Основная цель кодирования состоит в однозначном обозначении объектов, а также в обеспечении необходимой достоверности кодируемой информации.
Коды могут быть цифровыми, буквенными, комбинированными. При обработке экономической информации часто применяют мнемокоды, штрих-коды.
В ряде случаев машина сама может кодировать заносимые в нее объекты. В этом случае используется самая простая система кодирования — порядковая. В качестве мнемокода применяется условное короткое буквенное обозначение объекта. Например, материально-ответственному лицу присваивается мнемокод «МОЛ».
Процесс присвоения объектам кодовых обозначений называется кодированием.
С помощью кодирования обеспечивается выполнение основных функций, связанных с обработкой экономической информации:
· минимизация объема призначной информации при вводе ее в вычислительную систему и передаче по каналам связи;
· сортировка и поиск информации по ключевым признакам;
· разработка сводных экономических отчетов по различным признакам;
· декодирование при переходе от кодов-признаков к их наименованиям при печати сводных экономических отчетов.
Систематизация экономической информации вызывает необходимость применения различных классификаторов:
■ Общегосударственные классификаторы (ОК), разрабатываемые в централизованном порядке и являющиеся едиными для всей страны.
■ Отраслевые, единые для конкретной отрасли.
■ Региональные, единые для данной территории.
■ Локальные, составляемые на номенклатуры, характерные для данного предприятия, организации, фирмы.
Разработка локальных классификаторов ведется на местах при проектировании ИС. Наряду с ними на предприятиях используются и классификаторы общегосударственного и отраслевого значения.
Классификаторы общегосударственного значения составляют Единую систему классификации и кодирования (ЕСКК), насчитывают около четырех десятков и условно делятся на 4 группы:
1. Классификаторы трудовых и природных ресурсов, например ОК профессий рабочих, должностей служащих и тарифных разрядов (ОКПДТР).
2. Классификаторы информации о структуре экономики (СООГУ) и административно-территориальном делении страны (СОАТО).
3. Классификаторы информации о продукции и услугах (ОК промышленной и сельскохозяйственной продукции — ОКП), ОК строительной продукции.
4. Классификаторы технико-экономических показателей (ОКТЭП), Управленческой документации (ОКУД), единиц измерения (ОКЕИ) и др.
Большинство классификаторов имеет блочную структуру кодовых слов, что позволяет вести компьютерную обработку информации с использованием отдельных блоков кодовых обозначений или их частей.
В табл. 6.1 и 6.2 приведены примеры кодовых слов (с указанием их значности) структур Общегосударственных классификаторов промышленной и сельскохозяйственной продукции (ОКП) и Единого государственного регистра предприятий и организаций (ЕГРПО).
Таблица 6.1. Структура OKП
Блок идентификации
Блок наиме-
Идентификационный код
Контро-
нования
Класс
Подкласс
Группа
Подгруппа
Вид
льное число
продукции
XX
X
X
X
X
X
XX...X
Таблица 6.2. Структура ЕГРПО
Блок идентификации
Блок на-
Блок классификационных признаков
именования и местонахождения организации (предприятия)
Коды признаков
Идентификационный код (ОКПО)
Контрольное число
Министерство (СООГУ)
Территория (СОЛТО)
Отрасль народного хозяйства (ОКОИХ)
Форма собственности (КФС)
Организационно-правовая форма (КОПФ)
ххххххх
X
XX...X
XXX XX
хххх
ххххх
XX
XX
Приведем примеры построения некоторых ОК, имеющих наибольшее применение при автоматизированной обработке экономических показателей на предприятии. Как правило, эти коды проставляются в сводных отчетах, а также в некоторых первичных документах, например в счете-фактуре, платежных документах.
q ОК отраслей (ОКОНХ) используется для анализа структуры отрасли; код пятизначный, включает следующие признаки: отрасль, подотрасль, вид, группу, подгруппу.
q ОК предприятий и организаций (ОКПО) — регистрационный номер предприятия, присваиваемый органами госстатистики, код восьмизначный;
q КОПФ — код организационно-правовой формы, означает принадлежность предприятия к различным формам собственности;
q ОКЕИ — код единицы измерения; например, составляемый в тыс. рублей баланс предприятия имеет код «0372»;
q ОКУД — код управленческой документации, семизначный; например, баланс имеет код «0710001»;
q Идентифицированный номер налогоплательщика (ИНН) — десятизначный; первый и второй знаки означают территорию, третий и четвертый — номер государственной налоговой инспекции, остальные — номер налогоплательщика и контрольный разряд;
q Код лицевого счета организации заполняется в платежных документах, предоставляемых в банк; код построен в соответствии с указаниями Центробанка РФ и международными требованиями; имеет сложное построение: включает от 20 до 28 знаков и 11 выделенных признаков.
Локальные коды, как уже отмечалось, составляются на номенклатуры, специфичные для данной организации. Сюда входит широкий круг номенклатур, используемых различными подразделениями и службами ее управления.
При этом должно соблюдаться неукоснительное правило: локальные коды должны быть едиными при решении различных экономических задач. Например, коды табличных номеров одновременно используются управлением кадров для учета численности работающих и в бухгалтерии для выполнения расчетов по заработной плате; коды материалов — при заготовлении материалов в отделе снабжения; при учете их движения — на складе.
Основными номенклатурами локальных кодов на предприятии являются:
· структурные подразделения,
· работающие поставщики и покупатели,
· акционеры,
· материалы,
· готовая продукция,
· изделия,
· детали,
· соединения,
· полуфабрикаты;
· операции технологического процесса;
· основные средства,
· специальности и др.
Приступая к составлению классификаторов, прежде всего определяют, какие общегосударственные и отраслевые классификаторы можно использовать. Наряду со специалистом по информационной технологии в составлении классификаторов значительную роль играют экономисты-пользователи. Рассмотрим порядок составления локальных классификаторов.
Разработка классификаторов состоит из четырех этапов:
1. Установление перечня и количества объектов, подлежащих кодированию.
2. Систематизация объектов по определенным классификационным признакам (выбор системы классификации).
3. Определение правил обозначения объектов кодирования (выбор системы кодирования).
4. Разработка кодовых обозначений и положений по их ведению и внесению в них изменений.
На первом этапе определяются объекты (номенклатуры), подлежащие кодированию. Ими могут быть работающие, материалы, подразделения, оборудования, предприятия, организации и т. д. Затем по каждой номенклатуре устанавливается полный список всех позиций, подлежащих кодированию.
На втором этапе каждая номенклатура систематизируется по определенным классификационным признакам на основе выбранной системы классификации. Упорядоченное расположение классифицируемых элементов на основе установленных взаимосвязей между признаками составляет систему классификации.
На третьем этапе на основании системы классификации определяют правила обозначения объектов в соответствии с выбранной системой кодирования. Выбор системы кодирования в основном зависит от количества классификационных признаков и разработанной системы классификации и структуры ее построения.
В практике машинной обработки экономической информации широко применяют следующие системы кодирования: порядковую, серийно-порядковую, позиционную, комбинированную, повторения, шахматную, штриховую.
На четвертом этапе осуществляется непосредственное присвоение объектам кодовых обозначений, т. е. выполняется процесс кодирования — присвоение условных обозначений различным позициям номенклатуры. Заканчивается этот этап составлением классификатора, который оформляются в виде справочника.
Классификаторы имеют двоякое применение. Первое — для ручного проставления кодов в документах. В этом случае классификаторы оформляются в виде справочников и используются экономистами для подготовки первичных и сводных документов к машинной обработке.
Так, в сводных бухгалтерских отчетах (баланс, отчет о прибылях и убытках и др.) в заголовочной части бланка проставляются коды постоянных признаков отчитывающейся организации: идентификационный номер налогоплательщика (ИНН), код организации по ОКПО, отрасль (вид деятельности) по OFCOHX, организационно-правовая форма по КОПФ, орган управления государственным имуществом по ОКПО; единица измерения по ОКЕИ.
Если при машинной обработке на предприятиях (организациях, фирмах) осуществляется ввод данных с первичных документов, то документы предварительно кодируются, коды проставляются вручную в соответствии с инструкцией в специально отведенные места документа, в зоны постоянных и переменных признаков документа.
Второе применение кодов предусматривает хранение всех классификаторов в памяти машины, на машинных носителях в банке данных, в качестве словарного фонда или условно-постоянной информации.
Хранение классификаторов в ЭВМ позволяет автоматически формировать необходимую текстовую информацию в выходных сводках. Например, в машине постоянно хранится справочник на работающих, где имеются такие реквизиты, как фамилия, имя, отчество, табельный номер, профессия и др. При расчете заработной платы на ПК с первичных документов по начислениям и удержаниям в машину вводится только табельный номер работающего (без фамилии) и данные о заработной плате. В процессе обработки фамилия, имя, отчество, взятые из справочника, подформировываются к каждому табельному номеру. В результате в расчетно-платежной документации печатаются все фамилии работающих.
К кодам предъявляется ряд требований:
· они должны охватывать все объекты, подлежащие кодированию, и давать им однозначное обозначение;
· предоставлять возможность расширения объектов кодирования без изменения правил их обозначения;
· быть едиными для разных задач внутри одного экономического объекта (например, коды материалов, подразделений должны быть едиными для задач бухгалтерского учета и технической подготовки производства);
· отличаться стабильностью, удобством восприятия и запоминания кодовых обозначений, обеспечивающим простоту заполнения, чтения и обработки;
· обладать максимальной информированностью кода при минимальной его значности;
· иметь возможность использования кодов для автоматического получения сводных итогов и автоматического контроля кодовых обозначений с целью обнаружения ошибок.
Назначение кодовсостоит в обеспечении группировки информации в машине; подведении итогов по всем группировочным признакам и их печати в сводных таблицах; выполнении процедур поиска, хранения, выборки информации; передачи информации по каналам связи.
В последние годы стало широко использоваться штриховое кодирование. Оно является наименее дорогостоящим и поэтому наиболее применимым. Штриховой код основан на принципе двоичной системы счисления: информация запоминается как последовательность 0 и 1. Широким линиям и широким промежуткам присваивается логическое значение — 1, узким — 0. Штриховое кодирование есть способ построения кода с помощью чередования широких и узких, темных и светлых полос. Применение штрихового кодирования позволяет получить необходимую информацию, характеризующую товар, его свойства, и обеспечить возможность эффективного управления товародвижением вообще и к потребителю в частности, автоматизировать процессы расчетов за продаваемые товары и, следовательно, повысить эффективность управления производством.
Система штрихового кодирования информации представляет собой совокупность вида штриховых кодов и технических средств нанесения на носители информации, верификации качества печати, считывания с носителей, а также предварительной обработки данных.
Основными техническими средствами нанесения штриховых кодов на носители информации (бумага, самоклеющаяся пленка, металл, керамика, текстильное полотно, пластмасса, резина и др.) являются оборудование для изготовления мастер-фильмов (шаблонов штриховых кодов), компактные печатающие устройства различного принципа действия. Верификация, или контроль, качества печати штриховых кодов может быть осуществлена специализированным оборудованием, оснащенным соответствующими программными средствами. Для считывания штрихового кода с носителей информации используются сканирующие устройства различного типа: контактные карандаши и сканеры; лазерные сканеры и мобильные терминалы, считывающие информацию на расстоянии. Мобильный терминал обеспечивает помимо считывания информации с носителей предварительную обработку данных и их передачу на компьютер для дальнейшего обобщения и анализа.
К средствам формализованного описания экономической информации относится понятие «идентификатор».
Идентификатор — это условное обозначение реквизитов документов буквами латинского или русского алфавита; используется при описании реквизитов документов в постановке задач для последующего проектирования и программирования. Количество знаков должно находиться в диапазоне 3—8. Приведем примеры присвоения идентификаторов некоторым реквизитам (табл. 3.3).
Таблица 3.3.
Присвоение идентификаторов
Наименование реквизита
Идентификатор
Табельный номер работающего
ТАБНОМ
или
TABNOM
Количество деталей
КОЛДЕТ
или
KOLDET
Идентификация реквизитов первичных документов, условно-постоянной информации и сводных отчетов производится в процессе постановки задачи. Идентификаторы реквизитов соответствуют наименованиям полей в памяти машины.
Унифицированные системы документации создаются на государственном, республиканском, отраслевом и региональном уровнях.
Главная цель - это обеспечение сопоставимости показателей различных сфер общественного производства.
Разработаны стандарты, где устанавливаются требования:
• к унифицированным системам документации;
• к унифицированным формам документов различных уровней управления;
• к составу и структуре реквизитов и показателей;
• к порядку внедрения, ведения и регистрации унифицированных форм документов.
Однако, несмотря на существование унифицированной системы документации, при обследовании большинства организаций постоянно выявляется целый комплекс типичных недостатков:
• чрезвычайно большой объем документов для ручной обработки;
• одни и те же показатели часто дублируются в разных документах;
• работа с большим количеством документов отвлекает специалистов от решения непосредственных задач;
• имеются показатели, которые создаются, но не используются, и др.
Поэтому устранение указанных недостатков является одной из задач, стоящих при создании информационного обеспечения.
Схемы информационных потоков отражают маршруты движения информации и ее объемы, места возникновения первичной информации и использования результатной информации.
За счет анализа структурыподобных схемможно выработать меры по совершенствованию всей системы управления.
Построение схем информационных потоков, позволяющих выявить объемы информации и провести ее детальный анализ, обеспечивает:
· исключение дублирующей и неиспользуемой информации;
· классификацию и рациональное представление информации.
При этом подробно должны рассматриваться вопросы взаимосвязи движения информации по уровням управления.
Следует выявить, какие показатели необходимы для принятия управленческих решений, а какие нет.
К каждому исполнителю должна поступать только та информация, которая используется.
Внутримашинное информационное обеспечение включает совокупность информационных массивов и баз данных, процедуры организации, ведения, хранения и обработки баз данных, методы и средства преобразования внешнего представления данных в машинное и обратно, описания хранимой и обрабатываемой информации.
База данных – набор данных организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования данными.
Методология построения баз данных базируется на теоретических основах их проектирования. Для понимания концепции методологии приведем основные ее идеи в виде двух последовательно реализуемых на практике этапов:
1-й этап - обследование всех функциональных подразделений фирмы с целью:
• понять специфику и структуру ее деятельности;
• построить схему информационных потоков:
• проанализировать существующую систему документооборота;
• определить информационные объекты (те объекты по которым должна содержаться информация) и соответствующий состав реквизитов (параметров, характеристик), описывающих их свойства и назначение.
2-й этап - построение концептуальной информационно-логической модели данных для обследованной на 1-м этапе сферы деятельности.
В этой модели должны быть установлены и оптимизированы все связи между объектами и их реквизитами. Информационно-логическая модель является фундаментом, на котором будет создана база данных.
Залогом успешной организации информационного обеспечения ИС является:
• ясное понимание целей, задач, функций всей системы управления организацией;
• выявление движения информации от момента возникновения и до ее использования на различных уровнях управления, представленной для анализа в виде схем информационных потоков;
• совершенствование системы документооборота;
• наличие и использование системы классификации и кодирования;
• владение методологией создания концептуальных информационно-логических моделей, отражающих взаимосвязь информации;
• создание массивов информации на машинных носителях, что требует наличия современного технического обеспечения.
Методы криптографического закрытия информации: шифр замены, шифр Вижинера, гаммирование. Сжатие информации как разновидность кодирования. Примеры сжатия числовых массивов и последовательностей. Помехоустойчивое кодирование: контроль по четности-нечетности, код Хемминга.
Конфиденциальная информация.Во многих случаях хранимая и передаваемая информация представляет собой немалую ценность, и в силу объективных обстоятельств доступ к ней не должен быть свободным. Такая информация является конфиденциальной (секретной) и, следовательно, должна быть защищена. Подразумевается, что существует определенный круг лиц, которые имеют право владеть этой информацией – законные пользователи. При этом может возникнуть угроза несанкционированного доступа, в результате чего информацией могут завладеть незаконные пользователи. Для защиты информации разработан целый комплекс мер, в том числе технических и организационных. В данной лекции нас интересует защита методами кодирования. Они называются криптографическими методами.
Криптографическое кодирование.Криптография – это наука о методах преобразования (кодирования) информации с целью ее защиты от незаконных пользователей.
Криптографическое кодирование иначе называется шифрованием, обратное преобразование называется дешифрованием. Зашифрованное сообщение называется криптограммой. Особенностью криптографических методов кодирования является то, что содержание исходного сообщения становится доступным только при наличии у получателя некоторой специфической информации – ключа, с помощью которой осуществляется дешифрование криптограммы.
Современные методы криптографического закрытия информации должны обладать большой надежностью и обеспечивать секретность с учетом того, что противник зачастую имеет возможность перехвата и записи криптограмм, а также в случаях, когда алгоритм шифрования стал известен. Метод должен предусматривать такое множество возможных ключей, чтобы вероятность определения использованного была близка к нулю, даже при наличии фрагментов зашифрованных сообщений.
Рассмотрим некоторые методы построения криптографических кодов в порядке их хронологического появления и, следовательно, возрастания сложности.
Шифр замены.При использовании данного метода буквы кодируемого сообщения заменяются буквами того же или другого алфавита. Если исходный алфавит насчитывает k символов, то существует k ! способов записать сообщение с помощью символов этого же алфавита. А это значит, что существует (k ! – 1) ключей. Рассмотрим пример применения такого шифра.
Пусть дан русский алфавит, состоящий из 32 букв, включая пробел (см. табл . 2.1). В качестве ключа выберем одну из возможных перестановок его букв и запишем под буквами исходного алфавита их значение согласно ключу.
А Й
Б Ц
В У
Г К
Д Е
Е Н
Ж Г
З Ш
И Щ
Й З
К Х
Л _
М Ъ
Н Ф
О Ы
П В
Р А
С П
Т Р
У О
Ф Л
Х Д
Ц Ж
Ч Э
Ш Я
Щ Ч
Ъ С
Ы М
Э И
Ю Б
Я Ю
_ Т
Метод замены с данным ключом преобразует слово АЛГОРИТМ в криптограмму Й_КЫАЩРЪ. Заметим, что для кодирования может быть выбран любой алфавит. Примером такого кодирования могут служить «пляшущие человечки» из известного рассказа К.Дойла.
Метод шифрования по принципу замены так же прост, как и ненадёжен. Это обусловлено тем, что при простой замене сохраняются статистические свойства исходного алфавита, они лишь переносятся на другие символы. При наличии достаточно длинной криптограммы статистический анализ текста позволяет установить вероятности появления символов, а по ним ключ, который даст исходный текст практически без ошибок.
Шифр Вижинера.Шифр Вижинера обладает более высокой степенью защиты информации, которая достигается благодаря нарушению статистистических закономерностей появления букв исходного алфавита. Вместе с тем он достаточно прост для шифрования.
Прежде всего, буквы исходного алфавита объемом N нумеруются числами от 0 до N – 1 включительно. Например, буквам латинского алфавита ставятся в соответствие числа от 0 до 25.
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
K 10
L 11
M 12
N 13
O 14
P 15
Q 16
R 17
S 18
T 19
U 20
V 21
W 22
X 23
Y 24
Z 25
Ключом может быть произвольное слово. Подлежащий шифрованию текст заменяется последовательностью чисел в соответствии с нумерацией символов алфавита. Символы ключа также заменяют их числовыми эквивалентами, исходя из нумерации. Ключ записывается под строкой сообщения столько раз, сколько нужно, чтобы закрыть все сообщение. После этого числа двух последовательностей суммируются друг с другом по модулю N . Полученное числовое сообщение после преобразования в буквенную форму является криптограммой. Рассмотрим сказанное на примере.
Закодируем слово PROGRAM по ключу DOG .
P R O G R A M – исходное сообщение 15 17 14 6 17 0 12 +D O G D O G D – ключ 3 14 6 3 14 6 3 18 5 20 9 5 6 15 S F U J F G P – криптограмма
Сложение по модулю N заключается в том, что сумма двух слагаемых S не должна превосходить по величине модуль N . Если же арифметическая сумма получилась больше N , то в качестве результата берется разность (S - N).
Для того, чтобы расшифровать полученное сообщение, необходимо проделать все в обратном порядке. Под числовыми эквивалентами криптограммы необходимо записать числовые эквиваленты ключа и вычесть числа нижней последовательности из чисел верхней по модулю N . Последнее означает, что если уменьшаемое будет меньше вычитаемого, то к уменьшаемому надо прибавить значение модуля N .
Выполним обратное преобразование над полученной криптограммой.
S F U J F G P – криптограмма 18 5 20 9 5 6 15 – D O G D O G D – ключ 3 14 6 3 14 6 3 15 17 14 6 17 0 12 P R O G R A M – исходное сообщение
Частный случай шифра Вижинера, когда длина ключа равна единице (т. е. ключ состоит из одной буквы), называется шифром Цезаря. В этом случае кодирование сводится к сдвигу (замене всех символов сообщения на те, что находятся на расстоянии, равном номеру буквы – ключа).
Шифр Вижинера обладает высокой надежностью лишь при использовании весьма длинных ключей. Шифр Вижинера с неограниченным неповторяющимся ключом называется шифром Вернама.
Гаммирование.Идея этого метода близка к методу Вижинера. Но важное отличие состоит в том, что последовательность, выполняющая роль ключа, является псевдослучайной и генерируется с помощью датчика псевдослучайных чисел. Она называется гаммой.
Исходное сообщение суммируется с гаммой по модулю N (число букв в исходном алфавите) и преобразуется так же, как в методе Вижинера.
Псевдослучайная последовательность обладает двумя важными свойствами: с одной стороны она удовлетворяет тесту на случайность, что значительно затрудняет раскрытие ключа, с другой – остается детерминированной, что обеспечивает однозначность дешифрования.
В качестве примера генератора псевдослучайной последовательности чисел приведем датчик Лемера, который для начального числа a0 вырабатывает бесконечную последовательность чисел по следующему рекуррентному закону:
ak= d + ak-1 × m (mod M),
где d , m , M – некоторые целые числа.
Надежность закрытия информации методом гаммирования определяется длиной неповторяющейся части гаммы. Доказано, что если она превышает длину кодируемого текста, то раскрытие криптограммы только на основе ее статистического анализа теоретически невозможно. Однако в этом случае требуется обеспечить секретность ключа, что не менее затратно, чем обеспечить секретности передаваемого сообщения.
Современные стандарты шифрования предусматривают многоступенчатое шифрование исходного текста и самих ключей, то есть используется несколько ключей, на основе которых генерируются субключи, применяемые непосредственно для шифрования.
Одно из наиболее перспективных направлений современной криптографии – шифрование с открытым ключом. Данное направление основано на использовании для шифрования так называемых односторонних функций. Системы криптографического кодирования на односторонних функциях характеризуются тем, что для передачи сообщений не требуется предварительного обмена ключами по секретным каналам связи. Стойкость шифра зависит от сложности нахождения результата некоторой трудно решаемой математической задачи, связанной с обращением односторонней функции. На этом подходе базируется, например, возможность применения электронной (цифровой) подписи.
Кодирование и сжатие информациипредставляет собой операцию, в результате которой данному коду или сообщению ставится в соответствие более короткий код или сообщение.
Сжатие информации производится с целью ускорения и удешевления процессов автоматической обработки, поиска и хранения информации. Основная проблема при построении сжимающих кодов заключается в том, чтобы обеспечить наименьшую неоднозначность сжатых кодов при максимальной простоте сжимающих алгоритмов. Желательно, чтобы сжатая информация была восстановлена без потерь.
Методы сжатия существенно зависят от структуры сжимаемых объектов, их смысла, целей сжатия и других факторов. Рассмотрим в качестве примера простой случай сжатия числовых массивов.
Сжатие числовых массивов.Очень часто обрабатываемая информация представлена в виде однородных числовых массивов, в которых элементы столбцов или строк стоят в нарастающем порядке. Например, данные мониторинга какого-либо природного процесса (землетрясений), где любая запись начинается с даты. Данное свойство можно успешно использовать для эффективного сжатия таких массивов.
Пример 5.1. Требуется сжать массив, в котором повторяющиеся фрагменты расположены в начале каждой строки.
В основе метода сжатия лежит идея исключения повторов. Заменим повторы каким-либо символом, например s.
Исходный массив
Сжатый массив
s5s386s
67s91s3
Восстановление массива выполняется в два этапа. Первый этап заключается в просмотре массива с конца с целью восстановления размера исходного массива (развертывания). Это достигается тем, что при встрече символа s, означающего повтор, мы переходим на следующую строку. Таким образом, в полученном массиве будут зарезервированы места под еще не восстановленные цифры, обозначим их символом «*». Второй этап заключается в копировании на зарезервированные места символов из предыдущей строки.
Развернутый массив
Восстановленный массив
******5
****386
*****90
*****91
******3
Этот подход легко обобщить и для случая, когда повторяющиеся фрагменты массива встречаются и в середине строки. Однако в этом случае требуется ввести еще один символ, означающий конец строки k . При восстановлении массива его развертывание будет вестись от k до k . Приведем пример подобной процедуры сжатия – восстановления.
Существуют также и другие, более эффективные методы сжатия числовых последовательностей. Однако в этой лекции мы только коснулись проблемы сжатия в связи с изучением кодирования. Многообразие приемов сжатия информации заслуживает отдельного рассмотрения.
Помехоустойчивое кодирование.Помехой для электронных цифровых устройств является внешнее или внутреннее воздействие, приводящее к искажению информации во время ее передачи, преобразования, обработки и хранения. Поскольку на всех перечисленных этапах информация представлена в закодированном виде, понятно, насколько важным является создание таких кодов, которые обеспечивали бы возможность обнаружения и исправления случайных ошибок, возникающих на различных этапах ее обращения. Такие коды называются помехоустойчивыми.
Обнаружением и исправлением постоянных ошибок (отказов) и случайных ошибок (сбоев) в ЭВМ занимается система контроля цифровых автоматов. Случайные ошибки значительно труднее поддаются обнаружению, поэтому работа системы контроля в этом случае базируется на применении помехоустойчивых кодов. Основная идея контроля – получить на выходе кодовую последовательность, которая была бы ближе к сгенерированной, а не к какой-либо другой. Практическая реализации этой задачи возможна путем введение в код избыточности. Такие коды называются систематическими.
Систематический код – это код, включающий не только информационные, но и контрольные разряды.
Введение избыточности позволяет сформировать кодовые слова, удовлетворяющие некоторым дополнительным условиям, проверка которых и дает возможность получателю закодированного сообщения обнаружить ошибку.
Контроль по четности-нечетности .Одним из простых кодов, позволяющих обнаруживать одиночные ошибки, является код с проверкой на четность. Он образуется путем добавления к передаваемой комбинации, состоящей из m информационных символов, одного контрольного бита так, чтобы общее число единиц в передаваемой комбинации было четным. В итоге общее число элементов в передаваемой комбинации равно n = m + 1. На приёмной стороне производят проверку на четность. При четном числе единиц предполагается, что ошибок нет, и потребителю выдается m бит, а контрольный элемент отбрасывается. Аналогично строится код с проверкой на нечетность.
Кодирующие и декодирующие устройства кодов с защитой на четность – самые простые. Формирование контрольного бита осуществляется сумматором по модулю 2 (Т-триггером). Пример реализации метода четности представлен в табл. 5.1.
Таблица 5.1
Число
Контрольный разряд
Проверка
1 – ошибка
Ясно, что если искажен один разряд или нечетное число разрядов (ошибка нечетной кратности), ошибка будет обнаружена. Ошибка четной кратности обнаружена не будет.
Учитывая это ограничение, был предложен модифицированный способ контроля по четности-нечетности. Он заключается в том, что длинное слово разбивается на группы по l разрядов. Группы располагаются одна под другой, образуя матрицу. Контрольные разряды вносятся по всем группам по строкам и по столбцам согласно схеме, изображенной на рис. 5.1.
Рис. 5.1. Схема формирования контрольных разрядов
Предположим, что искажен один разряд а7. Проверка путем суммирования элементов второй строки с учетом k2 и второго столбца с учетом k6 укажет на ошибку и позволит ее исправить.
Проведя подобные рассуждения для ошибок большей кратности, можно заметить следующее:
– если произошли две однобитовые ошибки в одной строке или в одном столбце, то эти ошибки будут обнаружены, но исправление их невозможно;
– если две однобитовые ошибки находятся в разных строках и разных столбцах, то эти ошибки будут обнаружены, но исправление их невозможно;
– если произошли три однобитовые ошибки в одной строке или в одном столбце, то эти ошибки могут быть обнаружены и исправлены;
– три однобитовые ошибки, расположенные в разных строках и столбцах, будут обнаружены, но исправление их невозможно;
– ошибки не будут обнаружены, если они расположены в виде подмассива, имеющего чётное число строк и столбцов. Например, если ошибки расположены в разрядах а7, а8, а12, а13 (рис. 5.1).
Дальнейшим развитием модифицированного контроля по чётности-нечётности является представление информации в виде трёхмерного массива, в котором контрольные разряды вычисляются по трём координатам.
Контроль по методу чётности-нечётности используется в ЭВМ для контроля записи, считывания, передачи информации, а также при выполнении арифметических операций. Причём контроль по нечётности имеет то преимущество, что при передаче информации по параллельной шине возможно обнаружить обрыв шины.
Недостатком модифицированного кода, использующего проверку на четность по столбцам и строкам, является его высокая избыточность (около 15%).
Код Хэмминга.Систематический код, предложенный в 1949 г. американским учёным Ричардом Хэммингом, обладает способностью не только обнаруживать, но и исправлять одиночные ошибки. Корректирующая способность кода Хемминга связана с понятиями разрешенной и запрещенной кодовых комбинаций и понятием кодового расстояния.
Назовем множество кодовых комбинаций, используемых при кодировании передаваемых сообщений, разрешенными. В результате искажения сигнала, на этапе приема мы получим множество, в котором будут не только разрешенные, но и запрещенные кодовые комбинации. В этом случае принятая запрещенная комбинация отождествляется с той разрешенной, что находится от нее на минимальном расстоянии Хемминга.
Расстояние Хемминга характеризует степень близости двух последовательностей: расстояние Хемминга есть число одинаковых разрядов в двух последовательностях. Для использования предложенного Хеммингом подхода, требуется оценить минимальное кодовое расстояние по всем разрешенным кодовым комбинациям.
Рассмотрим идеи, лежащие в основе построения кодов Хемминга на простом примере двоичного кода. Возьмем сначала двоичный трехразрядный код: {000, 001, 010, 011, 100, 101, 110, 111}.
Если все перечисленные здесь комбинации являются разрешенными, то при любой одиночной (и не только) ошибке всякая разрешенная комбинация переходит в другую разрешенную комбинацию. Данный код является примером безизбыточного, не обладающего корректирующей способностью кода. Минимальное кодовое расстояние d здесь равно 1. Т.е. достаточно изменить значение одного разряда, чтоб получить другую разрешенную комбинацию.
Рассмотрим теперь кодовые комбинации {000, 011, 101, 110}. Минимальное кодовое расстояние здесь d =2. Ни одна из кодовых комбинаций при одиночной ошибке не переходит в другую. Запрещенными комбинациями в этом случае будут {001, 010, 100, 111}. Отметим, что все разрешенные комбинации содержат четное число единиц. Этот код обнаруживает одиночные ошибки и ошибки нечетной кратности, однако не позволяет надежно их исправлять.
Трехразрядный код с минимальным кодовым расстоянием d =3 содержит две разрешенных комбинации {000, 111} и шесть запрещенных {001, 010, 011,100, 101, 111}.
Множество запрещенных комбинаций можно единственным образом разбить на два непересекающихся подмножества Т1 = {001, 010, 100} и Т2= {011, 101, 110}, так что разрешенная комбинация 000 может перейти при одиночной ошибке только в комбинацию из Т1 , а комбинация 111 – только в комбинацию из Т2. Таким образом, при поступлении любой запрещенной комбинации ошибка не только обнаруживается, но и корректируется.
В приведенных примерах не рассматривалось введение контрольных разрядов, как это делается при построении кода Хемминга для некоторой непрерывной кодовой последовательности, ввиду нетривиальности метода.
Завершая общее знакомство с помехоустойчивыми кодами, приведем для общего сведения без доказательства следующее условие, необходимое для обнаружения и исправления ошибок.
Для исправления всех ошибок кратности s и одновременного обнаружения (без исправления) ошибок кратности r(r≥s) необходимо при построении корректирующего кода минимальное расстояние Хемминга d выбирать из условия d≥(r + s + 1).

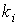 вносятся по всем группам по строкам и по столбцам согласно схеме, изображенной на рис. 5.1.
вносятся по всем группам по строкам и по столбцам согласно схеме, изображенной на рис. 5.1.