Допустим, что разбор на каждом шаге детерминированный.
Для того чтобы быстрее находить правило с подходящей правой частью, зафиксируем все возможные свертки (это определяется только грамматикой и не зависит от вида анализируемой цепочки).
Это можно сделать в виде таблицы, строки которой помечены нетерминальными символами грамматики, столбцы - терминальными. Значение каждого элемента таблицы - это нетерминальный символ, к которому можно свернуть пару "нетерминал-терминал", которыми помечены соответствующие строка и столбец.
Для грамматики G = ({a, b, ^}, {S, A, B, C}, P, S) зафиксируем все возможные свертки с помощью таблицы:
P: S ® C^
С ® Ab | Ba
A ® a | Ca
B ® b | Cb
a
b
^
С
A
B
S
A
-
C
-
B
C
-
-
S
-
-
-
Знак "-" ставится в том случае, если для пары "терминал-нетерминал" свертки нет.
Однако информацию о возможных свертках чаще представляют в виде диаграммы состояний(ДС)- неупорядоченного ориентированного помеченного графа, который строится следующим образом:
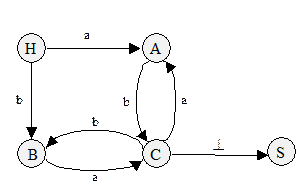
1) строят вершины графа, помеченные нетерминалами грамматики (для каждого нетерминала - одну вершину), и еще одну вершину, помеченную символом, отличным от нетерминальных (например, H). Эти вершины будем называть состояниями.H - начальное состояние;
2) соединяем эти состояния дугами по следующим правилам:
- для каждого правила грамматики вида W ® t соединяем дугой состояния H и W (от H к W) и помечаем дугу символом t;
- для каждого правила W ® Vt соединяем дугой состояния V и W
(от V к W) и помечаем дугу символом t.
Диаграмма состояний для грамматики G из примера 3.1 показана на рис. 3.1:
Рис. 3.1. Диаграмма состояний
Алгоритм разбора по диаграмме состояний:
(1) объявляем текущим состояние H;
(2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: считываем очередной символ исходной цепочки и переходим из текущего состояния в другое состояние по дуге, помеченной этим символом. Состояние, в которое мы при этом попадаем, становится текущим.
При работе этого алгоритма возможны следующие ситуации (аналогичные ситуациям, которые возникают при разборе непосредственно по регулярной грамматике):
(1) прочитана вся цепочка; на каждом шаге находилась единственная дуга, помеченная очередным символом анализируемой цепочки; в результате последнего перехода оказались в состоянии S. Это означает, что исходная цепочка принадлежит L(G).
(2) прочитана вся цепочка; на каждом шаге находилась единственная "нужная" дуга; в результате последнего шага оказались в состоянии, отличном от S. Это означает, что исходная цепочка не принадлежит L(G).
(3) на некотором шаге не нашлось дуги, выходящей из текущего состояния и помеченной очередным анализируемым символом. Это означает, что исходная цепочка не принадлежит L(G).
(4) на некотором шаге работы алгоритма оказалось, что есть несколько дуг, выходящих из текущего состояния, помеченных очередным анализируемым символом, но ведущих в разные состояния. Это говорит онедетерминированности разбора. Анализ этой ситуации будет приведен ниже.
Диаграмма состояний определяет конечный автомат, построенный по регулярной грамматике, который допускает множество цепочек, составляющих язык, определяемый этой грамматикой. Состояния и дуги ДС - это графическое изображение функции переходов конечного автомата из состояния в состояние при условии, что очередной анализируемый символ совпадает с символом-меткой дуги. Среди всех состояний выделяется начальное (считается, что в начальный момент своей работы автомат находится в этом состоянии) и конечное (если автомат завершает работу переходом в это состояние, то анализируемая цепочка им допускается).
Конечный автомат(КА) - это пятерка (K, VT, F, H, S), где
K - конечное множество состояний;
VT - конечное множество допустимых входных символов;
F - отображение множества K ´ VT ® K, определяющее поведение автомата; отображение F часто называют функцией переходов;
H Î K - начальное состояние;
S Î K - заключительное состояние (либо конечное множество заключительных состояний).
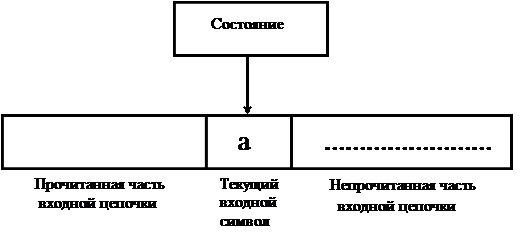
Работа конечного автомата представляет собой некоторую последовательность шагов, или тактов. Такт определяется текущим состоянием управляющего устройства и входным символом, обозреваемым в данный момент входной головкой. Сам шаг состоит из изменения состояния и, возможно, сдвига входной головки на одну ячейку вправо (рис. 3.2).
Пусть M = (K, VT, F, H, S) – конечный автомат. Конфигурацией автомата M называется пара (h, w) Î K ´ VT *, где h – текущее состояние управляющего устройства, а w – цепочка символов на входной ленте, состоящая из символа под головкой и всех символов справа от него.
Конфигурация (H, w) называется начальной, а конфигурация (h, ε), где hÎS –заключительной (или допускающей).
F(A, t) = B означает, что из состояния A по входному символу t происходит переход в состояние B.
Рис. 3.2. Принцип работы конечного автомата
Будем говорить, что конечный автомат допускает цепочку a1a2...an, если F(H,a1) = A1; F(A1,a2) = A2; . . . ; F(An-2,an-1) = An-1; F(An-1,an) = S, где ai Î VT, Aj Î K, j = 1, 2 , ... ,n-1; i = 1, 2, ... ,n; H - начальное состояние, S - одно из заключительных состояний.
Множество цепочек, допускаемых конечным автоматом, составляет определяемый им язык.
Для более удобной работы с диаграммами состояний введем несколько соглашений:
- если из одного состояния в другое выходит несколько дуг, помеченных разными символами, то будем изображать одну дугу, помеченную всеми этими символами;
- непомеченная дуга будет соответствовать переходу при любом символе, кроме тех, которыми помечены другие дуги, выходящие из этого состояния;
- введем состояние ошибки (ER); переход в это состояние будет означать, что исходная цепочка языку не принадлежит.
По диаграмме состояний легко написать лексический анализатор для регулярной грамматики.