- Первая причина буферизации – это разные скорости приема и передачи информации, которыми обладают участники обмена. Рассмотрим, например, случай передачи потока данных от клавиатуры к модему. Скорость, с которой поставляет информацию клавиатура, определяется скоростью набора текста человеком и обычно существенно меньше скорости передачи данных модемом. Для того чтобы не занимать модем на все время набора текста, делая его недоступным для других процессов и устройств, целесообразно накапливать введенную информацию в буфере или нескольких буферах достаточного размера и отсылать ее через модем после заполнения буферов.
- Вторая причина буферизации – это разные объемы данных, которые могут быть приняты или получены участниками обмена единовременно. Возьмем другой пример. Пусть информация поставляется модемом и записывается на жесткий диск. Помимо обладания разными скоростями совершения операций, модем и жесткий диск представляют собой устройства разного типа. Модем является символьным устройством и выдает данные байт за байтом, в то время как диск является блочным устройством и для проведения операции записи для него требуется накопить необходимый блок данных в буфере. Здесь также можно применять более одного буфера. После заполнения первого буфера модем начинает заполнять второй, одновременно с записью первого на жесткий диск. Поскольку скорость работы жесткого диска в тысячи раз больше, чем скорость работы модема, к моменту заполнения второго буфера операция записи первого будет завершена, и модем снова сможет заполнять первый буфер одновременно с записью второго на диск.
- Третья причина буферизации связана с необходимостью копирования информации из приложений, осуществляющих ввод-вывод, в буфер ядра операционной системы и обратно. Допустим, что некоторый пользовательский процесс пожелал вывести информацию из своего адресного пространства на внешнее устройство. Для этого он должен выполнить системный вызов с обобщенным названием write, передав в качестве параметров адрес области памяти, где расположены данные, и их объем. Если внешнее устройство временно занято, то возможна ситуация, когда к моменту его освобождения содержимое нужной области окажется испорченным (например, при использовании асинхронной формы системного вызова). Чтобы избежать возникновения подобных ситуаций, проще всего в начале работы системного вызова скопировать необходимые данные в буфер ядра операционной системы, постоянно находящийся в оперативной памяти, и выводить их на устройство из этого буфера.
Под словом кэш (cash – "наличные"), этимологию которого мы не будем здесь рассматривать, обычно понимают область быстрой памяти, содержащую копию данных, расположенных где-либо в более медленной памяти, предназначенную для ускорения работы вычислительной системы. Мы с вами сталкивались с этим понятием при рассмотрении иерархии памяти. В базовой подсистеме ввода-вывода не следует смешивать два понятия, буферизацию и кэширование, хотя зачастую для выполнения этих функций отводится одна и та же область памяти. Буфер часто содержит единственный набор данных, существующий в системе, в то время как кэш по определению содержит копию данных, существующих где-нибудь еще. Например, буфер, используемый базовой подсистемой для копирования данных из пользовательского пространства процесса при выводе на диск, может в свою очередь применяться как кэш для этих данных, если операции модификации и повторного чтения данного блока выполняются достаточно часто.
Функции буферизации и кэширования не обязательно должны быть локализованы в базовой подсистеме ввода-вывода. Они могут быть частично реализованы в драйверах и даже в контроллерах устройств, скрытно по отношению к базовой подсистеме.
13.12. Spooling и захват устройств
О понятии spooling мы говорили в первой лекции нашего курса, как о механизме, впервые позволившем совместить реальные операции ввода-вывода одного задания с выполнением другого задания. Теперь мы можем определить это понятие более точно. Под словом spool мы подразумеваем буфер, содержащий входные или выходные данные для устройства, на котором следует избегать чередования его использования различными процессами (см. лекцию 5). Правда, в современных вычислительных системах spool для ввода данных практически не используется, а в основном предназначен для накопления выходной информации.
Рассмотрим в качестве внешнего устройства принтер. Хотя принтер не может печатать информацию, поступающую одновременно от нескольких процессов, может оказаться желательным разрешить процессам совершать вывод на принтер параллельно. Для этого операционная система вместо передачи информации напрямую на принтер накапливает выводимые данные в буферах на диске, организованных в виде отдельного spool-файла для каждого процесса. После завершения некоторого процесса соответствующий ему spool-файл ставится в очередь для реальной печати. Механизм, обеспечивающий подобные действия, и получил название spooling.
В некоторых операционных системах вместо использования spooling для устранения race condition применяется механизм монопольного захвата устройств процессами. Если устройство свободно, то один из процессов может получить его в монопольное распоряжение. При этом все другие процессы при попытке осуществления операций над этим устройством будут либо блокированы (переведены в состояние ожидание), либо получат информацию о невозможности выполнения операции до тех пор, пока процесс, захвативший устройство, не завершится или явно не сообщит операционной системе о своем отказе от его использования.
Обеспечение spooling и механизма захвата устройств является прерогативой базовой подсистемы ввода-вывода.
13.13. Обработка прерываний и ошибок
Если при работе с внешним устройством вычислительная система не пользуется методом опроса его состояния, а задействует механизм прерываний, то при возникновении прерывания, как мы уже говорили раньше, процессор, частично сохранив свое состояние, передает управление специальной программе обработки прерывания. Мы уже рассматривали действия операционной системы над процессами, происходящими при возникновении прерывания, в разделе "Переключение контекста" лекции 2, где после возникновения прерывания осуществлялись следующие действия: сохранение контекста, обработка прерывания, планирование использования процессора, восстановление контекста. Тогда мы обращали больше внимания на действия, связанные с сохранением и восстановлением контекста и планированием использования процессора. Теперь давайте подробнее остановимся на том, что скрывается за словами "обработка прерывания".
Одна и та же процедура обработки прерывания может применяться для нескольких устройств ввода-вывода (например, если эти устройства используют одну линию прерываний, идущую от них к контроллеру прерываний), поэтому первое действие собственно программы обработки состоит в определении того, какое именно устройство выдало прерывание. Зная устройство, мы можем выявить процесс, который инициировал выполнение соответствующей операции. Поскольку прерывание возникает как при удачном, так и при неудачном ее выполнении, следующее, что мы должны сделать, – это определить успешность завершения операции, проверив значение бита ошибки в регистре состояния устройства. В некоторых случаях операционная система может предпринять определенные действия, направленные на компенсацию возникшей ошибки. Например, в случае возникновения ошибки чтения с гибкого диска можно попробовать несколько раз повторить выполнение команды. Если компенсация ошибки невозможна, то операционная система впоследствии известит об этом процесс, запросивший выполнение операции, (например, специальным кодом возврата из системного вызова). Если этот процесс был заблокирован до выполнения завершившейся операции, то операционная система переводит его в состояние готовность. При наличии других неудовлетворенных запросов к освободившемуся устройству операционная система может инициировать выполнение следующего запроса, одновременно известив устройство, что прерывание обработано. На этом, собственно, обработка прерывания заканчивается, и система может приступать к планированию использования процессора.
Действия по обработке прерывания и компенсации возникающих ошибок могут быть частично переложены на плечи соответствующего драйвера. Для этого в состав интерфейса между драйвером и базовой подсистемой ввода-вывода добавляют еще одну функцию - функцию обработки прерывания intr.
13.14. Планирование запросов
При использовании неблокирующегося системного вызова может оказаться, что нужное устройство уже занято выполнением некоторых операций. В этом случае неблокирующийся вызов может немедленно вернуться, не выполнив запрошенных команд. При организации запроса на совершение операций ввода-вывода с помощью блокирующегося или асинхронного вызова занятость устройства приводит к необходимости постановки запроса в очередь к данному устройству. В результате с каждым устройством оказывается связан список неудовлетворенных запросов процессов, находящихся в состоянии ожидания, и запросов, выполняющихся в асинхронном режиме. Состояние ожидание расщепляется на набор очередей процессов, дожидающихся различных устройств ввода-вывода (или ожидающих изменения состояний различных объектов - семафоров, очередей сообщений, условных переменных в мониторах и т.д. - см. лекцию 6).
После завершения выполнения текущего запроса операционная система (по ходу обработки возникшего прерывания) должна решить, какой из запросов в списке должен быть удовлетворен следующим, и инициировать его исполнение. Точно так же, как для выбора очередного процесса на исполнение из списка готовых нам приходилось осуществлять краткосрочное планирование процессов, здесь нам необходимо осуществлять планирование применения устройств, пользуясь каким-либо алгоритмом этого планирования. Критерии и цели такого планирования мало отличаются от критериев и целей планирования процессов.
Задача планирования использования устройства обычно возлагается на базовую подсистему ввода-вывода, однако для некоторых устройств лучшие алгоритмы планирования могут быть тесно связаны с деталями их внутреннего функционирования. В таких случаях операция планирования переносится внутрь драйвера соответствующего устройства, так как эти детали скрыты от базовой подсистемы. Для этого в интерфейс драйвера добавляется еще одна специальная функция, которая осуществляет выбор очередного запроса, - функция strategy.
В следующем разделе мы рассмотрим некоторые алгоритмы планирования, связанные с удовлетворением запросов, на примере жесткого диска.
13.15. Алгоритмы планирования запросов к жесткому диску
Прежде чем приступить к непосредственному изложению самих алгоритмов, давайте вспомним внутреннее устройство жесткого диска и определим, какие параметры запросов мы можем использовать для планирования.
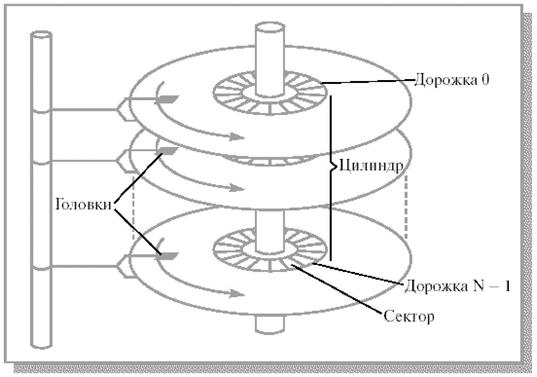
Строение жесткого диска и параметры планирования.Современный жесткий магнитный диск представляет собой набор круглых пластин, находящихся на одной оси и покрытых с одной или двух сторон специальным магнитным слоем (рис. 13.2).
Рис. 13.2. Схема жесткого диска
Около каждой рабочей поверхности каждой пластины расположены магнитные головки для чтения и записи информации. Эти головки присоединены к специальному рычагу, который может перемещать весь блок головок над поверхностями пластин как единое целое. Поверхности пластин разделены на концентрические кольца, внутри которых, собственно, и может храниться информация. Набор концентрических колец на всех пластинах для одного положения головок (т.е. все кольца, равноудаленные от оси) образует цилиндр. Каждое кольцо внутри цилиндра получило название дорожки (по одной или две дорожки на каждую пластину). Все дорожки делятся на равное число секторов. Количество дорожек, цилиндров и секторов может варьироваться от одного жесткого диска к другому в достаточно широких пределах. Как правило, сектор является минимальным объемом информации, которая может быть прочитана с диска за один раз.
При работе диска набор пластин вращается вокруг своей оси с высокой скоростью, подставляя по очереди под головки соответствующих дорожек все их сектора. Номер сектора, номер дорожки и номер цилиндра однозначно определяют положение данных на жестком диске и, наряду с типом совершаемой операции – чтение или запись, полностью характеризуют часть запроса, связанную с устройством, при обмене информацией в объеме одного сектора.
При планировании использования жесткого диска естественным параметром планирования является время, которое потребуется для выполнения очередного запроса. Время, необходимое для чтения или записи определенного сектора на определенной дорожке определенного цилиндра, можно разделить на две составляющие:
- время обмена информацией между магнитной головкой и компьютером, которое обычно не зависит от положения данных и определяется скоростью их передачи (transfer speed),
- время, необходимое для позиционирования головки над заданным сектором, – время позиционирования (positioning time). Время позиционирования, в свою очередь, состоит из времени, необходимого для перемещения головок на нужный цилиндр, – времени поиска (seek time) и времени, которое требуется для того, чтобы нужный сектор довернулся под головку, – задержки на вращение (rotational latency). Времена поиска пропорциональны разнице между номерами цилиндров предыдущего и планируемого запросов, и их легко сравнивать. Задержка на вращение определяется довольно сложными соотношениями между номерами цилиндров и секторов предыдущего и планируемого запросов и скоростями вращения диска и перемещения головок. Без знания соотношения этих скоростей сравнение становится невозможным. Поэтому естественно, что набор параметров планирования сокращается до времени поиска различных запросов, определяемого текущим положением головки и номерами требуемых цилиндров, а разницей в задержках на вращение пренебрегают.
Алгоритм First Come First Served (FCFS).Простейшим алгоритмом, к которому мы уже должны были привыкнуть, является алгоритм First Come First Served (FCFS) – первым пришел, первым обслужен. Все запросы организуются в очередь FIFO и обслуживаются в порядке поступления. Алгоритм прост в реализации, но может приводить к достаточно длительному общему времени обслуживания запросов.
Алгоритм Short Seek Time First (SSTF).Как мы убедились, достаточно разумным является первоочередное обслуживание запросов, данные для которых лежат рядом с текущей позицией головок, а уж затем далеко отстоящих. Алгоритм Short Seek Time First (SSTF) – короткое время поиска первым – как раз и исходит из этой позиции. Для очередного обслуживания будем выбирать запрос, данные для которого лежат наиболее близко к текущему положению магнитных головок. Естественно, что при наличии равноудаленных запросов решение о выборе между ними может приниматься исходя из различных соображений, например по алгоритму FCFS. Заметим, что наш алгоритм похож на алгоритм SJF планирования процессов, если за аналог оценки времени очередного CPU burst процесса выбирать расстояние между текущим положением головки и положением, необходимым для удовлетворения запроса. И точно так же, как алгоритм SJF, он может приводить к длительному откладыванию выполнения какого-либо запроса. Необходимо вспомнить, что запросы в очереди могут появляться в любой момент времени. Если у нас все запросы, кроме одного, постоянно группируются в области с большими номерами цилиндров, то этот один запрос может находиться в очереди неопределенно долго.
Точный алгоритм SJF являлся оптимальным для заданного набора процессов с заданными временами CPU burst. Очевидно, что алгоритм SSTF не является оптимальным. Это приводит нас к идее целого семейства других алгоритмов – алгоритмов сканирования.
Алгоритмы сканирования.В простейшем из алгоритмов сканирования – SCAN – головки постоянно перемещаются от одного края диска до другого, по ходу дела обслуживая все встречающиеся запросы. По достижении другого края направление движения меняется, и все повторяется снова. Существуют и другие разновидности алгоритмов сканирования.
13.17. Выводы по лекции 13
Функционирование любой вычислительной системы обычно сводится к выполнению двух видов работы: обработка информации и операции по осуществлению ее ввода-вывода. С точки зрения операционной системы "обработкой информации" являются только операции, совершаемые процессором над данными, находящимися в памяти на уровне иерархии не ниже чем оперативная память. Все остальное относится к "операциям ввода-вывода", т.е. к обмену информацией с внешними устройствами.
Несмотря на все многообразие устройств ввода-вывода, управление их работой и обмен информацией с ними строятся на относительно небольшом количестве принципов. Основными физическими принципами построения системы ввода-вывода являются следующие: возможность использования различных адресных пространств для памяти и устройств ввода-вывода; подключение устройств к системе через порты ввода-вывода, отображаемые в одно из адресных пространств; существование механизма прерывания для извещения процессора о завершении операций ввода-вывода; наличие механизма прямого доступа устройств к памяти, минуя процессор.
Механизм, подобный механизму прерываний, может использоваться также и для обработки исключений и программных прерываний, однако это целиком лежит на совести разработчиков вычислительных систем.
Для построения программной части системы ввода-вывода характерен "слоеный" подход. Для непосредственного взаимодействия с hardware используются драйверы устройств, скрывающие от остальной части операционной системы все особенности их функционирования. Драйверы устройств через жестко определенный интерфейс связаны с базовой подсистемой ввода-вывода, в обязанности которой входят: организация работы блокирующихся, неблокирующихся и асинхронных системных вызовов, буферизация и кэширование входных и выходных данных, осуществление spooling и монопольного захвата внешних устройств, обработка ошибок и прерываний, возникающих при операциях ввода-вывода, планирование последовательности запросов на выполнение этих операций. Доступ к базовой подсистеме ввода-вывода осуществляется посредством системных вызовов.
Часть функций базовой подсистемы может быть делегирована драйверам устройств и самим устройствам ввода-вывода.
ЛЕКЦИЯ 14. СЕТИ И СЕТЕВЫЕ ОПЕРАЦИОННЫЕ СИСТЕМЫ
До сих пор в лекциях данного курса мы ограничивались рамками классических операционных систем, т. е. операционных систем, функционирующих на автономных однопроцессорных вычислительных машинах, которые к середине 80-х годов прошлого века составляли основу мирового парка вычислительной техники. Подчиняясь критериям повышения эффективности и удобства использования, вычислительные системы с этого времени, о чем мы уже упоминали в самой первой лекции, начинают бурно развиваться в двух направлениях: создание многопроцессорных компьютеров и объединение автономных систем в вычислительные сети.
Появление многопроцессорных компьютеров не оказывает существенного влияния на работу операционных систем. В многопроцессорной вычислительной системе изменяется содержание состояния исполнение. В этом состоянии может находиться не один процесс, а несколько – по числу процессоров. Соответственно изменяются и алгоритмы планирования. Наличие нескольких исполняющихся процессов требует более аккуратной реализации взаимоисключений при работе ядра. Но все эти изменения не являются изменениями идеологическими, не носят принципиального характера. Принципиальные изменения в многопроцессорных вычислительных комплексах затрагивают алгоритмический уровень, требуя разработки алгоритмов распараллеливания решения задач. Поскольку с точки зрения нашего курса многопроцессорные системы не внесли в развитие операционных систем что-либо принципиально новое, мы их рассматривать далее не будем.
По-другому обстоит дело с вычислительными сетями.
14.1. Для чего компьютеры объединяют в сети
Для чего вообще потребовалось объединять компьютеры в сети? Что привело к появлению сетей?
- Одной из главных причин стала необходимость совместного использования ресурсов (как физических, так и информационных). Если в организации имеется несколько компьютеров и эпизодически возникает потребность в печати какого-нибудь текста, то не имеет смысла покупать принтер для каждого компьютера. Гораздо выгоднее иметь один сетевой принтер для всех вычислительных машин. Аналогичная ситуация может возникать и с файлами данных. Зачем держать одинаковые файлы данных на всех компьютерах, поддерживая их когерентность, если можно хранить файл на одной машине, обеспечив к нему сетевой доступ со всех остальных?
- Второй причиной следует считать возможность ускорения вычислений. Здесь сетевые объединения машин успешно конкурируют с многопроцессорными вычислительными комплексами. Многопроцессорные системы, не затрагивая по существу строение операционных систем, требуют достаточно серьезных изменений на уровне hardware, что очень сильно повышает их стоимость. Во многих случаях можно добиться требуемой скорости вычислений параллельного алгоритма, используя не несколько процессоров внутри одного вычислительного комплекса, а несколько отдельных компьютеров, объединенных в сеть. Такие сетевые вычислительные кластеры часто имеют преимущество перед многопроцессорными комплексами в соотношении эффективность/стоимость.
- Следующая причина связана с повышением надежности работы вычислительной техники. В системах, где отказ может вызвать катастрофические последствия (атомная энергетика, космонавтика, авиация и т.д.), несколько вычислительных комплексов устанавливаются в связи, дублируя друг друга. При выходе из строя основного комплекса его работу немедленно продолжает дублирующий.
- Наконец, последней по времени появления причиной (но для многих основной по важности) стала возможность применения вычислительных сетей для общения пользователей. Электронные письма практически заменили письма обычные, а использование вычислительной техники для организации электронных или телефонных разговоров уверенно вытесняет обычную телефонную связь.
14.2. Сетевые и распределенные операционные системы
В первой лекции мы говорили, что существует два основных подхода к организации операционных систем для вычислительных комплексов, связанных в сеть, – это сетевые и распределенные операционные системы. Необходимо отметить, что терминология в этой области еще не устоялась. В одних работах все операционные системы, обеспечивающие функционирование компьютеров в сети, называются распределенными, а в других, наоборот, сетевыми. Мы придерживаемся той точки зрения, что сетевые и распределенные системы являются принципиально различными.
В сетевых операционных системах для того, чтобы задействовать ресурсы другого сетевого компьютера, пользователи должны знать о его наличии и уметь это сделать. Каждая машина в сети работает под управлением своей локальной операционной системы, отличающейся от операционной системы автономного компьютера наличием дополнительных сетевых средств (программной поддержкой для сетевых интерфейсных устройств и доступа к удаленным ресурсам), но эти дополнения существенно не меняют структуру операционной системы.
Распределенная система, напротив, внешне выглядит как обычная автономная система. Пользователь не знает и не должен знать, где его файлы хранятся, на локальной или удаленной машине, и где его программы выполняются. Он может вообще не знать, подключен ли его компьютер к сети. Внутреннее строение распределенной операционной системы имеет существенные отличия от автономных систем.
Изучение строения распределенных операционных систем не входит в задачи нашего курса. Этому вопросу посвящены другие учебные курсы – Advanced operating systems, как называют их в англоязычных странах, или "Современные операционные системы", как принято называть их в России.
В этой лекции мы затронем вопросы, связанные с сетевыми операционными системами, а именно какие изменения необходимо внести в классическую операционную систему для объединения компьютеров в сеть.
14.3. Взаимодействие удаленных процессов как основа работы вычислительных сетей
Все перечисленные выше цели объединения компьютеров в вычислительные сети не могут быть достигнуты без организации взаимодействия процессов на различных вычислительных системах. Будь то доступ к разделяемым ресурсам или общение пользователей через сеть – в основе всего этого лежит взаимодействие удаленных процессов, т.е. процессов, которые находятся под управлением физически разных операционных систем. Поэтому мы в своей работе сосредоточимся именно на вопросах кооперации таких процессов, в первую очередь, выделив ее отличия от кооперации процессов в одной автономной вычислительной системе (кооперации локальных процессов), о которой мы говорили в лекциях 4, 5 и 6.
1. Изучая взаимодействие локальных процессов, мы разделили средства обмена информацией по объему передаваемых между ними данных и возможности влияния на поведение другого процесса на три категории: сигнальные, канальные и разделяемая память. На самом деле во всей этой систематизации присутствовала некоторая доля лукавства. Мы фактически классифицировали средства связи по виду интерфейса обращения к ним, в то время как реальной физической основой для всех средств связи в том или ином виде являлось разделение памяти. Семафоры представляют собой просто целочисленные переменные, лежащие в разделяемой памяти, к которым посредством системных вызовов, определяющих состав и содержание допустимых операций над ними, могут обращаться различные процессы. Очереди сообщений и pip'ы базируются на буферах ядра операционной системы, которые опять-таки с помощью системных вызовов доступны различным процессам. Иного способа реально передать информацию от процесса к процессу в автономной вычислительной системе просто не существует. Взаимодействие удаленных процессов принципиально отличается от ранее рассмотренных случаев. Общей памяти у различных компьютеров физически нет. Удаленные процессы могут обмениваться информацией, только передавая друг другу пакеты данных определенного формата (в виде последовательностей электрических или электромагнитных сигналов, включая световые) через некоторый физический канал связи или несколько таких каналов, соединяющих компьютеры. Поэтому в основе всех средств взаимодействия удаленных процессов лежит передача структурированных пакетов информации или сообщений.
2. При взаимодействии локальных процессов и процесс–отправитель информации, и процесс-получатель функционируют под управлением одной и той же операционной системы. Эта же операционная система поддерживает и функционирование промежуточных накопителей данных при использовании непрямой адресации. Для организации взаимодействия процессы пользуются одними и теми же системными вызовами, присущими данной операционной системе, с одинаковыми интерфейсами. Более того, в автономной операционной системе передача информации от одного процесса к другому, независимо от используемого способа адресации, как правило (за исключением микроядерных операционных систем), происходит напрямую – без участия других процессов-посредников. Но даже и при наличии процессов-посредников все участники передачи информации находятся под управлением одной и той же операционной системы. При организации сети, конечно, можно обеспечить прямую связь между всеми вычислительными комплексами, соединив каждый из них со всеми остальными посредством прямых физических линий связи или подключив все комплексы к общей шине (по примеру шин данных и адреса в компьютере). Однако такая сетевая топология не всегда возможна по ряду физических и финансовых причин. Поэтому во многих случаях информация между удаленными процессами в сети передается не напрямую, а через ряд процессов-посредников, "обитающих" на вычислительных комплексах, не являющихся компьютерами отправителя и получателя и работающих под управлением собственных операционных систем. Однако и при отсутствии процессов-посредников удаленные процесс-отправитель и процесс-получатель функционируют под управлением различных операционных систем, часто имеющих принципиально разное строение.
3. Вопросы надежности средств связи и способы ее реализации, рассмотренные нами в лекции 4, носили для случая локальных процессов скорее теоретический характер. Мы выяснили, что физической основой "общения" процессов на автономной вычислительной машине является разделяемая память. Поэтому для локальных процессов надежность передачи информации определяется надежностью ее передачи по шине данных и хранения в памяти машины, а также корректностью работы операционной системы. Для хороших вычислительных комплексов и операционных систем мы могли забыть про возможную ненадежность средств связи. Для удаленных процессов вопросы, связанные с надежностью передачи данных, становятся куда более значимыми. Протяженные сетевые линии связи подвержены разнообразным физическим воздействиям, приводящим к искажению передаваемых по ним физических сигналов (помехи в эфире) или к полному отказу линий (мыши съели кабель). Даже при отсутствии внешних помех передаваемый сигнал затухает по мере удаления от точки отправления, приближаясь по интенсивности к внутренним шумам линий связи. Промежуточные вычислительные комплексы сети, участвующие в доставке информации, не застрахованы от повреждений или внезапной перезагрузки операционной системы. Поэтому вычислительные сети должны организовываться исходя из предпосылок ненадежности доставки физических пакетов информации.