В естественных науках большей частью имеют дело с функциональными зависимостями, при которых каждому значению одной переменной соответствует единственное значение другой. Однако в подавляющем большинстве случаев между экономическими переменными таких зависимостей нет. Например, нет строгой зависимости между доходом и потреблением, ценой и спросом, производительностью труда и стажем работы и т.д.
Поэтому в экономике говорят не о функциональных, а о корреляционных, либо статистических, зависимостях.
Статистической (стохастической, вероятностной) называют зависимость, при которой изменение одной из величин влечет изменение распределения другой.
Статистическая зависимость называется корреляционной, если каждому значению одной переменной соответствует определенное условное математическое ожидание (среднее значение) другой.
Суть регрессионного анализа
Можно указать два варианта рассмотрения взаимосвязей между двумя переменными X и Y. В первом случае обе переменные считаются равноценными в том смысле, что они не подразделяются на первичную и вторичную (независимую и зависимую) переменные. Основным в этом случае является вопрос о наличии и силе взаимосвязи между этими переменными.
Например, между ценой товара и объемом спроса на него, между урожаем картофеля и урожаем зерна, между интенсивностью движения транспорта и числом аварий(лекари и больные). При исследовании силы линейной зависимости между такими переменными обращаются к корреляционному анализу, основной мерой которого является коэффициент корреляции.
Другой вариант рассмотрения взаимосвязей выделяет одну из величин как независимую (объясняющую), а другую как зависимую (объясняемую). В этом случае изменение первой из них может служить причиной для изменения другой. Например, рост дохода ведет к увеличению потребления; рост цены — к снижению спроса; снижение процентной ставки увеличивает инвестиции; увеличение обменного курса валюты сокращает объем чистого экспорта и т.д. Однако такая зависимость не является однозначной в том смысле, что каждому конкретному значению объясняющей переменной (набору объясняющих переменных) может соответствовать не одно, а множество значений из некоторой области. Другими словами,
каждому конкретному значению объясняющей переменной (набору объясняющих переменных) соответствует некоторое вероятностное распределение зависимой переменной (рассматриваемой как СВ). Поэтому анализируют, как объясняющая переменная влияет на зависимую переменную «в среднем». Зависимость такого типа, выражаемая соотношением
,
(4.1)
называется функцией регрессии Y на X. При этом X называется независимой (объясняющей) переменной (регрессором), Y — зависимой (объясняемой) переменной. При рассмотрении зависимости двух СВ говорят о парной регрессии.
Для отражения того факта, что реальные значения зависимой переменной не всегда совпадают с ее условными математическими ожиданиями и могут быть различными при одном и том же значении объясняющей переменной (наборе объясняющих переменных), фактическая зависимость должна быть дополнена некоторым слагаемым , которое, по существу, является СВ.
Наиболее существенные причины обязательного присутствия в регрессионных моделях случайного фактора (отклонения) следующие:
1. Невключение в модель всех объясняющих переменных..
2. Неправильный выбор функциональной формы модели.
3. Агрегирование переменных..
4. Ошибки измерений.
5. Ограниченность статистических данных.
6. Непредсказуемость человеческого фактора.
Случайный член является суммарным проявлением всех этих факторов.
Решение задачи построения качественного уравнения регрессии, соответствующего эмпирическим данным и целям исследования, является достаточно сложным и многоступенчатым процессом. Его можно разбить на три этапа:
1) выбор формулы уравнения регрессии;
2) определение параметров выбранного уравнения;
3) анализ качества уравнения и поверка адекватности уравнения эмпирическим данным, совершенствование уравнения.
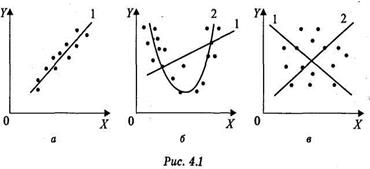
Выбор формулы связи переменных называется спецификацией уравнения регрессии. В случае парной регрессии выбор формулы обычно осуществляется по графическому изображению реальных статистических данных в виде точек в декартовой системе координат, которое называется корреляционным полем (диаграммой рассеивания) (рис. 4.1).
На рис. 4.1 представлены три ситуации.
На графике 4.1, а взаимосвязь между X и Y близка к линейной. В данном случае в качестве зависимости между X и Y целесообразно выбрать линейную функцию .
На графике 4.1, б реальная взаимосвязь между X и Y, скорее всего, описывается квадратичной функцией .
На графике 4.1, в явная взаимосвязь между X и Y отсутствует.
В случае множественной регрессии определение подходящего вида зависимости является более сложной задачей.

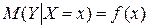 ,
,
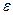 , которое, по существу, является СВ.
, которое, по существу, является СВ. ,
,
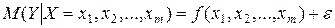 ,
,
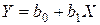 .
.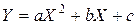 .
.