Основне призначення Internet Protocol полягає в передачі дейтаграм через зв'язані між собою сімейства мереж. Це досягається передачею дейтаграм від одного модуля IP-сервісу до іншого доти, поки не буде досягнутий комп'ютер одержувача. Дейтаграми передаються через інтерфейси локальних мереж, а вибір шляху здійснюється на основі IP-адреси одержувача пакета.
При передачі повідомлення від одного IP-модуля до іншого може статися так, що дейтаграми будуть передаватися по мережі, для якої припустимий розмір пакета менше розміру дейтаграми. Тоді починає працювати механізм фрагментації дейтаграм, передбачений функціональністю IP-протоколу.
Фрагментація IP-дейтаграми необхідна, коли її розмір перевищує розмір максимально припустимого пакета даних при передачі по локальній мережі.
Однак не всі дейтаграми можуть бути фрагментовані. Якщо дейтаграма позначена як "не фрагментована" (тобто встановлений прапор No Fragment), то така дейтаграма ні за яких обставин не може піддаватися поділові на пакети меншої довжини. Якщо така дейтаграма не може бути доставлена в точку призначення без фрагментації, вона буде знищена. В інших випадках дейтаграму можна розбити на більш дрібні фрагменти.
Процедура фрагментації і передачі фрагментованої дейтаграми по локальній мережі ніяк не відбивається на IP-структурі пакета і називається "внутрішньою" — Intranet фрагментацією. Це означає, що для протоколу верхнього рівня, і тим більше для протоколів більш високих рівнів, ця операція буде непомітною і ніяк не відіб'ється на їхній роботі.
Процедура фрагментації може розбити дейтаграму на пакети довільної довжини і потім відновити її в первісному виді. Кожен фрагмент вихідної дейтаграми має унікальний ідентифікатор (identification field), що однозначно визначає його приналежність до вихідного фрагментованого пакета. Це число унікальне для пари адрес відправник-одержувач увесь той час, поки дейтаграма знаходиться в мережі. Поля зсуву (fragment offset) і довжини, задані для кожного фрагмента вихідної дейтаграми, цілком визначають положення фрагмента у вихідній дейтаграмі. Крім того, IP-пакет містить прапор "наступного фрагмента", що вказує на те, що в даної порції є продовження або що даний фрагмент останній. Інформації цих полів досить, щоб IP-модуль, що одержує серію фрагментів, міг зібрати вихідну дейтаграму.
Для того щоб піддати фрагментації довгу дейтаграму, IP-модуль, що працює, наприклад, на шлюзі, створює дві нові дейтаграми і копіює зміст заголовка довгої дейтаграми в заголовки кожної з копій.
Дані довгої дейтаграми поділяються на дві порції по 64-бітній границі (друга порція не обов'язково повинна бути вирівняна по 64 бітах, але перша — обов'язково). Перша порція даних розміщається в першій дейтаграмі. У поле довжини фрагмента встановлюється довжина першої порції даних. Потім у першої дейтаграмі встановлюється прапор "наявності наступного фрагмента".
Друга порція даних поміщається в другу дейтаграму. У поле довжини другої дейтаграми встановлюється довжина другої порції даних. Прапор "наявності наступного фрагмента" залишається таким же, як і в початкової довгої дейтаграми (на той випадок, якщо вона також виявилася лише фрагментом іншої, ще більш довгої дейтаграми). У поле "зсуву фрагмента" другої дейтаграми встановлюється сума полів зсуву довгої дейтаграми і кількості 64-бітних блоків першої порції.
Ясно, що подібна процедура може використовуватися при розділі дейтаграми на будь-яку кількість частин.
Для зборки дейтаграми з фрагментів модуль IP-протоколу, наприклад, комп'ютера призначення, комбінує дейтаграми, що мають те саме значення полів ідентифікатора, джерела відправлення, адреси призначення і типу протоколу, і на підставі параметрів зсуву, довжини і прапора фрагментації формує вихідну довгу дейтаграму.
При описі роботи IP-протоколу майже завжди мається на увазі його функція адресації пакетів. Так, наприклад, якщо ми відправляємо лист звичайною поштою, ми можемо добре упакувати послання, розкласти його по невеликих конвертах, якщо пошта не допускає пересилання занадто великих відправлень, але, якщо ми не вкажемо адреси, усі наші витівки будуть марні — лист не дійде.
Істотним компонентом будь-якої системи мережі є процедура визначення місцезнаходження інших комп'ютерних систем. Різні схеми адресації, використовувані для цієї мети, залежать від використовуваного сімейства протоколів і рівня протоколу, що адресує, у багаторівневій системі взаємодії.
IP-протокол відноситься до мережевого рівня системи протоколів. Тут, напевно, досить відзначити, що IP-пакет містить дві основних адреси — відправника й одержувача. Обидві ці адреси статичні, тобто не міняються на протязі усього шляху IP-пакета і являють собою два 32-бітних числа.
Крім них IP-дейтаграма може (але, узагалі говорячи, не повинна) містити також адреси шлюзів мережі, що вона повинна пройти по шляху до одержувача. У таких IP-дейтаграмах адреси хостів "маршруту" розташовані у виді масиву з вказівником на наступний проміжний хост. При відправленні такої дейтаграми враховується не поле адреси призначення, а поле адреси першого "проміжного" хоста. Після того як дейтаграма буде оброблена маршрутизатором цього хоста, вказівник масиву пересувається на наступну адресу хоста в масиві і т.д., поки не будуть пройдені всі хости, зазначені в структурі, або не буде досягнута адреса призначення. Якщо масив проміжних шлюзів вичерпався, а дейтаграма ще не доставлена за адресою призначення, то вона направляється за адресою одержувача. Адреси, зазначені в структурі, повинні проходитися дейтаграмою одна за одною і бути розташовані в області "прямої видимості". Якщо таку передачу здійснити неможливо — дейтаграма знищується.
Контрольні запитання
1. Яке призначення Internet Protocol?
2. З протоколами якого рівня безпосередньо взаємодіє Internet Protocol?
3. Поясніть модель роботи передачі дейтаграми від одного комп'ютера до іншого.
4. За яких умов починає працювати механізм фрагментації дейтаграм?
5. Яке призначення Intranet фрагментації?
6. Як поділяються дані довгої дейтаграми?
Задача класифікації
Класифікація є найбільш простий і одночасно найбільш часто розв'язуваною задачею Data Mining. Через поширеність задач класифікації необхідно чітке розуміння суті цього поняття.
Наведемо кілька означень.
Класифікація – системний розподіл досліджуваних предметів, явищ, процесів по родах, видах, типах, по яких-небудь істотних ознаках для зручності їх дослідження; групування вихідних понять і розташування їх у певному порядку, що відбиває ступінь цієї подібності.
Класифікація – впорядковані по деякому принципі множини об'єктів, які мають подібні класифікаційні ознаки (одну або кілька властивостей), вибраних для визначення подібності або розходження між цими об'єктами.
Класифікація вимагає дотримання наступних правил:
Ø у кожному акті ділення необхідно застосовувати тільки одну основу;
Ø ділення повинне бути розмірним, тобто загальний обсяг видових понять повинен дорівнювати обсягу діленого родового поняття;
Ø члени розподілу повинні взаємно виключати один одного, їх об'єми не повинні перехрещуватися;
Ø розподіл повинен бути послідовним.
Розрізняють:
Ø допоміжну (штучну) класифікацію, що виробляється по зовнішній ознаці та служить для додання множини предметів (процесів, явищ) потрібного порядку;
Ø природну класифікацію, яка виробляється по істотних ознаках, що характеризує внутрішню спільність предметів і явищ. Вона є результатом і важливим засобом наукового дослідження, тому що припускає та закріплює результати вивчення закономірностей класифікуємих об'єктів.
Залежно від обраних ознак, їх сполучення і процедури поділу понять класифікація може бути:
Ø простою – розподіл родового поняття тільки по ознаці і тільки один раз до розкриття всіх видів. Прикладом такої класифікації є дихотомія, при якій членами розподілу бувають тільки два поняття, кожне з яких суперечить іншому (тобто дотримується принцип: "А і не А");
Ø складною – застосовується для поділу одного поняття по різним основах і синтезу таких простих розподілів у єдине ціле. Прикладом такої класифікації є періодична система хімічних елементів.
Під класифікацією будемо розуміти віднесення об'єктів (спостережень, подій) до одного з наперед відомих класів.
Класифікація – це закономірність, що дозволяє робити висновок щодо визначення характеристик конкретної групи. Таким чином, для проведення класифікації повинні бути присутні ознаки, що характеризують групу, до якої належить та або інша подія або об'єкт (звичайно при цьому на підставі аналізу вже класифікованих подій формулюються якісь правила).
Класифікація відноситься до стратегії навчання з вчителем (supervised learning), що також називають контрольованим або керованим навчанням.
Задачею класифікації часто називають прогнозування категоріальної залежної змінної (тобто залежної змінної, що є категорією) на основі вибірки безперервних і/або категоріальних змінних.
Наприклад, можна прогнозувати, хто з клієнтів фірми є потенційним покупцем певного товару, а хто – ні, хто скористається послугою фірми, а хто – ні, і т.д. Цей тип завдань відноситься до завдань бінарної класифікації, у них залежна змінна може приймати тільки два значення (наприклад, так чи ні, 0 або 1).
Інший варіант класифікації виникає, якщо залежна змінна може приймати значення з деякої множини визначених класів. Наприклад, коли необхідно прогнозувати, яку марку автомобіля захоче купити клієнт. У цих випадках розглядається множина класів для залежної змінної.
Класифікація може бути одномірною (по одній ознаці) і багатомірною (по двох і більше ознаках).
Багатомірна класифікація була розроблена біологами при розв'язанні проблем дискримінації для класифікування організмів. Однієї з перших робіт, присвячених цьому напрямку, вважають роботу Р. Фішера (1930 р.), у якій організми розділялися на підвиди залежно від результатів вимірів їх фізичних параметрів. Біологія була та залишається найбільш затребуваним і зручним середовищем для розробки багатомірних методів класифікації.
Розглянемо задачу класифікації на простому прикладі. Допустимо, є база даних про клієнтів туристичного агентства з інформацією про вік і доход за місяць. Є рекламний матеріал двох видів: більш дорогий і комфортний відпочинок і більш дешевий, молодіжний відпочинок. Відповідно, визначені два класи клієнтів: клас 1 і клас 2. База даних наведена в таблиці 5.1.
Таблиця 5.1. База даних клієнтів туристичного агентства
| Код клієнта
| Вік
| Доход
| Клас
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Задача. Визначити, до якого класу належить новий клієнт і який з двох видів рекламних матеріалів йому варто відсилати.
Для наочності представимо нашу базу даних у двомірному просторі (вік і доход), у вигляді множини об'єктів, що належать класам 1 (жовтогаряча мітка) і 2 (сіра мітка). На мал. 5.1 наведені об'єкти із двох класів.
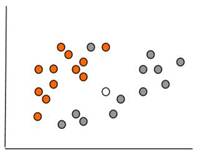
Рис. 5.1. Множина об'єктів бази даних у двомірному просторі
Вирішення нашої задачі буде полягати в тому, щоб визначити, до якого класу відноситься новий клієнт, на малюнку позначений білою міткою.