этого проекта? Нельзя ли информацию о привязке заданий к проектам поместить в отдельную таблицу и исключить повторения в основной таблице? Заметим, что косвенный признак аномалии, как и ранее, - дублирование информации в таблице. Выскажем предположение, что причиной аномалии является наличие некоторой зависимости между атрибутами отношения (как увидим далее - многозначной зависимости). Действительно, в отношении ПРОЕКТЫ существуют следующие две многозначные зависимости: Номер_проекта=> Код_сотрудника Номер_проекта=> 3адание_сотрудника В произвольном отношении R(A,В,С) может одновременно существовать многозначная зависимость А=>В и А=>С. Это обстоятельство обозначим как А=>В |С. Дальнейшая нормализация отношений, схожих с отношением Проекты, основывается на следующей теореме. Теорема Фейджина (Fagin R.). Отношение R(A,В,С) можно спроецировать без потерь в отношения R1(A,В) и R2(A,С) в том и только том случае, когда существует зависимость А=>В |С. Под проецированием без потерь здесь понимается такой способ декомпозиции отношения, при котором исходное отношение полностью и без избыточности восстанавливается путем естественного соединения полученных отношений (см. подраздел 3.6). Поясним проецирование без потерь на примере. Пусть имеется простейшее отношение R(A,В,С), имеющее вид: Построим проекции R1 и R2 на атрибуты А, В и А, С соответственно. Они будут выглядеть так: Результатом операции соединения бинарных отношений R1(A,В) и R2(A,С) по атрибуту А является тернарное отношение с атрибутами А, В и С, кортежи которого получаются путем связывания отношений R1 и R2 по типу 1:М на основе совпадения значений атрибута А (подраздел 3.3). Так, связывание кортежей (к,15) и {(к,1), (к,2)} дает кортежи {(к,15,1), (к,15,2)}. Нетрудно видеть, что связывание R1(A,В) и R2(A,С) в точности порождает исходное отношение R(A,В,С). В отношении R нет лишних кортежей, нет и потерь. Определение четвертой нормальной формы. Отношение R находится в четвертой нормальной форме (4НФ) в том и только в том случае, когда существует многозначная зависимость А=>В, а все остальные атрибуты R функционально зависят от А. Приведенное выше отношение ПРОЕКТЫ можно представить в виде двух отношений: ПРОЕКТЫ-СОТРУДНИКИ и ПРОЕКТЫ-ЗАДАНИЯ. Эти отношения имеют следующую структуру: ПРОЕКТЫ-СОТРУДНИКИ (Номер_проекта, Код_сотрудника). Первичный ключ отношения: Номер_проекта, Код_сотрудника. ПРОЕКТЫ-ЗАДАНИЯ (Номер_проекта, Задание_сотрудника). Первичный ключ отношения: Номер_проекта, Задание_сотрудника. Содержимое соответствующих таблиц будет теперь таким: Как легко увидеть, оба этих отношения находятся в 4НФ и свободны от замеченных недостатков. Дублирование значений атрибутов кодов сотрудников пропало. Попробуйте самостоятельно соединить эти отношения и убедиться в том, что в точности получится отношение ПРОЕКТЫ. В общем случае не всякое отношение можно восстановить к исходному. В нашем случае восстановление возможно потому, что каждый сотрудник, участвующий в некотором проекте, выполнял все задания по этому проекту (именно это укладывается в принцип 1:М соединения отношений). Сами же сотрудники участвовали в нескольких проектах, и разные проекты могли содержать одинаковые задания. Пятая нормальная форма. Результатом нормализации всех предыдущих схем отношений были два новых отношения. Иногда это сделать не удается, либо получаемые отношения заведомо имеют нежелательные свойства. В этом случае выполняют декомпозицию исходного отношения на отношения, количество которых превышает два. Рассмотрим отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ, которое имеет заголовок СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ (Код_сотрудника, Код_отдела, Номер_проекта). Первичный ключ отношения включает все атрибуты: Код_сотруд-ника, Код_отдела и Номер_проекта. Пусть в этом отношении один сотрудник может работать в нескольких отделах, причем в каждом отделе он может принимать участие в нескольких проектах. В одном отделе могут работать несколько сотрудников, но каждый проект выполняет только один сотрудник. Функциональных и многозначных зависимостей между атрибутами не существует. Это отношение является частью базы данных вымышленного научного подразделения НИИЧАВО - Научно-Исследовательского Института ЧАродейства и ВОлшебства из повести А. и Б.Стругацких "Понедельник начинается в субботу". Коды отделов здесь обозначают: АД - Администрация, ВЦ - Вычислительный центр, ЛС -Линейного счастья, РД - Родильный дом, СЖ - Смысла жизни, УП - Универсальных превращений. Исходя из структуры отношения СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ можно заключить, что оно находится в форме 4НФ. Тем не менее в отношении могут быть аномалии, связанные с возможностью повторения значений атрибутов в нескольких кортежах. Например, то что сотрудник может работать в нескольких отделах, при увольнении сотрудника требует отыскания и последующего удаления из исходной таблицы нескольких записей. Введем определение зависимости соединения. Отношение R(X, Y,... , Z) удовлетворяет зависимости соединения, которую обозначим как *(Х, Y,..., Z), в том и только в том случае, если R восстанавливается без потерь путем соединения своих проекций на X, Y,..., Z. Зависимость соединения является обобщением функциональной и многозначной зависимостей. Определение пятой нормальной формы. Отношение R находится в 5НФ (или нормальной форме проекции-соединения - PJ/NF) в том и только том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R. Образуем составные атрибуты отношения СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ: С0={ Код_сотрудиика, Код_отдела} СП=4 Код_сотрудника, Номер_проекта} ОП={ Код_отдела, Номер_проекта}. Покажем, что если отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ спроецировать на составные атрибуты СО, СП и ОП, то соединение этих проекций дает исходное отношение. Это значит, что в нашем отношении существовала зависимость соединения *(СО, СП, ОП). Проекции на составные атрибуты назовем соответственно СОТРУДНИКИ-ОТДЕЛЫ, СОТРУДНИКИ-ПРОЕКТЫ и ОТДЕЛЫ-ПРОЕКТЫ. Ранее мы выполняли соединение двух проекций и сразу получали искомый результат. Для восстановлении отношения из трех (или нескольких) проекций надо получить все попарные соединения (так как информация о том, какое из них "лучше", отсутствует), над которыми затем выполнить операцию пересечения множеств. Проверим, так ли это.
СОТРУДНИКИ-ОТДЕЛЫ
Код сотрудника
Код отдела
РД
АД
АД
УП
УП
АД
АД
ЛС
ЛС
УП
УП
ВЦ
ВЦ
ВЦ
ВЦ
СЖ
СОТРУДНИКИ-ПРОЕКТЫ
Код сотрудника
Номер проекта
ОТДЕЛЫ-ПРОЕКТЫ
Код отдела
Номер проекта
РД
АД
ЛС
УП
АД
ЛС
УП
АД
ЛС
АД
ЛС
УП
УП
УП
ВЦ
ВЦ
ВЦ
ВЦ
СЖ
Получим попарные соединения трех приведенных выше отношений, которые будут иметь вид:
*(СО,СП)
Код сотрудника
Код отдела
Номер проекта
РД
АД
УП
АД
ЛС
ЛС
УП
ВЦ
ВЦ
СЖ
Нетрудно увидеть, что пересечение всех отношений дает исходное отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ.
*(СО,ОП)
Код сотрудника
Код отдела
Номер проекта
РД
АД
АД
УП
УП
АД
АД
ЛС
ЛС
УП
УП
ВЦ
ВЦ
ВЦ
ВЦ
СЖ
*(СП, ОП)
Код сотрудника
Код отдела
Номер проекта
РД
АД
ЛС
УП
АД
ЛС
УП
АД
ЛС
АД
ЛС
УП
УП
УП
ВЦ
ВЦ
ВЦ
ВЦ
СЖ
Замечание. Существуют и другие способы восстановления исходного отношения из его проекций. Так, для восстановления отношения СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ можно соединить отношения СОТРУДНИКИ-ОТДЕЛЫ и СОТРУДНИКИ-ПРОЕКТЫ по атрибуту Код_сотрудника, после чего полученное отношение соединить с отношением ОТДЕЛЫ-ПРОЕКТЫ по составному атрибуту (Код_отдела, Номер_проекта). Отношения СОТРУДНИКИ-ОТДЕЛЫ, СОТРУДНИКИ-ПРОЕКТЫ и ОТДЕЛЫ-ПРОЕКТЫ находятся в 5НФ. Эта форма является последней из известных. Условия ее получения довольно нетривиальны и поэтому она почти не используется на практике. Более того, она имеет определенные недостатки! Предположим, необходимо узнать, где и какие проекты исполняет сотрудник с кодом 02. Для этого в отношении СОТРУДНИКИ-ОТДЕЛЫ найдем, что сотрудник с кодом 02 работает в отделе АД, а из отношения ОТДЕЛЫ-ПРОЕКТЫ найдем, что в отделе АД выполняются проекты 004 и 019, А это значит, что сотрудник 02 должен выполнять проекты 004 и 019. Увы, информация о том, что сотрудник с кодом 02 выполняет проект 019, ошибочна (см. исходное отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ). Такие противоречия можно устранить только путем совместного рассмотрения всех проекций основного отношения. Именно поэтому после соединения проекций и выполнялась операция их пересечения. Безусловно, это -'недостаток. Отметим, что наличие недостатков не требует обязательного отказа от определенных видов нормальных форм. Надо учитывать недостатки и условия их проявления. В некоторых постановках задач недостатки не проявляются. На практике обычно ограничиваются структурой БД, соответствующей 3НФ или БКНФ. Поэтому процесс нормализации отношений методом нормальных форм предполагает последовательное удаление из исходного отношения следующих межатрибутных зависимостей: частичных зависимостей неключевых атрибутов от ключа (удовлетворение требований 2НФ); транзитивных зависимостей неключевых атрибутов от ключа (удовлетворение требований 3НФ); зависимости ключей (атрибутов составных ключей) от неключевых атрибутов (удовлетворение требований БКНФ). Кроме метода нормальных форм Кодда, используемого для проектирования небольших БД, применяют и другие методы, например, метод ER-диаграмм (метод "Сущность-связь"). Этот метод используется при проектировании больших БД, на нем основан ряд средств проектирования БД. Метод ER-диаграмм рассматривается в следующем разделе. На последнем этапе метода ER-диаграмм отношения, полученные в результате проектирования, проверяются на принадлежность их к БКНФ. Этот этап может выполняться уже с использованием метода нормальных форм. После завершения проектирования создается БД с помощью СУБД.

 отсутствие списка атрибутов подразумевает указание всех атрибутов (операция тождественной проекции);
отсутствие списка атрибутов подразумевает указание всех атрибутов (операция тождественной проекции); 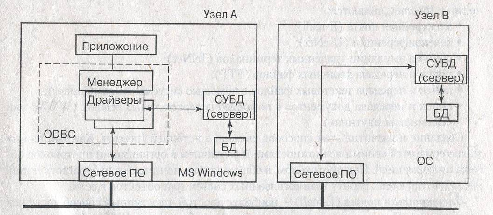 Рис. 4.12. Схема доступа к БД с помощью ODBC
Рис. 4.12. Схема доступа к БД с помощью ODBC
 Рис. 5.5. Зависимости между атрибутами
Рис. 5.5. Зависимости между атрибутами