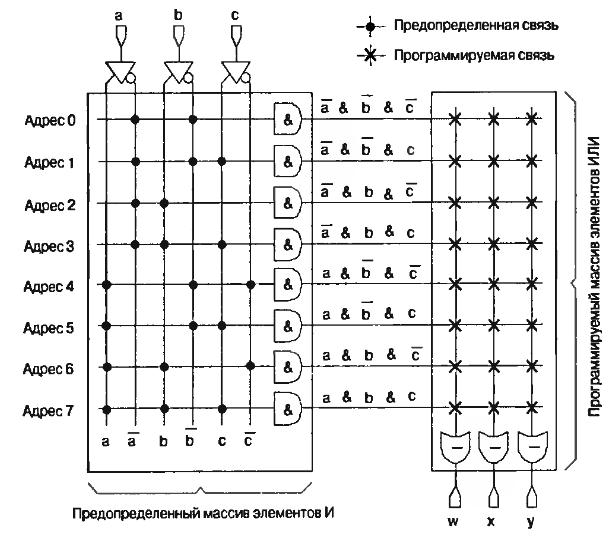
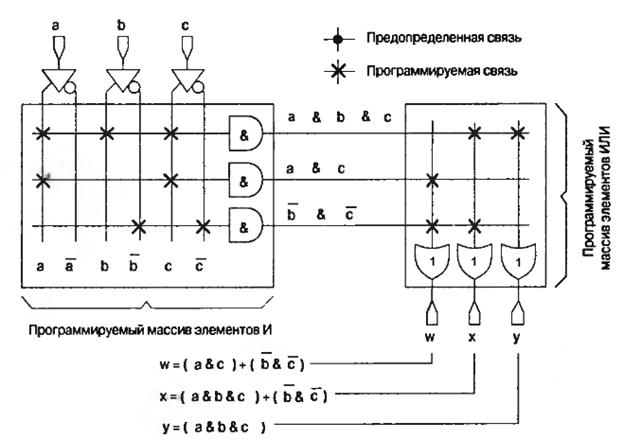
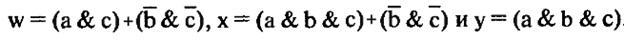Первыми представителями простых ПЛУ были ППЗУ-микросхемы, которые появились в 1970 году. Они состоят из фиксированного массива логических функций И, подсоединённого к программируемому массиву логических функций ИЛИ. Для примера на рис. 6.9 приведено ППЗУ с тремя входами и тремя выходами.
В качестве программируемых связей в масстве элементов ИЛИ могут применяться плавкие перемычки, либо СППЗУ-транзисторы или ячейки ЭСППЗУ. На рис рис.6.9 ППЗУ представлена условно для понимания принципа действия. В действительности каждая функция И имеет три входа, которые соединены к прямым или инверсным входам a, b или c устройства. Аналогично, каждая функция ИЛИ программируемого массива имеет восемь входов, которые подсоединены к выходам массива функций И.
Рис.6.9. Незапрограммированная схема ППЗУ
ППЗУ с тремя входами и тремя выходами может использоваться для синтеза любой комбинационной функции с не более, чем тремя входными и тремя выходными параметрами. Для примера на рис.6.10 приведен небольшой логический блок и его таблица истинности.
Рис.6.10. Небольшой блок комбинационной логики
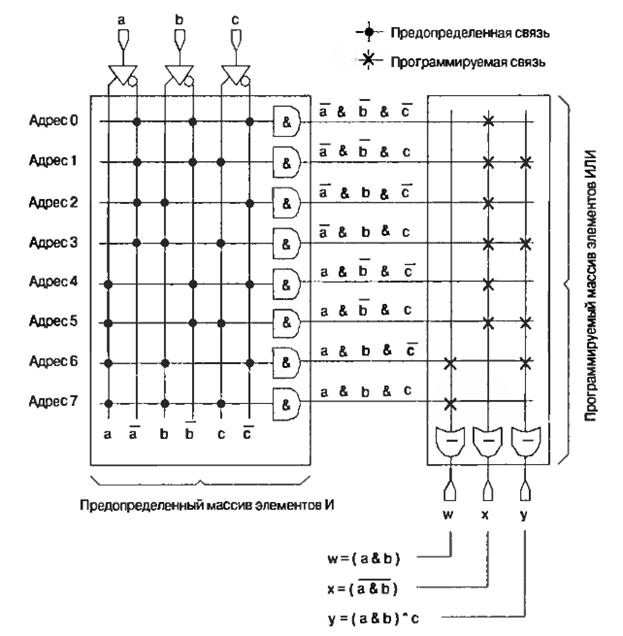
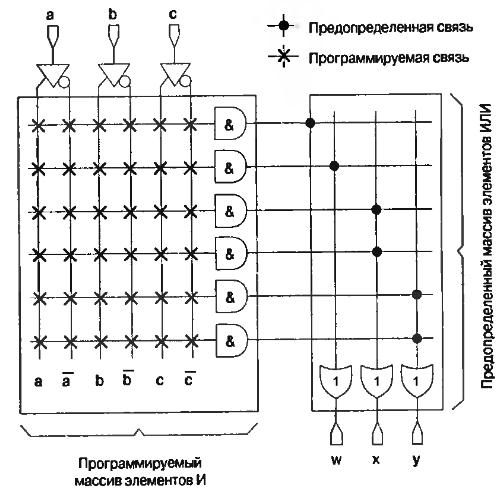
Логический блок ( рис.6.10) может быть заменен микросхемой ППЗУ с тремя входами и тремя выходами. Для этого надо всего лишь запрограммировать соответствующие связи в массиве логических элементов ИЛИ ( рис.6.11).
Рис.6.11. Запрограммированное ППЗУ
Рассмотренная выше микросхема ППЗУ является очень простой. В действительности микросхемы ППЗУ имеют значительно больше входов и выходов и могут использоваться для реализации больших блоков комбинационной логики. При этом одна ППЗУ может заменить большое количество микросхем простейшей логики. Это означает, что печатную плату можно сделать меньше, проще, дешевле и менее подверженной сбоям. Кроме того, если в этой части схемы обнаружится логическая ошибка, то она может быть легко исправлена путём прошивки новой ППЗУ-микросхемы.
6.2.2 Программируемые логические матрицы
Следующая ступень развития ПЛУ – решение проблем, связанных с ограничениями, свойственными архитектуре ППЗУ. Первые программируемые логические матрицы (ПЛМ) появились примерно в в 1975 году. В них были программируемы как массив функций ИЛИ, так и массив функций И. В отличие от ППЗУ, количество функций И в одноимённом массиве не зависит от количества входов матрицы. Аналогично, количество функций ИЛИ в одноимённом массиве не зависит от количества входов матрицы и от размера массива функций И.
Для примера на рис.6.12 приведена незапрограммированная ПЛМ на три входа и три выхода, а на рис.6.13 показана запрограммированная ПЛМ, реализующая следующие три уравнения :
Рис.6.12. Незапрограммированная ПЛМ
Наряду с преимуществами, которые имеют ПЛМ по сравнению с ППЗУ, у них есть и недостатки. Сигналам для прохождения через программируемые связи требуется больше времени, чем через предопределённые аналоги. Поэтому ПЛМ работает медленнее, чем ППЗУ, так как оба массива и функций И и функций ИЛИ являются программируемыми.
Рис.6.13. Запрограммированная ПЛМ
6.2.3. Программируемые матрицы PAL и GAL
Для того, чтобы решить проблему быстродействия, свойственную ПЛМ, в конце 1970-х появился новый класс устройств, называемый программируемый массив логики (ПМЛ или PAL – Programmable Array Logic). В отличие от ППЗУ они состоят из программируемого массива логических функций И и предопределённого массива функций ИЛИ. Устройства GAL ( Generic Array Logic – изменяемый массив логики), разработанные в 1983 году компанией Lattice Semiconductor Corporation, представляют собой более сложные электрически стираемые КМОП-разновидности идеологии PAL.
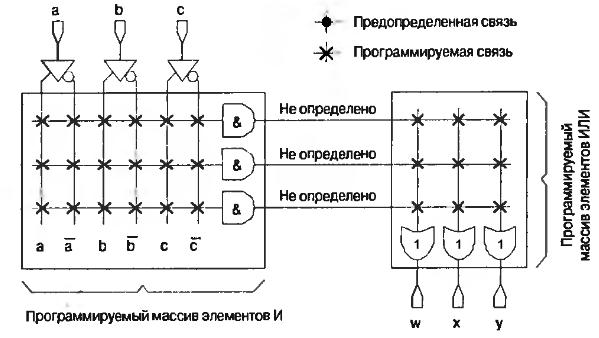
В качестве примера на рис.6.14 приведено простое PAL-устройство с тремя входами и тремя выходами. Преимуществом микросхем PAL по сравнению с ПЛМ является более высокое быстродействие, так как из двух массивов у них только один является программируемым.
Рис.6.14. Незапрограммированное устройство PAL
6.2.4 Дополнительные программируемые опции
В отличие от рассмотренных выше примеров микросхем ПЛМ и PAL, промышленность выпускает очень большие ПЛМ и PAL с множеством входов, выходов и с внутренними сигналами. В них могут быть предусмотрены дополнительные программируемые опции, такие, как возможность инвертировать выходы, либо иметь выходы с тремя состояниями, либо и то и другое. Кроме того, некоторые из них поддерживают регистровые выходы и позволят пользователю выбрать версию выхода – регистровую или нерегистровую. Некоторые устройства позволяют конфигурировать определённые выводы в качестве либо выходов, либо дополнительных входов. Этим списком не ограничивается список дополнительных опций, который постоянно пополняется разными производителями.
6.2.5 Сложные ПЛУ
В начале 1980-х были разработаны более сложные программируемые логические устройства, так называемые сложные ПЛУ (CPLD – complex PLD). Они отличались от простых ПЛУ большей функциональностью, меньшими физическими размерами, более высоким быстродействием и меньшей стоимостью.
Существенный технологический прорыв в этом направлении совершила компания Altera, которая представила сложное ПЛУ, основанное на сочетании КМОП- и СППЗУ-технологий., и в котором использовался центральный коммутационный массив с количеством соединений с входами/выходами блоков менее 100%. Это осложнило программное обеспечение для проектирования ПЛУ, но позволило существенно увеличить быстродействие и значительно снизить потребляемую мощность и стоимость этих устройств.
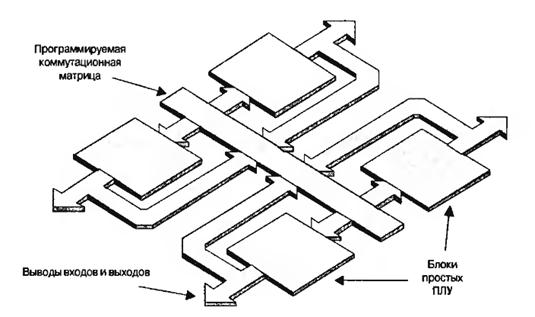
Несмотря на то, что каждый производитель сложных ПЛУ реализовывал свои уникальные технологии, в общем случае устройство состояло из нескольких блоков простыл ПЛУ, обычно PAL, объединённых общей программируемой коммутационной матрицей ( рис.6.15). Помимо отдельных блоков простых ПЛУ можно было также запрограммировать соединения между ними с помощью программируемой коммутационной матрицы.
Рис.6.15. Общая структура сложного ПЛУ
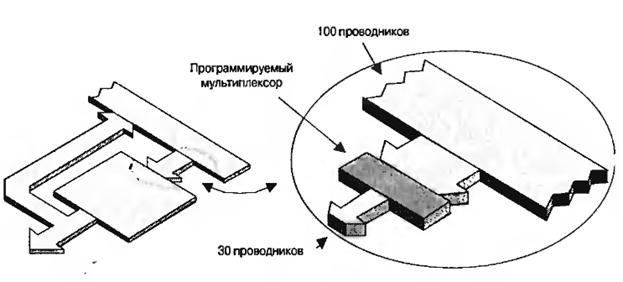
На рис.6.15 не показаны различные дополнительные компоненты и он даёт лишь поверхностное представление о работе сложного ПЛУ. Все структуры сформированы на одном кристалле кремния. Например, программируемая коммутационная матрица может содержать большое количество проводников, скажем 100. Но это больше, чем может быть подключено к блоку простого ПЛУ, который способен работать только с ограниченным количеством сигналов, скажем 30. Блоки простых ПЛУ связаны с коммутационной матрицей своего рода программируемыми мультиплексорами ( рис.6.16).
Рис.6.16. Использование программируемых мультиплексоров
В зависимости от производителя и от типа устройства программируемые переключатели сложных ПЛУ могут быть выполнены на ячейках памяти типа СППЗУ, ЭСППЗУ, Flash или на статическом ОЗУ. При использовании статического ОЗУ появляется возможность увеличить универсальность этой памяти, используя её в качестве программируемых переключателей и в качестве фактической оперативной памяти.
6.3. Контрольные вопросы
1. Дайте пример простой программируемой функции.
2. Опишите метод плавких перемычек.
3. Опишите метод наращиваемых перемычек.
4. Принцип программирования устройств фотошаблоном.
5. Опишите ячейку памяти на основе СППЗУ-транзистора.
6. Нарисуйте примеры незапрограммированной и запрограммированной схем ППЗУ.
7. Нарисуйте примеры незапрограммированной и запрограммированной схем ПЛМ.
FPGA ( field programmable gate arrays) или ПЛИС (программируемые логические интегральные схемы) представляют собой цифровые интегральные микросхемы (ИС), состоящие из программируемых логических блоков и программируемых соединений между этими блоками.
В зависимости от способа изготовления ПЛИС могут программироваться либо один раз, либо многократно. Устройства,которые могут программироваться только один раз, называются однократно программируемыми.
Словосочетание ”field programmable”, содержащееся в расшифровке аббревиатуры FPGA, означает, что программирование FPGA-устройств выполняется на месте, ”в полевых условиях”, в отличие от устройств, внутренняя функциональность которых жёстко прописана производителем. Более того, речь может идти и о возможности модификации функций устройства, встроенного в электронную схему, которая уже как-то используется. Если устройство может быть запрограммировано, оставаясь в составе системы более высокого уровня, оно называется внутрисистемно программируемым.
В настоящее время ПЛИС заполняют четыре крупных сегмента рынка : заказные интегральные схемы, цифровая обработка сигналов, системы на основе встраиваемых микроконтроллеров и микросхемы, обеспечивающие физический уровень передачи данных. Кроме того, с появлением ПЛИС возник новый сектор рынка – системы с перестраиваемой архитектурой, или reconfigurable computing (RC).
Заказные интегральные схемы.Современные ПЛИС используются для создания устройств такого уровня, который до этого могли обеспечить только заказные микросхемы.
Цифровая обработка сигналов.Высокоскоростная цифровая обработка традиционно производилась с помощью специально разработанных микропроцессоров, называемых цифровые сигнальные процессоры (ЦСП) или digital sinal processors (DSP). Однако современные ПЛИС содержат встроенные умножители, схемы арифметического переноса и большой объём оперативной памяти внутри кристалла. Всё это в сочетании с высокой степенью параллелизма ПЛИС обеспечивает превосходство ПЛИС над самыми быстрыми сигнальными процессорами в 500 и более раз.
Встраиваемые микроконтроллеры. Несложные задачи управления обычно выполняются встраиваемыми процессорами специального назначения, которые называются микроконтроллерами. Эти недорогие устройства содержат встроенную программу, память команд, таймеры, интерфейсы ввода/вывода, расположенные рядом с ядром на одном кристалле. Цены на ПЛИС падают, к тому же, даже самые простые из них можно использовать для реализации программного микропроцессорного ядра с необходимыми функциями ввода/вывода. В результате ПЛИС становятся всё более привлекательными устройствами для реализации функций микроконтроллеров.
Физический уровень передачи данных. ПЛИС уже давно используются в качестве связующей логики, выполняющей функцию интерфейса между микросхемами, реализующими физический уровень передачи данных, и высшими уровнями сетевых протоколов. Тот факт, что современные ПЛИС могут содержать множество высокоскоростных передатчиков, означает, что сетевые и коммуникационные функции могут быть реализованы в одном устройстве.
Системы с перестраиваемой архитектурой. Можно использовать “аппаратное ускорение” программных алгоритмов, основываясь на таких свойствах программируемых логических интегральных схем (ПЛИС), как параллелизм и перенастраиваемость. В настоящее время различные компании заняты созданием огромных перенастраиваемых вычислительных машин на основе ПЛИС. Такие системы могут использоваться для выполнения широкого спектра задач – от моделирования аппаратуры до криптографического анализа или создания новых лекарств.
7.1 Мелко-, средне- и крупномодульные архитектуры
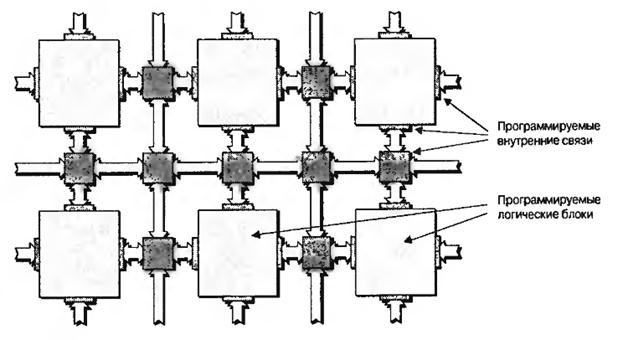
Главной особенностью ПЛИС является их внутренняя структура, которая преимущественно состоит из большого количества простых программируемых логических блоков-”островов” в ”море” программируемых внутренних связей ( рис.7.1).
В мелкомодульной архитектуре каждый логический блок может использоваться для реализации только очень простой функции. Например, блок можно сконфигурировать для работы в качестве 3-входового простого логического элемента ( И, ИЛИ, И-НЕ и так далее) или элемента памяти (триггер D-типа, защёлка D-типа и так далее).
Мелкомодульные структуры используются при реализации связующей логики и неоднородных структур, подобных конечным автоматам. Мелкомодульные структуры также эффективны при реализации систолических алгоритмов ( функции, которые чрезвычайно эффективны за счёт реализации массового параллелизма). Эти структуры обладают определённым преимуществом при использовании технологии традиционного логического синтеза, которая базируется на мелкомодульной архитектуре заказных микросхем.
Рис.7.1. Внутренняя структура ПЛИС
Для ”мелкомодульных” ПЛИС характерно большое количество соединений внутри блоков и между ними. По мере увеличения модульности устройств до среднемодульных и выше количество соединений в блоках уменьшается. Это важное свойство, так как внутренние связи определяют величину подавляющего большинства задержек, связанных с прохождением сигналов через ПЛИС.
В “среднемодульных” ПЛИС каждый логический блок содержит относительно большое количество логики по сравнению с “мелкомодульными” ПЛИС. Так, например, логический блок может содержать четыре 4-входовых таблицы соответствия, четыре мультиплексора, четыре D-триггера, и некоторое количество логики быстрого переноса.
“Крупномодульные” ПЛИС содержат массивы узлов, где каждый узел представляет собой сложный элемент, реализующий алгоритмические функции, такие как, например, быстрое преобразование Фурье или ядро микропроцессора общего назначения.
7.2 Логические блоки на мультиплексорах и таблицах соответствия
Существуют два основных способа реализации программируемых логических блоков, используемых для формирования среднемодульных устройств: на основе мультиплексоров (MUX – от multiplexer) и на основе таблиц соответствия (LUT –от lookup table).
В качестве примера реализации устройств на основе мультиплексоров рассмотрим 3-входовую функцию y=(a&b)+c, реализованную с помощью блока, содержащего только мультиплексоры (рис.7.2).
Рис.7.2. Логический блок на мультиплексорах
Устройство может быть запрограммировано таким образом, что на каждый его вход может подаваться логический 0 либо логическая 1, либо прямое, либо инвесное значение входного сигнала ( в нашем случае a, b или c), приходящего с другого блока или с входа микросхемы. Такой подход позволяет для каждого блока создавать огромнейшее количество вариантов конфигурирования для выполнения разнообразных функций ( х на входе центрального мультиплексора на рис.7.2 обозначает, что на вход можно подавать любой сигнал – 0 или 1).
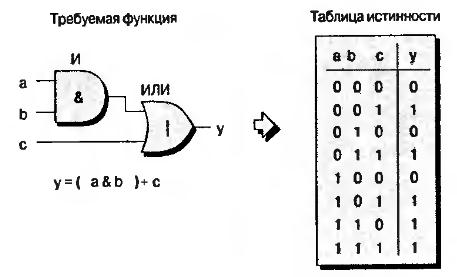
Основная концепция таблиц соответствия проста. В таких микросхемах группа входных сигналов используется в качестве индекса ( указателя, или адреса ячейки) таблицы соответствия. Содержимое этой таблицы организовано таким образом, что ячейки, указываемые каждой входной комбинацией, содержат требуемое выходное значение. Для примера на рис.7.3 приведена схема на логических элементах и её таблица истинности для функции y=(a&b)+c
Рис.7.3. Требуемая функция и её таблица истинности
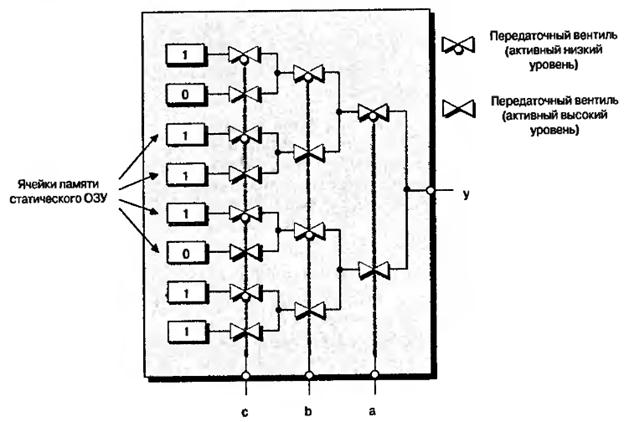
Для реализации этой функции надо загрузить 3-входовую таблицу соответствующими значениями. А теперь допустим, что таблица соответствий формируется из ячеек памяти статического ОЗУ ( она может также быть сформирована наращиваемыми перемычками, ЭСППЗУ- или Flash-ячейками памяти). Для выбора требуемой ячейки ОЗУ с помощью каскада передаточных вентилей используются входные сигналы, как показано на рис.7.4. При этом ячейки памяти статического ОЗУ для загрузки конфигурационных данных должны быть соединены в длинную цепочку, но эти цепи не показаны на рис.7.4 с целью его упрощения.
На схеме открытый, или активный, передаточный вентиль пропускает сигнал с входа на выход. Закрытый вентиль электрически отключает свой выход от проводника, к которому он подсоединён. Передаточные вентили, на обозначениях которых изображён небольшой “кружок”, активизируются при подаче на управляющий вход логического 0. И наоборот, вентили, на обозначениях которых нет кружка, активизируются при подаче на управляющий вход уровня логической 1. Основываясь на этом, легко проследить, как различные входные комбинации могут использоваться для выбора содержимого требуемой ячейки памяти.
Рис.7.4. Таблица соответствия на основе передаточных вентилей
Архитектуры на основе мультиплексоров, в отличие от блоков на основе таблиц соответствия, не обеспечивают работу высокоскоростных цепочек логического переноса. Поэтому большинство современных архитектур ПЛИС реализовывается на основе таблиц соответствия.
Ядро таблицы соответствия в устройстве на статическом ОЗУ использует для своей работы несколько ячеек памяти. Это позволяет использовать некоторые интересные возможности. Помимо основного назначения, то есть формирования таблицы соответствия, устройства некоторых поставщиков позволяют использовать ячейки, формирующие таблицу, в качестве небольших блоков оперативной памяти. Например, 16 ячеек памяти, формирующих 4-входовую таблицу, могут выступать в роли блока ОЗУ 16•1. Такие участки памяти называются распределённым ОЗУ, так как, во-первых, таблицы соответствия разбросаны ( распределены) по всей поверхности кристалла, а во-вторых, это название отличает их от больших блоков ОЗУ.
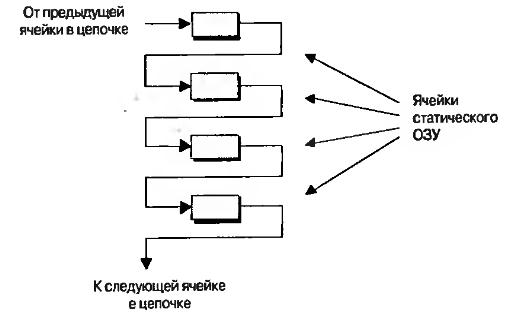
Другой вариант альтернативного использования таблиц основан на том, что все конфигурационные ячейки, включая и те, которые формируют таблицу соответствия, эффективно связаны вместе в одну длинную цепочку (рис.7.5).
Рис.7.5. Конфигурационные ячейки, связанные в цепочку
Дело в том, что в некоторых устройствах ячейки памяти, формирующие таблицу соответствия, после программирования могут рассматриваться независимо от главной структуры цепочки и использоваться в качестве сдвигового регистра. Таким образом, каждую таблицу соответствия можно рассматривать как многофункциональный компонент (рис.7.6).
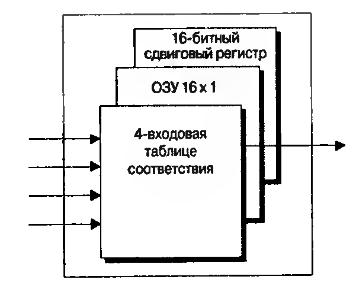
У разных производителей логические блоки могут называться по разному, что не меняет их сути. В ПЛИС фирмы Xilinx блоки называются логическими ячейками (logic cell). Кроме всего прочего, логическая ячейка содержит 4-входовую таблицу соответствия, которая может работать как ОЗУ 16•1 или как 16-битный сдвигающий регистр, а также мультиплексор и регистр (рис.7.5).
Рис.7.5. Упрощённый вид логической ячейки фирмы Xilinx
Полярность тактового сигнала ( реакция триггера на фронт или спад синхроимпульса) может задаваться программно, так же как полярность сигналов “тактовый сигнал разрешён” и “установка/сброс” ( активный высокий или низкий уровень).
Кроме таблиц соответствия, мультиплексоров и регистров, логические ячейки содержат небольшое количество других элементов, включая логику быстрого переноса для использования в арифметических действиях.
Логические блоки, из которых состоят ПЛИС компании Altera, называются логическими элементами ( logic element). Между логическими ячейками Xilinx и логическими элементами Altera существует ряд отличий, но в целом их концепции очень похожи.
7.5 Секции и логические ячейки
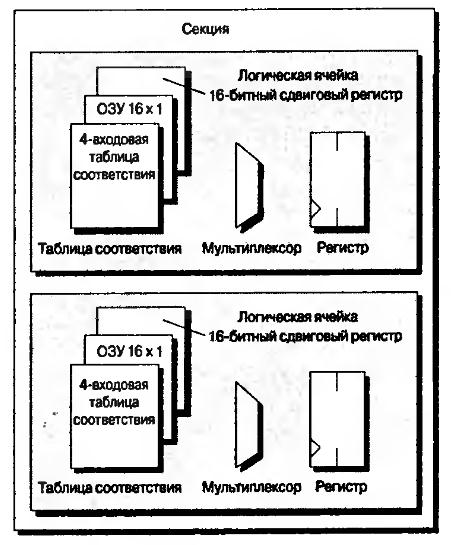
Следующей ступенью в иерархии построения микросхем программируемой логики является, так называемая по определению фирмы Xilinx, секция (slice). На рис.7.6 приведена секция из двух логических ячеек.
Рис.7.6. Секция, содержащая две логические ячейки
На рис.7.6 для упрощения не показаны внутренние связи, также необходимо заметить, что хотя таблицы соответствия, мультиплексоры и регистры каждой ячейки имеют собственные входы и выходы данных, секция имеет общие тактовые сигналы, разрешения тактовых сигналов и установки/сброса для обеих логических ячеек.
7.6 Конфигурируемые логические блоки CLB и блоки логических массивов LAB
Поднимаясь по иерархической лестнице, мы достигаем уровня, который компания Xilinx называет конфигурируемым логическим блоком КЛБ (CLB – configurable logic block). Компания Altera, в свою очередь, называет его блоком логических массивов или LAB ( logic array block). Другие поставщики ПЛИС дают им свои эквивалентные названия.
Конфигурируемые логические блоки внутри ПЛИС можно представить в виде ”островов” программируемой логики в ”море” программируемых соединений ( рис.7.7).
Рис.7.7. Часть внутренней структуры ПЛИС, содержащая четыре КЛБ, каждый из которых содержит четыре секции
Внутри КЛБ находятся быстрые программируемые внутренние соединения, которые используются для связи между соседними секциями.
Причина существования такой логико-блочной иерархии, то есть логическая ячейка → секция с несколькими ячейками → конфигурируемый логический блок с несколькими секциями, заключается в том, что она дополняется эквивалентной иерархией внутренних соединений. Другими словами, существуют быстрые внутренние соединения между логическими ячейками внутри секции, затем менее быстрые соединения между секциями в конфигурироемом логическом блоке ( КЛБ) и соединения между КЛБ. Подобная иерархия отражает пошаговое достижение оптимального компромисса между простотой соединения внутренних структур и чрезмерными задержками сигналов на внутренних соединениях.
Как уже отмечалось, каждая 4-входовая таблица соответствия может использоваться в качестве блока ОЗУ 16•1. В четырёхсекционном КЛБ, приведенном на рис.7.7, все таблицы соответствия внутри этого блока могут быть сконфигурированы для реализации следующих функций:
· Однопортовый блок ОЗУ 16•8 бит.
· Однопортовый блок ОЗУ 32•4 бит.
· Однопортовый блок ОЗУ 64•2 бит.
· Однопортовый блок ОЗУ 128•1 бит.
· Двухпортовый блок ОЗУ 16•4 бита.
· Двухпортовый блок ОЗУ 32•2 бита.
· Двухпортовый блок ОЗУ 64•1 бит.
Портом обычно называют набор сигналов управления и данных, рассматриваемых, как единое целое. В однопортовом ОЗУ данные записываются и считываются из ячейки через общую шину данных. В двухпортовом ОЗУ данные записываются и считываются через различные шины ( порты). На практике в этом случае операции чтения и записи, как правило, работают со своими адресными шинами ( используемыми для указания необходимой ячейки внутри ОЗУ), то есть операции чтения и записи в двухпортовом ОЗУ могут выполняться одновременно.
Аналогично, каждая 4-битовая таблица соответствий может использоваться в качестве 16-битного сдвигового регистра. Для этого существуют специальные соединения между логическими ячейками внутри секции и между секциями, которые позволяют соединить последний бит одного сдвигового регистра с первым битом другого регистра без привлечения к этому процессу выходных сигналов таблиц соответствия. Последние также могут использоваться для просмотра содержимого определённого бита в 16-битном регистре. Это позволяет, при необходимости, соединить вместе таблицы соответствия внутри одного КЛБ и реализовать длинный сдвиговый регистр ( для КЛБ на рис.7.7 длина регистра будет 128 бит).
7.7. Контрольные вопросы
1. Перечислите сегменты рынка, где присутствуют ПЛИС.
2. Нарисуйте обобщённый пример внутренней структуры ПЛИС.
3. Опишите логические блоки на мультиплексорах и их отличие от блоков на основе таблиц соответствия.
4. Таблица соответствия на основе передаточных вентилей.
5. Нарисуйте упрощённый вид логической ячейки фирмы Xilinx и опишите назначение всех сигналов.
Лекция 8
8.1 Дополнительные встроенные функции
8.1.1 Схемы ускоренного переноса
Ключевой особенностью современных ПЛИС является то, что они содержат специальную логику и внутренние соединения, необходимые для реализации схем ускоренного переноса. Эта логика дополняется специальными внутренними соединениями между логическими ячейками в пределах каждой секции, между секциями в рамках каждого КЛБ и между КЛБ.
Специальная логика быстрого переноса и выделенная маршрутизация способствует выполнению логических функций, таких как счётчики, сумматоры и т.п. Возможности схем ускоренного переноса совместно с возможностями других средств, аналогичных сдвиговым регистрам на основе таблиц соответствия, встроенным умножителям и другим блокам обеспечивают необходимый набор средств для использования ПЛИС в приложениях цифровой обработки сигналов (ЦОС).
8.1.2 Встроенные блоки ОЗУ
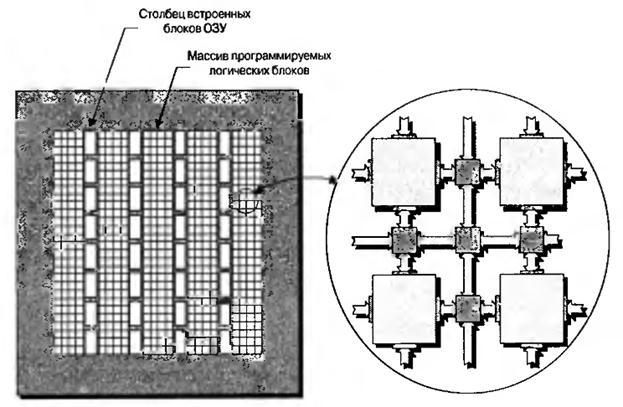
В процессе реализации большинства приложений возникает необходимость использовать ячейки памяти, поэтому современные ПЛИС содержат довольно большие блоки встроенной памяти, называемые блоками встроенного ОЗУ. В зависимости от архитектуры микросхемы эти блоки могут быть расположены по периметру кристалла, разбросаны по его поверхности и относительно изолированы друг от друга или организованы в столбцы, как показано на рис.8.1.
Рис.8.1. Вид на кристалл ПЛИС со столбцами встроенных блоков ОЗУ
В зависимости от устройства размер блоков ОЗУ может меняться от нескольких тысяч до нескольких десятков тысяч бит. Каждая микросхема может содержать от нескольких лесятков до нескольких сотен таких блоков. Таким образом, полная ёмкость простирается от нескольких сотен тысяч бит до нескольких миллионов бит.
Каждый блок ОЗУ может использоваться либо как независимое запоминающее устройство, либо находиться в связке с несколькими блоками для реализации массивов памяти большого объёма. Блоки могут использоваться для различных целей, например, как стандартные одно- и двух-портовые ОЗУ, очереди FIFO (first-in first-out – первый пришёл, первый вышел), конечные автоматы и так далее.
8.1.3 Встроенные умножители, сумматоры и блоки умножения с накоплением
Некоторые типы функций, например умножители, по своей сути являются довольно медленными, если их реализовывать с помощью большого количества программируемых логических блоков, соединённых вместе. Поскольку эти блоки используются в многочисленных приложениях, многие ПЛИС содержат специальные аппаратные блоки умножения. Эти блоки обычно расположены в непосредственной близости от блоков встроенного ОЗУ, так как они часто используются вместе (рис.8.2).
Рис.8.2. Вид на кристалл со столбцами встроенных умножителей и блоков ОЗУ
Некоторые производители ПЛИС также предлагают выделенные сумматоры. В то же время, одной из самых распространённых операций, применяемых в приложениях цифровой обработки сигналов, является умножение с накоплением (multiply-and-accumulate или MAC ), рис.8.3. Как подсказывает название, эта функция перемножает два числа и суммирует результат с текущим числом, сохранённым в аккумуляторе.