Построить по ней диаграмму состояний и использовать ДС для разбора цепочек : 11.010 , 0.1 , 01. , 100 . Какой язык порождает эта грамматика ?
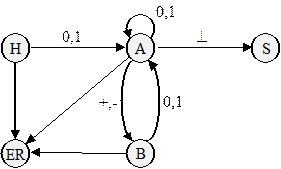
2. Дана ДС.
a) Осуществить разбор цепочек 1011 , 10+011 и 0-101+1 .
b) Восстановить регулярную грамматику, по которой была построена данная ДС.
c) Какой язык порождает полученная грамматика?
3. Пусть имеется переменная cи функция gc(), считывающая в с очередной символ анализируемой цепочки. Дана ДС с действиями:
a) Определить, что будет выдано на печать при разборе цепочки 1+101//p11+++1000/5^?
b) Написать на языке Си анализатор по этой ДС.
4. Построить регулярную грамматику, порождающую язык
L = {(abb)k^| k ³ 1},
по ней построить ДС, а затем по ДС написать на языке Си анализатор для этого языка.
5. Построить ДС, по которой в заданном тексте, оканчивающемся на ^, выявляются все парные комбинации <>, <= и >= и подсчитывается их общее количество.
6. Дана регулярная грамматика:
S ® A^
A ® Ab | Bb | b
B ® Aa
Определить язык, который она порождает; построить ДС; написать на языке Си анализатор.
7. Написать на языке Си анализатор, выделяющий из текста вещественные числа без знака (они определены как в Паскале) и преобразующий их из символьного представления в числовое.
8. Даны две грамматики G1 и G2:
G1: S ® 0C | 1B | e G2: S ® 0D | 1B
B ® 0B | 1C | e B ® 0C | 1C
C ® 0C | 1C C ® 0D | 1D | e
D ® 0D | 1D
L1 = L(G1); L2 = L(G2).
Построить регулярную грамматику для:
a) L1ÈL2
b) L1ÇL2
Если разбор по ней оказался недетерминированным, найти эквивалентную ей грамматику, допускающую детерминированный разбор.
c) написать Р-грамматику, почти эквивалентную данной;
d) построить ДС и написать анализатор на языке Си.
S ® 0S | S0 | D
D ® DD | 1A | e
A ® 0B | e
B ® 0A | 0
11. Написать анализатор на языке Си по следующей грамматике:
a) S ® C^ b) S ® C^
B ® B1 | 0 | D0 C ® B1
C ® B1 | C1 B ® 0 | D0
D ® D0 | 0 D ® B1
c) S ® A0
A ® A0 | S1 | 0
12. Грамматика G определяет язык L=L1ÈL2, причем L1 ÇL2 =Æ. Написать регулярную грамматику G1, которая порождает язык L1*L2 (см. §2.4, задача 20). Для нее построить ДС и написать анализатор на языке Си.
S ® 0A | 1S
A ® 0A | 1B
B ® 0B | 1B | ^
13. Даны две грамматики G1 и G2, порождающие языки L1 и L2. Построить регулярные грамматики для
a) L1 È L2
b) L1 Ç L2
c) L1 * L2 (см. §2.4, задача 20)
G1: S ® 0B | 1S G2: S ® B^
B ® 0C | 1B | e A ® B1 | 0
C ® 0B | 1S B ® A1 | C1 | B0 | 1
C ® A0 | B1
Для грамматики b) построить ДС и написать анализатор на языке Си.
14. По данной грамматике G1 построить регулярную грамматику G2 для языка L1* L1 (см. задачу 20), где L1 = L(G1); по грамматике G2 - ДС и анализатор на языке Си.
a) L = {w^ | w Î {0,1}* , где за каждой 1 непосредственно следует 0};
b) L = {1w1^ | w Î {0,1}+ , где между вхождениями 1 нечетное количество 0};
по ней построить ДС, а по ДС написать на языке Си анализатор.
16. Построить лексический блок (преобразователь) для кода Морзе. Входом служит последовательность "точек", "тире" и "пауз" :
например, ..--. .- ...- ^. Выходом являются соответствующие буквы, цифры и знаки пунктуации. Особое внимание обратить на организацию таблицы.
В данной главе рассматривается сущность и задачи синтаксического и семантического анализа. На примере модельного паскалеподобного языка (М-языка) демонстрируется построение синтаксического анализатора методом рекурсивного спуска с синтаксически-управляемым контролем контекстных условий. Приводятся примеры программ на языке Си, в которых реализованы излагаемые в этой главе алгоритмы.
На этапе синтаксического анализа нужно установить, имеет ли цепочка лексем структуру, заданную синтаксисом языка, и зафиксировать эту структуру. Следовательно, снова надо решать задачу разбора: дана цепочка лексем, и надо определить, выводима ли она в грамматике, определяющей синтаксис языка. Однако структура таких конструкций как выражение, описание, оператор и т.п. более сложная, чем структура идентификаторов и чисел. Поэтому для описания синтаксиса языков программирования нужны более мощные грамматики, чем регулярные. Обычно для этого используют укорачивающие контекстно-свободные грамматики (УКС-грамматики), правила которых имеют вид
A ® a, где A Î VN, a Î (VT È VN)*. Грамматики этого класса, с одной стороны, позволяют достаточно полно описать синтаксическую структуру реальных языков программирования; с другой стороны, для разных подклассов УКС-грамматик существуют достаточно эффективные алгоритмы разбора.
С теоретической точки зрения существует алгоритм, который по любой данной КС-грамматике и данной цепочке выясняет, принадлежит ли цепочка языку, порождаемому этой грамматикой. Но время работы такого алгоритма (синтаксического анализа с возвратами) экспоненциально зависит от длины цепочки, что с практической точки зрения совершенно неприемлемо.
Существуют табличные методы анализа ([3]), применимые ко всему классу КС-грамматик и требующие для разбора цепочек длины n времени cn3 (алгоритм Кока-Янгера-Касами) либо cn2 (алгоритм Эрли). Их разумно применять только в том случае, если для интересующего нас языка не существует грамматики, по которой можно построить анализатор с линейной временной зависимостью.
Алгоритмы анализа, расходующие на обработку входной цепочки линейное время, применимы только к некоторым подклассам КС-грамматик. Рассмотрим на конкретном примере один из таких методов – метод рекурсивного спуска.