Современные СУБД позволяют решать широкий круг задач по работе с базами данных без разработки приложения. Тем не менее, есть случаи, когда целесообразно разработать приложение. Например, если требуется автоматизация манипуляций с данными, терминальный интерфейс СУБД недостаточно развит, либо имеющиеся в СУБД стандартные функции по обработке информации не устраивают пользователя. Для разработки приложений СУБД должна иметь программный интерфейс, основу которого составляют функции и/или процедуры соответствующего языка программирования.
Существующие СУБД поддерживают следующие технологии (и их комбинации) разработки приложений: ручное кодирование программ (Clipper, FoxPro, Paradox); создание текстов приложений с помощью генераторов (FoxApp в FoxPro, Personal Programmer в Paradox); автоматическая генерация готового приложения методами визуального программирования (Delphi, Access, Paradox tor Windows).
При ручном кодировании программисты вручную набирают текст программ приложений, после чего выполняют их отладку.
Использование генераторов упрощает разработку приложений, поскольку при этом можно получать программный код без ручного набора. Генераторы приложений облегчают разработку основных элементов приложений (меню, экранных форм, запросов и т. д.), но зачастую не могут полностью исключить ручное кодирование.
Средства визуального программирования приложений являются дальнейшим развитием идеи использования генераторов приложений. Приложение при этом строится из готовых "строительных блоков" с помощью удобной интегрированной среды. При необходимости разработчик легко может вставить в приложение свой код. Интегрированная среда, как правило, предоставляет мощные средства создания, отладки и модификации приложений. Использование средств визуального программирования позволяет в кратчайшие сроки создавать более надежные, привлекательные и эффективные приложения по сравнению с приложениями, полученными первыми двумя способами.
Разработанное приложение обычно состоит из одного или нескольких файлов операционной системы.
Если основным файлом приложения является исполняемый файл (например, ехе-файл), то это приложение, скорее всего, является независимым приложением, которое выполняется автономно от среды СУБД. Получение независимого приложения на практике осуществляется путем компиляции исходных текстов программ, полученных различными способами: путем набора текста вручную, а также полученных с помощью генератора приложения или среды визуального программирования.
Независимые приложения позволяют получать, например, СУБД FoxPro и система визуального программирования Delphi. Отметим, что с помощью средств Delphi обычно независимые приложения не разрабатывают, так как это достаточно трудоемкий процесс, а привлекают процессор баз данных BDE (Borland DataBase Engine), играющий роль ядра СУБД. Одним из первых средств разработки приложений для персональных ЭВМ является система Clipper, представляющая собой "чистый компилятор".
Во многих случаях приложение не может исполняться без среды СУБД. Выполнение приложения состоит в том, что СУБД анализирует содержимое файлов приложения (в частном случае - это текст исходной программы) и автоматически строит необходимые исполняемые машинные команды. Другими словами, приложение выполняется методом интерпретации.
Режим интерпретации реализован во многих современных СУБД, например, Access, Visual FoxPro и Paradox, а также в СУБД недавнего прошлого, к примеру, FoxBase и FoxPro.
Кроме этого, существуют системы, использующие промежуточный вариант между компиляцией и интерпретацией - так называемую псевдокомпиляцию. В таких системах исходная программа путем компиляции преобразуется в промежуточный код (псевдокод) и записывается на диск. В этом виде ее в некоторых системах разрешается даже редактировать, но главная цель псевдокомпиляции - преобразовать программу к виду, ускоряющему процесс ее интерпретации. Такой прием широко применялся в СУБД, работающих под управлением DOS, например, Foxbase+ и Paradox 4.0/4.5 for DOS.
В СУБД, работающих под управлением Windows, псевдокод чаще используют для того, чтобы запретить модифицировать приложение. Это полезно для защиты от случайной или преднамеренной порчи работающей программы. Например, такой прием применен в СУБД Paradox for Windows, где допускается разработанные экранные формы и отчеты преобразовывать в соответствующие объекты, не поддающиеся редактированию.
Некоторые СУБД предоставляют пользователю возможность выбора варианта разработки приложения: как интерпретируемого СУБД программного кода или как независимой программы.
Достоинством применения независимых приложений является то, что время выполнения машинной программы обычно меньше, чем при интерпретации. Такие приложения целесообразно использовать на слабых машинах и в случае установки систем "под ключ", когда необходимо закрыть приложение от доработок со стороны пользователей.
Важным достоинством применения интерпретируемых приложений является легкость их модификации. Если готовая программа подвергается частым изменениям, то для их внесения нужна инструментальная система, т. е. СУБД или аналогичная среда. Для интерпретируемых приложений такой инструмент всегда под рукой, что очень удобно.
Другим серьезным достоинством систем с интерпретацией является то, что хорошие СУБД обычно имеют мощные средства контроля целостности данных и защиты от несанкционированного доступа, чего не скажешь о системах компилирующего типа. В последних упомянутые функции приходится программировать вручную, либо оставлять на совести администраторов.
При выборе средств для разработки приложения следует учитывать три основных фактора: ресурсы компьютера, особенности приложения (потребность в модификации функций программы, время на разработку, необходимость контроля доступа и поддержание целостности информации) и цель разработки (отчуждаемый программный продукт или система автоматизации своей повседневной деятельности).
Для пользователя, имеющего современный компьютер и планирующего создать несложное приложение, по всей видимости, больше подойдет СУБД интерпретирующего типа. Напомним, что такие системы достаточно мощны, имеют высокоуровневые средства, удобны для разработки и отладки, позволяют быстро выполнить разработку и обеспечивают удобное сопровождение и модификацию приложения.
При использовании компьютера со слабыми характеристиками лучше остановить свой выбор на системе со средствами разработки независимых приложений. При этом следует иметь ввиду, что малейшее изменение в приложении влечет за собой циклическое повторение этапов программирования, компиляции и отладки программы. Разница в выполнении независимого приложения и выполнения приложения в режиме интерпретации колеблется в пределах миллисекунд в пользу независимого приложения. В то же время разница во времени подготовки приложения к его использованию обычно составляет величины порядка минуты - часы в пользу систем с интерпретацией.
1.6. Схема обмена данными при работе с БД
Пользователю любой категории (администратору БД, разработчику приложения, обычному пользователю) для грамотного решения задач полезно представлять вычислительный процесс, происходящий в ОС при работе с БД. Раскроем внутренние механизмы этого процесса на примере наиболее общего случая организации ИС, функционирующей на одном ПК, - когда пользователь работает с "полной" версией программы СУБД (рис. 1.3). Варианты, представленные на рис. 1.4 и рис. 1.5, можно считать частными случаями. При работе пользователя с базой данных над ее содержимым выполняются следующие основные операции: выбор, добавление, модификация (замена) и удаление данных. Рассмотрим как происходит обмен данными между отдельным пользователем и персональной СУБД при выполнении наиболее часто используемой операции выбора данных. Обмен данными между пользователем и БД для других операций отличается несущественно. Схематично обмен данными при работе пользователя с БД можно представить так, как показано на рис. 1.6, где обычными стрелками обозначены связи по управлению, утолщенными - связи по информации. Цикл взаимодействия пользователя с БД с помощью приложения можно разделить на следующие основные этапы: 1. Пользователь терминала (1) в процессе диалога с приложением формулирует запрос (2) на некоторые данные из БД. 2. Приложение (3) на программном уровне средствами языка манипулирования данными формулирует запрос (4), с которым обращается к СУБД. 3. Используя свои системные управляющие блоки и таблицы, СУБД с помощью словаря данных определяет местоположение требуемых данных и обращается (5) за ними к ОС. 4. Программы методов доступа файловой системы ОС считывают (6) из внешней памяти искомые данные и помещают их в системные буферы СУБД. 5. Преобразуя полученные данные к требуемому формату, СУБД пересылает их (7) в соответствующую область программы и сигнализирует (8) о завершении операции каким-либо образом (например, кодом возврата). 6. Результаты выбора данных из базы приложение (3) отображает (9) на терминале пользователя (1). В случае работы пользователя в диалоговом режиме с СУБД (без приложения) цикл взаимодействия пользователя с БД упрощается. Его можно представить следующими этапами. 1. Пользователь терминала (10) формулирует на языке запросов СУБД, например QBE, по связи (11) требование на выборку некоторых данных из базы. 2. СУБД определяет местоположение требуемых данных и обращается (5) за ними к ОС, которая считывает (6) из внешней памяти искомые данные и помещает их в системные буферы СУБД. 3. Информация из системных буферов преобразуется (12) к требуемому формату, после чего отображается (13) на терминале пользователя (10). Напомним, что описанная схема поясняет как функционирует СУБД с одним пользователем на отдельной ПЭВМ. Если компьютер и ОС поддерживают многопользовательский режим работы, то в такой вычислительной системе может функционировать многопользовательская СУБД. Последняя, в общем случае, позволяет одновременно обслуживать несколько пользователей, работающих непосредственно с СУБД или с приложениями (каждое из которых может поддерживать работу с одним или несколькими пользователями). Иногда к вычислительной системе подключается так называемый "удаленный пользователь", находящийся на некотором удалении от ЭВМ и соединенный с ней при помощи какой-либо передающей среды (интерфейс ЭВМ, телефонный канал связи, радиоканал, оптико-волоконная линия и т. д.). Чаще всего такой пользователь программным способом эмулируется под обычного локального пользователя. СУБД, как правило, этой подмены "не замечает" и работает по обслуживанию запросов обычным образом. В многопользовательских СУБД при выполнении различных операций параллельно проистекают процессы, подобные описанным выше и показанным на рис. 1.6. При обслуживании нескольких параллельных источников запросов (от пользователей и приложений) СУБД так планирует использование своих ресурсов и ресурсов ЭВМ, чтобы обеспечить независимое или почти независимое выполнение операций, порождаемых запросами. Многопользовательские СУБД часто применяются на больших и средних ЭВМ, где основным режимом использования ресурсов является коллективный доступ. На персональных ЭВМ пользователь обычно работает один, но с различными программами, в том числе и одновременно (точнее, попеременно). Иногда такими программами оказываются СУБД: различные программы или разные копии одной и той же СУБД. Последняя ситуация возникает, например, при работе с различными базами данных с помощью СУБД Access. Технология одновременной работы пользователя с несколькими программами неплохо реализована в Windows. Здесь каждая выполняемая программа имеет свое окно взаимодействия с пользователем, и имеются удобные средства переключения между программами. При работе в Windows СУБД избавлена от необходимости поддержания нескольких сеансов работы с пользователями.
НАВЕРХ
2. Модели и типы данных
Хранимые в базе данные имеют определенную логическую структуру - иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД. К числу классических относятся следующие модели данных: иерархическая, сетевая, реляционная. Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных: постреляционная, многомерная, объектно-ориентированная. Разрабатываются также всевозможные системы, основанные на других моделях данных, расширяющих известные модели. В их числе можно назвать объектно-реляционные, дедуктивно-объектно-ориентированные, семантические, концептуальные и ориентированные модели. Некоторые из этих моделей служат для интеграции баз данных, баз знаний и языков программирования. В некоторых СУБД поддерживается одновременно несколько моделей данных. Например, в системе ИНТЕРБАЗА для приложений применяется сетевой язык манипулирования данными, а в пользовательском интерфейсе реализованы языки SQL и QBE.
НАВЕРХ
2.1. Иерархическая модель
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показано на рис. 2.1. Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных "дерево". Тип "дерево" схож с типами данных "структура" языков программирования ПЛ/1 и Си и "запись" языка Паскаль. В них допускается вложенность типов, каждый из которых находится на некотором уровне. Тип "дерево" является составным. Он включает в себя подтипы ("поддеревья"), каждый из которых, в свою очередь, является типом "дерево". Каждый из типов "дерево" состоит из одного "корневого" типа и упорядоченного набора (возможно пустого)
Рис. 2.1. Представление связей в иерархической модели
подчиненных типов. Каждый из элементарных типов, включенных в тип "дерево", является простым или составным типом "запись". Простая "запись" состоит из одного типа, например, числового, а составная "запись" объединяет некоторую совокупность типов, например, целое, строку символов и указатель (ссылку). Пример типа "дерево" как совокупности типов показан на рис. 2.2. Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу. В целом тип "дерево" представляет собой иерархически организованный набор типов "запись". Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа "дерево" (деревьев), содержащих экземпляры типа "запись" (записи). Часто отношения родства между типами переносят на отношения между самими записями. Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо. В иерархических СУБД может использоваться терминология, отличающаяся от приведенной. Так, в системе IMS понятию "запись" соответствует термин "сегмент", а под "записью БД" понимается вся совокупность записей, относящаяся к одному экземпляру типа "дерево". Данные в базе с приведенной схемой (рис. 2.2) могут выглядеть, например, как показано на рис. 2.3. Для организации физического размещения иерархических данных в памяти ЭВМ могут использоваться следующие группы методов: представление линейным списком с последовательным распределением памяти (адресная арифметика, левосписковые структуры); представление связными линейными списками (методы, использующие указатели и справочники). К основным операциям манипулирования иерархически организованными данными относятся следующие: поиск указанного экземпляра БД (например, дерева со значением 10 в поле Отд_номер); переход от одного дерева к другому; переход от одной записи к другой внутри дерева (например, к следующей записи типа Сотрудники); вставка новой записи в указанную позицию; удаление текущей записи и т. д. В соответствии с определением типа "дерево", можно заключить, что между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. Механизмы поддержания целостности связей между записями различных деревьев отсутствуют. К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией. Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.
НАВЕРХ
2.2. Сетевая модель
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рис. 2.4). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).
Рис. 2.4. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: "запись" и "связь". Тип "связь" определяется для двух типов "запись": предка и потомка. Переменные типа "связь" являются экземплярами связей. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рис. 2.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.
Рис. 2.5. Пример схемы сетевой БД
Рис. 2.5. Пример схемы сетевой БДВ различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие, как элементы и агрегаты данных, записи, наборы, области и т. д. Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных. К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие: поиск записи в БД; переход от предка к первому потомку; переход от потомка к предку; создание новой записи; удаление текущей записи; обновление текущей записи; включение записи в связь; исключение записи из связи; изменение связей и т. д. Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей. Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями. Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db VistaIII, СЕТЬ, СЕТОР и КОМПАС.
НАВЕРХ
2.3. Реляционная модель
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение (relation). Отношение представляет собой множество элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица. Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам - атрибуты отношения. С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно: деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц. Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов. Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми. Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей. Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IY (фирма Ashton-Tate) DB2 (IBM) R:BASE (Microrim) FoxPro ранних версий и FoxBase (Fox Software) Paradox и dBASE for Windows (Borland) FoxPro более поздних версий Visual FoxPro и Access (Microsoft) Clarion (Clarion Software) Ingres (ASK Computer Systems) Oracle (Oracle). К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН УССР), а также система HyTech (МИФИ). Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть до Oracle 7.x считаются "чисто" реляционными.
НАВЕРХ
2.4. Постреляционная модель
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Это означает, что информация в таблице представляется в первой нормальной форме (подраздел 5.2). Существует ряд случаев, когда это ограничение мешает эффективной реализации приложений. Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля - поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. На рис. 2.6 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Таблица INVOICES (накладные) содержит данные о номерах накладных (INVNO) и номерах покупателей (CUSTNO). В таблице INVOICE.ITEMS (накладные-товары) содержатся данные о каждой из накладных: номер накладной (INVNO), название товара (GOODS) и количество товара (QTY). Таблица INVOICES связана с таблицей INVOICE.ITEMS по полю INVNO.
а) INVOICES
INVNO
CUSTNO
INVOICE.ITEMS
INVNO
GOODS
QTY
Сыр
Рыба
Лимонад
Сок
Печенье
Йогурт
б) INVOICES
INVNO
CUSTNO
GOODS
QTY
Сыр
Рыба
Лимонад
Сок
Печенье
Йогурт
Рис. 2.6. Структуры данных реляционной и постреляционной моделей
Как видно из рисунка, по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц. Для доказательства на рис. 2.7 приводятся примеры операторов SELECT выбора данных из всех полей базы на языке SQL для реляционной (а) и постреляционной (б) моделей. Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.
а) SELECT INVOICES.INVNO, CUSTNO, GOODS, QTY FROM INVOICES, INVOICE.ITEMS WHERE INVOICES.INVNO=INVOICE.1TEMS.INVNO; б) SELECT INVNO, CUSTNO, GOODS, QTY FROM INVOICES;
Рис. 2.7. Операторы SQL для реляционной и постреляционной моделей
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеют большую гибкость. Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах. Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки. Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
2.5. Многомерная модель
Многомерный подход к представлению данных в базе появился практически одновременно с реляционным, но реально работающих многомерных СУБД (МСУБД) до настоящего времени было очень мало. С середины 90-х годов интерес к ним стал приобретать массовый характер. Толчком послужила в 1993 году программная статья одного из основоположников реляционного подхода Э. Кодда. В ней сформулированы 12 основных требований к системам класса OLAP (Online Analytical Processing - оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения. В развитии концепций ИС можно выделить следующие два направления: системы оперативной (транзакционной) обработки; системы аналитической обработки (системы поддержки принятия решений). Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области были весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД (МСУБД). Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Раскроем основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных. Агрегируемостъ данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, управляющий, руководитель. Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени. Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки. Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления данных пользователю накладывает требования на механизмы хранения и доступа к информации. Так, для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам. Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Для иллюстрации на рис. 2.8 приведены реляционное (а) и многомерное (б) представления одних и тех же данных об объемах продаж автомобилей. Если речь идет о многомерной модели с мерностью больше двух, то не обязательно визуально информация представляется в виде многомерных объектов (трех-, четырех- и более мерных гиперкубов). Пользователю и в этих случаях более удобно иметь дело с двухмерными таблицами или графиками. Данные при этом представляют собой "вырезки" (точнее, "срезы") из многомерного хранилища данных, выполненные с разной степенью детализации.
а)
Модель
Месяц
Объем
"Жигули"
июнь
"Жигули"
июль
"Жигули"
август
"Москвич"
июнь
"Москвич"
июль
"Волга"
июль
б)
Модель
Июнь
Июль
Август
"Жигули"
"Москвич"
N
"Волга"
N
N
Рис. 2.8. Реляционное и многомерное представление данных
Рассмотрим основные понятия многомерных моделей данных, к числу которых относятся измерение и ячейка. Измерение (Dimension) - это множество однотипных данных, образующих одну из граней гиперкуба. Примерами наиболее часто используемых временных измерений являются Дни, Месяцы, Кварталы и Годы. В качестве географических измерений широко употребляются Города, Районы, Регионы и Страны. В многомерной модели данных измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба. Ячейка (Cell) или показатель - это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, обычно она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам). В примере на рис. 2.8(б) каждое значение ячейки Объем продаж однозначно определяется комбинацией временного измерения (Месяц продаж) и модели автомобиля. На практике зачастую требуется большее количество измерений. Пример трехмерной модели данных приведен на рис. 2.9. В существующих МСУБД используются два основных варианта (схемы) организации данных: гиперкубическая и поликубическая. В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером системы, поддерживающей поликубический вариант БД, является сервер Oracle Express Server. В случае гиперкубической схемы предполагается, что все показатели определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов БД все они имеют одинаковую размерность и совпадающие измерения. Очевидно, в некоторых случаях информация в БД может быть избыточной (если требовать обязательное заполнение ячеек). В случае многомерной модели данных применяется ряд специальных операций, к которым относятся: формирование "среза", "вращение", агрегация и детализация. "Срез" (Slice) представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Формирование "срезов" выполняется для ограничения используемых пользователем значений, так как все значения гиперкуба практически никогда одновременно не используются. Например, если ограничить значения измерения Модель автомобиля в гиперкубе (рис. 2.9) маркой "Жигули", то получится двухмерная таблица продаж этой марки автомобиля различными менеджерами по годам. Операция "вращение" (Rotate) применяется при двухмерном представлении данных. Суть ее заключается в изменении порядка измерений при визуальном представлении данных. Так, "вращение" двумерной таблицы, показанной на рис. 2.8(б), приведет к изменению ее вида таким образом, что по оси Х будет марка автомобиля, а по оси Y - время. Операцию "вращение" можно обобщить и на многомерный случай, если под ней понимать процедуру изменения порядка следования измерений. В простейшем случае, например, это может быть взаимная перестановка двух произвольных измерений. Операции "агрегация" (Drill Up) и "детализация" (Drill Down) означают соответственно переход к более общему и к более детальному представлению информации пользователю из гиперкуба. Для иллюстрации смысла операции "агрегация" предположим, что у нас имеется гиперкуб, в котором помимо измерений гиперкуба, приведенного на рис. 2.9, имеются еще измерения: Подразделение, Регион, Фирма, Страна. Заметим, что в этом случае в гиперкубе существует иерархия (снизу вверх) отношений между измерениями: Менеджер, Подразделение, Регион, Фирма, Страна. Пусть в описанном гиперкубе определено, насколько успешно в 1995 году менеджер Петров продавал автомобили "Жигули" и "Волга". Тогда, поднимаясь на уровень выше по иерархии, с помощью операции "агрегация" можно выяснить, как выглядит соотношение продаж этих же моделей на уровне подразделения, где работает Петров. Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию. Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации. Примерами систем, поддерживающими многомерные модели данных, являются Essbase (Arbor Software), Media Multi-matrix (Speedware), Oracle Express Server (Oracle) и Cache (InterSystems). Некоторые программные продукты, например Media/ MR (Speedware), позволяют одновременно работать с многомерными и с реляционными БД. В СУБД Cache, в которой внутренней моделью данных является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
НАВЕРХ
2.6. Объектно-ориентированная модель
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования. Стандартизованная объектно-ориентированной модель описана в рекомендациях стандарта ODMG-93 (Object Database Management Group - группа управления объектно-ориентированными базами данных). Реализовать в полном объеме рекомендации ODMG-93 пока не удается. Для иллюстрации ключевых идей рассмотрим несколько упрощенную модель объектно-ориентированной БД. Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом (например, строковым - string) или типом, конструируемым пользователем (определяется как class). Значением свойства типа string является строка символов. Значение свойства типа class есть объект, являющийся экземпляром соответствующего класса. Каждый объект-экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект-экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связную иерархию объектов. Пример логической структуры объектно-ориентированной БД библиотечного дела приведен на рис. 2.10. Здесь объект типа- БИБЛИОТЕКА является родительским для объектов-экземпляров классов АБОНЕНТ, КАТАЛОГ и ВЫДАЧА. Различные объекты типа КНИГА могут иметь одного или разных родителей. Объекты типа КНИГА, имеющие одного и того же родителя, должны различаться по крайней мере инвентарным номером (уникален для каждого экземпляра книги), но имеют одинаковые значения свойств isbn, удк, название и автор. Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними состоит в методах манипулирования данными. Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма. Ограниченно могут применяться операции, подобные командам SQL (например, для создания БД). Создание и модификация БД сопровождается автоматическим формированием и последующей корректировкой индексов (индексных таблиц), содержащих информацию для быстрого поиска данных. Рассмотрим кратко понятия инкапсуляции, наследования и полиморфизма применительно к объектно-ориентированной модели БД. Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа КАТАЛОГ добавить свойство, задающее телефон автора книги и имеющее название телефон, то мы получим 2 Зак.925. одноименные свойства у объектов АБОНЕНТ и КАТАЛОГ. Смысл такого свойства будет определяться тем объектом, в который оно инкапсулировано. Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа КНИГА, являющимся потомками объекта типа КАТАЛОГ, можно приписать свойства объекта-родителя: isbn, удк, название и автор. Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство типа abs. Так, определение абстрактных свойств билет и номер в объекте БИБЛИОТЕКА приводит к наследованию этих свойств всеми дочерними объектами АБОНЕНТ, КНИГА и ВЫДАЧА. Не случайно поэтому значения свойства билет классов АБОНЕНТ и ВЫДАЧА, показанных на рисунке, будут одинаковыми - 00015. Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами, Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к нашей объектно-ориентированной БД полиморфизм означает, что объекты класса КНИГА, имеющие разных родителей из класса КАТАЛОГ, могут иметь разный набор свойств. Следовательно, программы работы с объектами класса КНИГА могут содержать полиморфный код. Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД. Определяемый пользователем объект, называемый объектом-целью (свойство объекта имеет тип goal), в общем случае может представлять собой подмножество всей хранимой в БД иерархии объектов. Объект-цель, а также результат выполнения запроса могут храниться в самой базе. Пример запроса о номерах читательских билетов и именах абонентов, получавших в библиотеке хотя бы одну книгу, показан на рис. 2.11. Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложныхсвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки. Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов. В 90-е годы существовали экспериментальные прототипы объектно-ориентированных систем управления базами данных. В настоящее время такие системы получили широкое распространение, в частности, к ним относятся следующие СУБД: РОЕТ (РОЕТ Software), Jasmine (Computer Associates), Versant (Versant Technologies), 02 (Ardent Software), ODB-Jupiter (научно-производственный центр "Интелтек Плюс"), а также Iris, Orion и Postgres.
НАВЕРХ
2.7. Типы данных
Первоначально СУБД применялись преимущественно для решения финансово-экономических задач. При этом, независимо от модели представления, в базах данных использовались следующие основные типы данных: числовые. Примеры значений данных: 0.43, 328, 2Е+5; символьные (алфавитно-цифровые). Примеры значений данных: "пятница", "строка", "программист"; даты, задаваемые с помощью специального типа "Дата" или как обычные символьные данные. Примеры значений данных: 1.12.97, 23/2/1999. В разных СУБД эти типы могли несущественно отличаться друг от друга по названию, диапазону значений и виду представления. Впоследствии в новых областях применения стали появляться специализированные системы обработки данных, например, геоинформационные, обработки видеоизображений и т. д. В связи с этим разработчики стали вводить в традиционные СУБД новые типы данных. К числу сравнительно новых типов данных можно отнести следующие: временные и дата-временные, предназначенные для хранения информации о времени и/или дате. Примеры значений данных: 31.01.85 (дата), 9:10:03 (время), 6.03.1960 12:00 (дата и время); символьные переменной длины, предназначенные для хранения текстовой информации большой длины, например, документа; двоичные, предназначенные для хранения графических объектов, аудио- и видеоинформации, пространственной, хронологической и другой специальной информации. Например, в MS Access таким типом является тип данных "Поле объекта OLE", который позволяет хранить в БД графические данные в формате BMP (Bitmap) и автоматически их отображать при работе с БД; гиперссылки (hyperlinks), предназначенные для хранения ссылок на различные ресурсы (узлы, файлы, документы и т. д.), находящиеся вне базы данных, например, в сети Internet, корпоративной сети intranet или на жестком диске компьютера. Примеры значений данных: http:\\www.chat.ru, ftp:\\chance4u.teens.com. В современных СУБД с различными моделями данных могут использоваться все перечисленные типы данных.
НАВЕРХ
3. Реляционная модель данных
В разделе рассматривается наиболее распространенная реляционная модель представления данных. Даются определение реляционной модели и характеристика ее элементов. Описываются индексирование, связывание таблиц и контроль целостности связей. Рассматриваются теоретические основы построения языков запросов: реляционная алгебра и реляционное исчисление. Дается характеристика языков QBE и SQL, формат операторов и примеры построения запросов с их помощью.
НАВЕРХ
3.1. Определение реляционной модели
Реляционная модель данных (РМД) некоторой предметной области представляет собой набор отношений, изменяющихся во времени. При создании информационной системы совокупность отношений позволяет хранить данные об объектах предметной области и моделировать связи между ними. Элементы РМД и формы их представления приведены в табл. 3.1.
Отношение является важнейшим понятием и представляет собой двумерную таблицу, содержащую некоторые данные. Сущность есть объект любой природы, данные о котором хранятся в базе данных. Данные о сущности хранятся в отношении. Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы. Математически отношение можно описать следующим образом. Пусть даны n множеств Dl, D2, D3,..., Dn, тогда отношение R есть множество упорядоченных кортежей , где dk € Dk, dk - атрибут, a Dk - домен отношения R. На рис. 3.1 приведен пример представления отношения СОТРУДНИК. В общем случае порядок кортежей в отношении, как и в любом множестве, не определен. Однако в реляционных СУБД для удобства кортежи все же упорядочивают. Чаще всего для этого выбирают некоторый атрибут, по которому система автоматически сортирует кортежи по возрастанию или убыванию. Если пользователь не назначает атрибута упорядочения, система автоматически присваивает номер кортежам в порядке их ввода. Формально, если переставить атрибуты в отношении, то получается новое отношение. Однако в реляционных БД перестановка атрибутов не приводит к образованию нового отношения. Домен представляет собой множество всех возможных значений определенного атрибута отношения. Отношение СОТРУДНИК включает 4 домена. Домен 1 содержит фамилии всех сотрудников, домен 2 - номера всех отделов фирмы, домен 3 - названия всех должностей, домен 4 - даты рождения всех сотрудников. Каждый домен образует значения одного типа данных, например, числовые или символьные. Отношение СОТРУДНИК содержит 3 кортежа. Кортеж рассматриваемого отношения состоит из 4-х элементов, каждый из которых выбирается из соответствующего домена. Каждому кортежу соответствует строка таблицы (рис. 3.1). Схема отношения (заголовок отношения) представляет собой список имен атрибутов. Например, для приведенного примера схема отношения имеет вид СОТРУДНИК (ФИО, Отдел, Должность, Д_Рождения). Множество собственно кортежей отношения часто называют содержимым (телом) отношения. Первичным ключом (ключом отношения, ключевым атрибутом) называется атрибут отношения, однозначно идентифицирующий каждый из его кортежей. Например, в отношении СОТРУДНИК (ФИО, Отдел, Должность, Д_Рождения) ключевым является атрибут "ФИО". Ключ может быть составным (сложным), т. е. состоять из нескольких атрибутов. Каждое отношение обязательно имеет комбинацию атрибутов, которая может служить ключом. Ее существование гарантируется тем, что отношение - это множество, которое не содержит одинаковых элементов - кортежей. Т. е. в отношении нет повторяющихся кортежей, а это значит, что, по крайней мере, вся совокупность атрибутов обладает свойством однозначной идентификации кортежей отношения. Во многих СУБД допускается создавать отношения, не определяя ключи. Возможны случаи, когда отношение имеет несколько комбинаций атрибутов, каждая из которых однозначно определяет все кортежи отношения. Все эти комбинации атрибутов являются возможными ключами отношения. Любой из возможных ключей может быть выбран как первичный. Если выбранный первичный ключ состоит из минимально необходимого набора атрибутов, говорят, что он является не избыточным. Ключи обычно используют для достижения следующих целей: 1) исключения дублирования значений в ключевых атрибутах (остальные атрибуты в расчет не принимаются); 2) упорядочения кортежей. Возможно упорядочение по, возрастанию или убыванию значений всех ключевых атрибутов, а также смешанное упорядочение (по одним - возрастание, а по другим - убывание); 3) ускорения работы к кортежами отношения (подраздел 3.2); 4) организации связывания таблиц (подраздел 3.3). Пусть в отношении R1 имеется не ключевой атрибут А, значения которого являются значениями ключевого атрибута В другого отношения R2. Тогда говорят, что атрибут А отношения R1 есть внешний ключ. С помощью внешних ключей устанавливаются связи между отношениями. Например, имеются два отношения СТУДЕНТ (ФИО, Группа, Специальность) и ПРЕДМЕТ (Назв.Пр., Часы), которые связаны отношением СТУДЕНТ_ПРЕДМЕТ (ФИО, . Назв.Пр. Оценка) (рис. 3.2). В связующем отношении атрибуты ФИО и Назв.Пр образуют составной ключ. Эти атрибуты представляют собой внешние ключи, являющиеся первичными ключами других отношений. Реляционная модель накладывает на внешние ключи ограничение для обеспечения целостности данных, называемое ссылочной целостностью. Это означает, что каждому значению внешнего ключа должны соответствовать строки в связываемых отношениях. Поскольку не всякой таблице можно поставить в соответствие отношение, приведем условия, выполнение которых позволяет таблицу считать отношением. 1. Все строки таблицы должны быть уникальны, т. е. не может быть строк с одинаковыми первичными ключами. 2. Имена столбцов таблицы должны быть различны, а значения их простыми, т. е. недопустима группа значений в одном столбце одной строки. 3. Все строки одной таблицы должны иметь одну структуру, соответствующую именам и типам столбцов. 4. Порядок размещения строк в таблице может быть произвольным. Наиболее часто таблица с отношением размещается в отдельном файле. В некоторых СУБД одна отдельная таблица (отношение) считается базой данных. В других СУБД база данных может содержать несколько таблиц. В общем случае можно считать, что БД включает одну или несколько таблиц, объединенных смысловым содержанием, а также процедурами контроля целостности и обработки информации в интересах решения некоторой прикладной задачи. Например, при использовании СУБД Microsoft Access в файле БД наряду с таблицами хранятся и другие объекты базы: запросы, отчеты, формы, макросы и модули. Таблица данных обычно хранится на магнитном диске в отдельном файле операционной системы, поэтому по ее именованию могут существовать ограничения. Имена полей хранятся внутри таблиц. Правила их формирования определяются СУБД, которые, как правило, на длину полей и используемый алфавит серьезных ограничений не накладывают. Если задаваемое таблицей отношение имеет ключ, то считается, что таблица тоже имеет ключ, и ее называют ключевой или таблицей с ключевыми полями. У большинства СУБД файл таблицы включает управляющую часть (описание типов полей, имена полей и другая информация) и область размещения записей. К отношениям можно применять систему операций, позволяющую получать одни отношения из других. Например, результатом запроса к реляционной БД может быть новое отношение, вычисленное на основе имеющихся отношений. Поэтому можно разделить обрабатываемые данные на хранимую и вычисляемую части. Основной единицей обработки данных в реляционных БД является отношение, а не отдельные его кортежи (записи).
3.2. Индексирование
Как отмечалось выше, определение ключа для таблицы означает автоматическую сортировку записей, контроль отсутствия повторений значений в ключевых полях записей и повышение скорости выполнения операций поиска в таблице. Для реализации этих функций в СУБД применяют индексирование. Термин "индекс" тесно связан с понятием "ключ", хотя между ними есть и некоторое отличие. Под индексом понимают средство ускорения операции поиска записей в таблице, а следовательно, и других операций, использующих поиск: извлечение, модификация, сортировка и т. д. Таблицу, для которой используется индекс, называют индексированной. Индекс выполняет роль оглавления таблицы, просмотр которого предшествует обращению к записям таблицы. В некоторых системах, например Paradox, индексы хранятся в индексных файлах, хранимых отдельно от табличных файлов. Варианты решения проблемы организации физического доступа к информации зависят в основном от следующих факторов: вида содержимого в поле ключа записей индексного файла; типа используемых ссылок (указателей) на запись основной таблицы; метода поиска нужных записей. В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (так называемый хеш-код). Преимущество хранения хеш-кода вместо значения состоит в том, что длина свертки независимо от длины исходного значения ключевого поля всегда имеет некоторую постоянную и достаточно малую величину (например, 4 байта), что существенно снижает время поисковых операций. Недостатком хеширования является необходимость выполнения операции свертки (требует определенного времени), а также борьба с возникновением коллизий (свертка различных значений может дать одинаковый хеш-код). Для организации ссылки на запись таблицы могут использоваться три типа адресов: абсолютный (действительный) относительный символический (идентификатор). На практике чаще всего используются два метода поиска: последовательный бинарный (основан на делении интервала поиска пополам). Проиллюстрируем организацию индексирования таблиц двумя схемами: одноуровневой и двухуровневой. При этом примем ряд предположений, обычно выполняемых в современных вычислительных системах Пусть ОС поддерживает прямую организацию данных на магнитных дисках, основные таблицы и индексные файлы хранятся в отдельных файлах. Информация файлов хранится в виде совокупности блоков фиксированного размера, например, целого числа кластеров. При одноуровневой схеме в индексном файле хранятся короткие записи, имеющие два поля: поле содержимого старшего ключа (хеш-кода ключа) адресуемого блока и поле адреса начала этого блока (рис. 3 3). В каждом блоке записи располагаются в порядке возрастания значения ключа или свертки. Старшим ключом каждого блока является ключ его последней записи. Если в индексном файле хранятся хеш-коды ключевых полей индексированной таблицы, то алгоритм поиска нужной записи (с указанным ключом) в таблице включает в себя следующие три этапа. 1. Образование свертки значения ключевого поля искомой записи. 2. Поиск в индексном файле записи о блоке, значение первого поля которого больше полученной свертки (это гарантирует нахождение искомой свертки в этом блоке). 3. Последовательный просмотр записей блока до совпадения сверток искомой записи и записи блока файла. В случае коллизий сверток ищется запись, значение ключа которой совпадает со значением ключа искомой записи. Основным недостатком одноуровневой схемы является то, что ключи (свертки) записей хранятся вместе с записями. Это приводит к увеличению времени поиска записей из-за большой длины просмотра (значения данных в записях приходится пропускать). Двухуровневая схема в ряде случаев оказывается более рациональной, в ней ключи (свертки) записей отделены от содержимого записей (рис. 3.4). В этой схеме индекс основной таблицы распределен по совокупности файлов: одному файлу главного индекса и множеству файлов с блоками ключей. На практике для создания индекса для некоторой таблицы БД пользователь указывает поле таблицы, которое требует индексации. Ключевые поля таблицы во многих СУБД как правило индексируются автоматически. Индексные файлы, создаваемые по ключевым полям таблицы, часто называются файлами первичных индексов. Индексы, создаваемые пользователем для не ключевых полей, иногда называют вторичными (пользовательскими) индексами. Введение таких индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. Индексные файлы, создаваемые для поддержания вторичных индексов таблицы, обычно называются файлами вторичных индексов. Связь вторичного индекса с элементами данных базы может быть установлена различными способами. Один из них - использование вторичного индекса как входа для получения первичного ключа, по которому затем с использованием первичного индекса производится поиск необходимых записей (рис. 3.5). Некоторыми СУБД, например Access, деление индексов на первичные и вторичные не производится. В этом случае используются автоматически создаваемые индексы и индексы, определяемые пользователем по любому из не ключевых полей. Главная причина повышения скорости выполнения различных операций в индексированных таблицах состоит в том, что основная часть работы производится с небольшими индексными файлами, а не с самими таблицами. Наибольший эффект повышения производительности работы с индексированными таблицами достигается для значительных по объему таблиц. Индексирование требует небольшого дополнительного места на диске и незначительных затрат процессора на изменение индексов в процессе работы. Индексы в общем случае могут изменяться перед выполнением запросов к БД, после выполнения запросов к БД, по специальным командам пользователя или программным вызовам приложений.
НАВЕРХ
3.3. Связывание таблиц
При проектировании реальных БД информацию обычно размещают в нескольких таблицах. Таблицы при этом связаны семантикой информации. В реляционных СУБД для указания связей таблиц производят операцию их связывания. Укажем выигрыш, обеспечиваемый в результате связывания таблиц. Многие СУБД при связывании таблиц автоматически выполняют контроль целостности вводимых в базу данных в соответствии с установленными связями. В конечном итоге это повышает достоверность хранимой в БД информации. Кроме того, установление связи между таблицами облегчает доступ к данным. Связывание таблиц при выполнении таких операций как поиск, просмотр, редактирование, выборка и подготовка отчетов обычно обеспечивает возможность обращения к, произвольным полям связанных записей. Это уменьшает количество явных обращений к таблицам данных и число манипуляций в каждой из них.
Основные виды связи таблиц
Между таблицами могут устанавливаться бинарные (между двумя таблицами), тернарные (между тремя таблицами) и, в общем случае, n-арные связи. Рассмотрим наиболее часто встречающиеся бинарные связи. При связывании двух таблиц выделяют основную и дополнительную (подчиненную) таблицы. Логическое связывание таблиц производится с помощью ключа связи. Ключ связи, по аналогии с обычным ключом таблицы, состоит из одного или нескольких полей, которые в данном случае называют полями связи (ПС). Суть связывания состоит в установлении соответствия полей связи основной и дополнительной таблиц. Поля связи основной таблицы могут быть обычными и ключевыми. В качестве полей связи подчиненной таблицы чаще всего используют ключевые поля. В зависимости от того, как определены поля связи основной и дополнительной таблиц (как соотносятся ключевые поля с полями связи), между двумя таблицами в общем случае могут устанавливаться следующие четыре основные вида связи (табл. 3.2): один - один (1:1); один - много (1:М); много - один (М:1); много - много (М:М или M:N).
Характеристика полей связи по видам
1:1
1:М
М:1
М:М
Поля связи основной таблицы
являются ключом
являются ключом
не являются ключом
не являются ключом
Поля связи дополнительной таблицы
являются ключом
не являются ключом
являются ключом
не являются ключом
Таблица 3.2 Характеристика видов связей таблиц
Дадим характеристику названным видам связи между двумя таблицами и приведем примеры их использования.
Связь вида 1:1
Связь вида 1:1 образуется в случае, когда все поля связи основной и дополнительной таблиц являются ключевыми. Поскольку значения в ключевых полях обеих таблиц не повторяются, обеспечивается взаимнооднозначное соответствие записей из этих таблиц. Сами таблицы, по сути, здесь становятся равноправными. Пример 1. Пусть имеются основная 01 и дополнительная Д1 таблицы. Ключевые поля обозначим символом "*", используемые для связи поля обозначим символом "+". В приведенных таблицах установлена связь между записью (а, 10) таблицы 01 и записью (а, стол) таблицы Д1. Основанием этого является совпадение значений в полях связи. Аналогичная связь существует и между записями (в, 3) и (в, книга) этих же таблиц. В таблицах записи отсортированы по значениям в ключевых полях. Сопоставление записей двух таблиц по существу означает образование новых "виртуальных записей" (псевдозаписей). Так, первую пару записей логически можно считать новой псевдозаписью вида (а, 10, стол), а вторую пару - псевдозаписью вида (в,3,книга). На практике связи вида 1:1 используются сравнительно редко, так как хранимую в двух таблицах информацию легко объединить в одну таблицу, которая занимает гораздо меньше места в памяти ЭВМ. Возможны случаи, когда удобнее иметь не одну, а две и более таблицы. Причинами этого может быть необходимость ускорить обработку, повысить удобство работы нескольких пользователей с общей информацией, обеспечить более высокую степень защиты информации и т. д. Приведем пример, иллюстрирующий последнюю из приведенных причин. Пример 2. Пусть имеются сведения о выполняемых в некоторой организации научно-исследовательских работах. Эти данные включают в себя следующую информацию по каждой из работ- тему (девиз и полное наименование работ), шифр (код), даты начала и завершения работы, количество этапов, головного исполнителя и другую дополнительную информацию. Все работы имеют гриф "Для служебного пользования" или "секретно". В такой ситуации всю информацию целесообразно хранить в двух таблицах: в одной из них - всю секретную информацию (например, шифр, полное наименование работы и головной исполнитель), а в другой - всю оставшуюся несекретную информацию. Обе таблицы можно связать по шифру работы. Первую из таблиц целесообразно защитить от несанкционированного доступа.
Связь вида 1:М
Связь 1:М имеет место в случае, когда одной записи основной таблицы соответствует несколько записей вспомогательной таблицы. Пример 3. Пусть имеются две связанные таблицы 02 и Д 2. В таблице 02 содержится информация о видах мультимедиа-устройств ПЭВМ, а в таблице Д2 - сведения о фирмах-производителях этих устройств, а также о наличии на складе хотя бы одного устройства. Таблица Д2 имеет два ключевых поля, так как одна и та же фирма может производить устройства различных видов. В примере фирма Sony производит устройства считывания и перезаписи с компакт-дисков. Сопоставление записей обеих таблиц по полю "Код" порождает псевдозаписи вида: (a, CD-ROM, Acer, да), (a, CD-ROM, Mitsumi, нет), (a, CD-ROM, NEC, да), (a, CD-ROM, Panasonic, да), (a, CD-ROM, Sony, да), (б, CD-Recorder, Philips, нет), (б, CD-Recorder, Sony, да) и т. д. Если свести псевдозаписи в новую таблицу, то получим полную информацию обо всех видах мультимедиа-устройств ПЭВМ, фирмах их производящих, а также сведения о наличии конкретных видов устройств на складе.
Связь вида М:1
Связь М:1 имеет место в случае, когда одной или нескольким записям основной таблицы ставится в соответствие одна запись дополнительной таблицы. Пример 4. Рассмотрим связь таблиц 03 и ДЗ. В основной таблице 03 содержится информация о названиях деталей (Поле11), видах материалов, из которого детали можно изготовить (Поле12), и марках материала (Поле13). В дополнительной таблице ДЗ содержатся сведения о названиях деталей (Поле21), планируемых сроках изготовления (Поле22) и стоимости заказов (Поле23). Связывание этих таблиц обеспечивает такое установление соответствия между записями, которое эквивалентно образованию следующих псевдозаписей: (деталь!, чугун, марка!, 4.03.98, 90), (деталь!, чугун, марка2, 4.03.98, 90), (деталь2, сталь, марка!, 3.01.98, 35), (деталь2, сталь, марка2, 3.01.98, 35), (деталь2, сталь, маркаЗ, 3.01.98, 35), (детальЗ, алюминий, - , 17.02.98, 90), (деталь4, чугун, марка2, 6.05.98, 240). Полученная псевдотаблица может быть полезна при планировании или принятии управленческих решений, когда необходимо иметь все возможные варианты исполнения заказов по каждому изделию. Отметим, что таблица 03 не имеет ключей и в ней возможно повторение записей. Если таблицу ДЗ сделать основной, а таблицу 03 - дополнительной, получим связь вида 1.М. Поступив аналогично с таблицами 02 и Д2, можно получить связь вида М:1. Отсюда следует, что вид связи (1:М или М:1) зависит от того, какая таблица является главной, а какая дополнительной.
Связь вида М:М
Самый общий вид связи М:М возникает в случаях, когда нескольким записям основной таблицы соответствует несколько записей дополнительной таблицы. Пример 5. Пусть в основной таблице 04 содержится информация о том, на каких станках могут работать рабочие некоторой бригады. Таблица Д4 содержит сведения о том, кто из бригады ремонтников какие станки обслуживает. Первой и третьей записям таблицы 04 соответствует первая запись таблицы Д4 (у всех этих записей значение второго поля - "станок!"). Четвертой записи таблицы 04 соответствуют вторая и четвертая записи таблицы Д4 (во втором поле этих записей содержится "станокЗ"). Исходя из определения полей связи этих таблиц можно составить новую таблицу с именем "04+Д4", записями которой будут псевдозаписи. Записям полученной таблицы можно придать смысл возможных смен, составляемых при планировании работы. Для удобства, поля новой таблицы переименованы (кстати, такую операцию предлагают многие из современных СУБД).
Работа
Станок
Обслуживание
Иванов А.В.
станок1
Голубев Б.С.
Иванов А.В.
станок2
Зыков А.Ф.
Петров Н.Г.
станок1
Голубев Б.С.
Петров Н.Г.
станок3
Голубев Б.С.
Петров Н.Г.
станок3
Зыков А.Ф.
Сидоров В.К.
станок2
Зыков А.Ф.
Таблица "04+Д4"
Приведенную таблицу можно использовать, например, для получения ответа на вопрос: "Кто обслуживает станки, на которых трудится Петров Н.Г?". Очевидно, аналогично связи 1:1, связь М:М, не устанавливает подчиненности таблиц. Для проверки этого можно основную и дополнительную таблицу поменять местами и выполнить объединение информации путем связывания. Результирующие таблицы "04+Д4" и "Д4+04" будут отличаться порядком следования первого и третьего полей, а также порядком расположения записей. Замечание На практике в связь обычно вовлекается сразу несколько таблиц. При этом одна из таблиц может иметь различного рода связи с несколькими таблицами. В случаях, когда связанные таблицы, в свою очередь, имеют связи с другими таблицами, образуется иерархия или дерево связей.
НАВЕРХ
3.4. Контроль целостности связей
Из перечисленных видов связи наиболее широко используется связь вида 1:М. Связь вида 1:1 можно считать частным случаем связи 1:М, когда одной записи главной таблицы соответствует одна запись вспомогательной таблицы. Связь М:1, по сути, является "зеркальным отображением" связи 1:М. Оставшийся вид связи М:М характеризуется как слабый вид связи или даже как отсутствие связи. Поэтому в дальнейшем рассматривается связь вида 1:М. Напомним, что при образовании связи вида 1:М одна запись главной таблицы (главная, родительская запись) оказывается связанной с несколькими записями дополнительной (дополнительные, подчиненные записи) и имеет место схема, показанная на рис. 3.6. Контроль целостности связей обычно означает анализ содержимого двух таблиц на соблюдение следующих правил: каждой записи основной таблицы соответствует нуль или более записей дополнительной таблицы; в дополнительной таблице нет записей, которые не имеют родительских записей в основной таблице; каждая запись дополнительной таблицы имеет только одну родительскую запись основной таблицы. Опишем действие контроля целостности при манипулировании данными в таблицах. Рассмотрим три основные операции над данными двух таблиц: ввод новых записей, модификацию записей, удаление записей. При рассмотрении попытаемся охватить все возможные методы организации контроля целостности. В реальных СУБД могут применяться собственные методы, подобные описываемым. При вводе новых записей возникает вопрос определения последовательности ввода записей в таблицы такой, чтобы не допустить нарушение целостности. Исходя из приведенных правил, логичной является схема, при которой данные сначала вводятся в основную таблицу, а потом - в дополнительную. Очередность ввода может быть установлена на уровне целых таблиц или отдельных записей (случай одновременного ввода в несколько открытых таблиц). В процессе заполнения основной таблицы контроль значений полей связи ведется как контроль обычного ключа (на совпадение со значениями тех же полей других записей). Заполнение полей связи дополнительной таблицы контролируется на предмет совпадения со значениями полей связи основной таблицы. Если вновь вводимое значение в поле связи дополнительной таблицы не совпадет ни с одним соответствующим значением в записях основной таблицы, то ввод такого значения должен блокироваться. Модификация записей. Изменение содержимого полей связанных записей, не относящихся к полям связи, очевидно, должно происходить обычным образом. Нас будет интересовать механизм изменения полей связи. При редактировании полей связи дополнительной таблицы очевидным требованием является то, чтобы новое значение поля связи совпадало с соответствующим значением какой-либо записи основной таблицы. Т. е. дополнительная запись может сменить родителя, но остаться без него не должна. Редактирование поля связи основной таблицы разумно подчинить одному из cледующих правил: редактировать записи, у которых нет подчиненных записей. Если есть подчиненные записи, то блокировать модификацию полей связи; изменения в полях связи основной записи мгновенно передавать во все поля связи всех записей дополнительной таблицы (каскадное обновление). В операциях удаления записей связанных таблиц большую свободу, очевидно, имеют записи дополнительной таблицы. Удаление их должно происходить практически бесконтрольно. Удаление записей основной таблицы логично подчинить одному из следующих правил: удалять можно запись, которая не имеет подчиненных записей; запретить (блокировать) удаление записи при наличии подчиненных записей, либо удалять ее вместе со всеми подчиненными записями (каскадное удаление).
3.5. Теоретические языки запросов
Операций, выполняемые над отношениями, можно разделить на две группы. Первую группу составляют операции над множествами, к которым относятся операции: объединения пересечения разности деления декартова произведения. Вторую группу составляют специальные операции над отношениями, к которым, в частности, относятся операции: проекции, соединения, выбора. В различных СУБД реализована некоторая часть операций над отношениями, определяющая в какой-то мере возможности данной СУБД и сложность реализации запросов к БД. В реляционных СУБД для выполнения операций над отношениями используются две группы языков, имеющие в качестве своей математической основы теоретические языки запросов, предложенные Э.Коддом: реляционная алгебра; реляционное исчисление. Эти языки представляют минимальные возможности реальных языков манипулирования данными в соответствии с реляционной моделью и эквивалентны друг другу по своим выразительным возможностям. Существуют не очень сложные правила преобразования запросов между ними. В реляционной алгебре операнды и результаты всех действий являются отношениями. Языки реляционной алгебры являются процедурными, так как отношение, являющееся результатом запроса к реляционной БД, вычисляется при выполнении последовательности реляционных операторов, применяемым к отношениям. Операторы состоят из операндов, в роли которых выступают отношения, и реляционных операций. Результатом реляционной операции является отношение. Языки исчислений, в отличие от реляционной алгебры, являются непроцедурными (описательными, или декларативными) и позволяют выражать запросы с помощью предиката первого порядка (высказывания в виде функции), которому должны удовлетворять кортежи или домены отношений. Запрос к БД, выполненный с использованием подобного языка, содержит лишь информацию о желаемом результате. Для этих языков характерно наличие наборов правил для записи запросов. В частности, к языкам этой группы относится SQL. При рассмотрении языков реляционной алгебры и исчислений будем использовать базу данных, включающую в себя следующие таблицы: S (поставщики); Р (детали); SP (поставки). Первичными ключами этих таблиц являются соответственно: П# (код поставщика), Д# (код детали) и составной ключ (П#, Д#). Содержимое таблиц приведено на рис. 3.7. Для удобства изложения предположим, что в рассматриваемых языках запросов нет ограничений на употребление символов русского алфавита в именах атрибутов. Каждое из полей П# и Д# таблицы SP в отдельности является внешним ключом по отношению к таблице S и Р соответственно.
S
П#
Имя
Статус
Город_П
S1
Сергей
Москва
S2
Иван
Киев
S3
Борис
Киев
S4
Николай
Москва
S5
Андрей
Минск
P
Д#
Название
Тип
Вес
Город_Д
Р1
гайка
каленый
Москва
Р2
болт
мягкий
Киев
РЗ
винт
твердый
Ростов
P4
винт
каленый
Москва
Р5
палец
твердый
Киев
Р6
шпилька
каленый
Москва
SP
#
Д#
Количество
S1
P2
S1
P3
S1
P4
S1
P5
S1
P6
S2
P1
S2
P2
S3
P2
S4
P2
S4
P4
S4
P5
Рис. 3.7. Таблицы поставщиков, деталей и поставок
Предположим, что имена доменов (множеств допустимых значений) совпадают с именами атрибутов. Исключение составляют атрибуты Город_П (город, в котором находится поставщик) и Город_Д (город, в котором выпускается деталь), которые имеют общий домен: множество названий городов. Имя этого домена может быть, например, просто Город. Характеристики доменов как типов данных следующие: Д# - строка символов длиной 5, Имя - строка символов длиной 20, Статус - цифровое длиной 5, Город - строка символов длиной 15, Д# - строка символов длиной 6, Тип - строка символов длиной 6, Вес - цифровое длиной 5, Количество - цифровое длиной 5.
НАВЕРХ
3.6. Реляционная алгебра
Реляционная алгебра как теоретический язык запросов по сравнению с реляционным исчислением более наглядно описывает выполняемые над отношениями действия. Примером языка запросов, основанного на реляционной алгебре, является ISBL (Information System Base Language - базовый язык информационных систем). Языки запросов, построенные на основе реляционной алгебры, в современных СУБД широкого распространения не получили. Однако знакомство с ней полезно для понимания сути реляционных операций, выражаемых другими используемыми языками. Вариант реляционной алгебры, предложенный Коддом, включает в себя следующие основные операции: объединение, разность (вычитание), пересечение, декартово (прямое) произведение (или произведение), выборка (селекция, ограничение), проекция, деление и соединение. Упрощенное графическое представление этих операций приведено на рис. 3.8. По справедливому замечанию Дейта, реляционная алгебра Кодда обладает несколькими недостатками. Во-первых, восемь перечисленных операций по охвату своих функций, с одной стороны, избыточны, так как минимально необходимый набор составляют пять операций: объединение, вычитание, произведение, проекция и выборка. Три другие операции (пересечение, соединение и деление) можно определить через пять минимально необходимых. Так, например, соединение - это проекция выборки произведения. Во-вторых, этих восьми операций недостаточно для построения реальной СУБД на принципах реляционной алгебры. Требуются расширения, включающие операции: переименования атрибутов, образования новых вычисляемых атрибутов, вычисления итоговых функций, построения сложных алгебраических выражений, присвоения, сравнения и т. д. Рассмотрим перечисленные операции более подробно, сначала - операции реляционной алгебры Кодда, а затем - дополнительные операции, введенные Дейтом. Операции реляционной алгебры Кодда можно разделить на две группы: базовые теоретико-множественные и специальные реляционные. Первая группа операций включает в себя классические операции теории множеств: объединение, разность, пересечение и произведение. Вторая группа представляет собой развитие обычных теоретико-множественных операций в направлении к реальным задачам манипулирования данными, в ее состав входят следующие операции: проекция, селекция, деление и соединение. Операции реляционной алгебры могут выполняться над одним отношением (например, проекция) или над двумя отношениями (например, объединение). В первом случае операция называется унарной, а во втором - бинарной. При выполнении бинарной операции участвующие в операциях отношения должны быть совместимы по структуре. Совместимость структур отношений означает совместимость имен атрибутов и типов соответствующих доменов. Частным случаем совместимости является идентичность (совпадение). Для устранения конфликтов имен атрибутов в исходных отношениях (когда совпадение имен недопустимо), а также для построения произвольных имен атрибутов результирующего отношения применяется операция переименования атрибутов. Структура результирующего отношения по определенным правилам наследует свойства структур исходных отношений. В большинстве рассматриваемых бинарных реляционных операций будем считать, что заголовки исходных отношений идентичны, так как в этом случае не возникает проблем с заголовком результирующего отношения (в общем случае, заголовки могут не совпадать, тогда нужно оговаривать правила формирования заголовка отношения-результата). Объединением двух совместимых отношений R1 и R2 одинаковой размерности (Rl UNION R2) является отношение R, содержащее все элементы исходных отношений (с исключением повторений). Пример 1. Объединение отношений. Пусть отношением Rl будет множество поставщиков из Лондона, а отношение R2 - множество поставщиков, которые поставляют деталь Р1. Тогда отношение R обозначает поставщиков, находящихся в Лондоне, или поставщиков, выпускающих деталь Р1, либо тех и других.
R1
П#
Имя
Статус
Город_П
S1
Сергей
Москва
S4
Николай
Москва
R2
П#
Имя
Статус
Город_П
S1
Сергей
Москва
S2
Иван
Киев
R (R1 UNION R2)
П#
Имя
Статус
Город_П
S1
Сергей
Москва
S2
Иван
Киев
S4
Николай
Москва
Вычитание совместимых отношений R1 и R2 одинаковой размерности (R1 MINUS R2) есть отношение, тело которого состоит из множества кортежей, принадлежащих Rl, но не принадлежащих отношению R2. Для тех же отношений R1 и R2 из предыдущего примера отношение R будет представлять собой множество поставщиков, находящихся в Лондоне, но не выпускающих деталь Р1, т. е. R={(S4, Николай, 20, Москва)}. Заметим, что результат операции вычитания зависит от порядка следования операндов, т. е. R1 MINUS R2 и R2 MINUS R1 - не одно и то же. Пересечение двух совместимых отношений R1 и R2 одинаковой размерности (R1 INTERSECT R2) порождает отношение R с телом, включающим в себя кортежи, одновременно принадлежащие обоим исходным отношениям. Для отношений R1 и R2 результирующее отношение R будет означать всех производителей из Лондона, выпускающих деталь Р1. Тело отношения R состоит из единственного элемента (S1, Сергей, 20, Москва). Произведение отношения R1 степени к1 и отношения R2 степени к2 (R1 TIMES R2), которые не имеют одинаковых имен атрибутов, есть такое отношение R степени (к1+к2), заголовок которого представляет сцепление заголовков отношений R1 и R2, а тело - имеет кортежи, такие, что первые к1 элементов кортежей принадлежат множеству R1, а последние к2 элементов - множеству R2. При необходимости получить произведение двух отношений, имеющих одинаковые имена одного или нескольких атрибутов, применяется операция переименования RENAME, рассматриваемая далее. Пример 2. Произведение отношений. Пусть отношение R1 представляет собой множество номеров всех текущих поставщиков {S1, S2, S3, S4, S5}, а отношение R2 - множество номеров всех текущих деталей {Р1, Р2, РЗ, Р4, Р5, Р6}. Результатом операции Rl TIMES R2 является множество всех пар типа "поставщик-деталь", т. е. {(S1,P1), (S1,P2), (S1,P3), (S1,P4), (S1,P5), (S1,P6), (S2,P1),..., (S5,P6)}. Заметим, что в теории множеств результатом операции прямого произведения является множество, каждый элемент которого является парой элементов, первый из которых принадлежит R1, а второй - принадлежит R2. Поэтому кортежами декартова произведения бинарных отношений будут кортежи вида: ((а, 6), (в, г)), где кортеж (а, б) принадлежит отношению R1, а кортеж (в, г) - принадлежит отношению R2. В реляционной алгебре применяется расширенный вариант прямого произведения, при котором элементы кортежей двух исходных отношений сливаются, что при записи кортежей результирующего отношения означает удаление лишних скобок, т. е. (а, б, в, г). Выборка (R WHERE f) отношения R по формуле f представляет собой новое отношение с таким же заголовком и телом, состоящим из таких кортежей отношения R, которые удовлетворяют истинности логического выражения, заданного формулой f. Для записи формулы используются операнды - имена атрибутов (или номера столбцов), константы, логические операции (AND - И, OR - ИЛИ, NOT - НЕ), операции сравнения и скобки. Примеры 3. Выборки.

 ручное кодирование программ (Clipper, FoxPro, Paradox);
ручное кодирование программ (Clipper, FoxPro, Paradox); 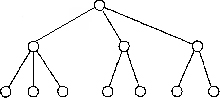 Рис. 2.1. Представление связей в иерархической модели
Рис. 2.1. Представление связей в иерархической модели
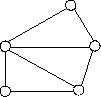 Рис. 2.4. Представление связей в сетевой модели
Рис. 2.4. Представление связей в сетевой модели
 Рис. 2.5. Пример схемы сетевой БД
Рис. 2.5. Пример схемы сетевой БД