Наприклад, у спостереженні було виявлено певний відсоток якоїсь ознаки. Виникає питання: якщо провести інші такі ж спостереження, чи буде отриманий точно такий відсоток даної ознаки? Очевидно, ні. Одні спостереження дадуть відсоток нижчий, інші – вищий. Отже, найчастіше дати відповідь у вигляді точно визначеного відсотка не можна, а правильно буде вказати інтервал, у межах якого знаходиться відсоток, що цікавить дослідника.
Цей інтервал визначається наступним чином.
Його нижня межа дорівнює: Р -  , а верхня: Р +, де
, а верхня: Р +, де
Р – одержаний у розрахунках відсоток;
- розмір неточності, яка допускається у зв'язку з несуцільним характером спостереження.
Цю величину неточності знаходять за такою формулою:
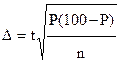 , де (1)
, де (1)
n – кількість випадків, за якими спостерігають;
P – винайдений відсоток;
t – так званий, довірчий коефіцієнт, що з визначеною ймовірністю вказує на величину .
При ймовірності  = 0,95 (можливість помилкової оцінки складає лише 5%), а коефіцієнт t=1,96 або
= 0,95 (можливість помилкової оцінки складає лише 5%), а коефіцієнт t=1,96 або 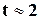 . При = 0,99 (помилка неточності = 1%), t = 2,58; при = 0,9973 (помилка неточності = 0,27%), t = 3 і т.д.
. При = 0,99 (помилка неточності = 1%), t = 2,58; при = 0,9973 (помилка неточності = 0,27%), t = 3 і т.д.
Значення t подане в таблиці:[1] “Значення функції 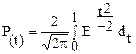 ”.
”.
У психологічних наукових і практичних дослідженнях використовуються здебільшого вказані значення коефіцієнту t.
▼ Приклад. При спостереженні за 100 довільно підібраними дітьми дошкільного віку з мовними порушеннями було встановлено, що 15 з них лівші (тобто 15%). Який дійсний відсоток лівшів серед дітей з мовними розладами?
● Рішення. При довірчому критерії ймовірності 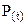 = 0,95, де коефіцієнт t =2 використовуємо формулу 1 і знаходимо інтервал ():
= 0,95, де коефіцієнт t =2 використовуємо формулу 1 і знаходимо інтервал ():

Отже інтервал, у межах якого знаходиться дійсний відсоток лівшів серед дітей з мовними розладами дорівнює кількісному показнику від 8 до 22% (15% - 7% 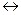 15% + 7%). Таким чином, з імовірністю у 95% можна бути впевненим, що дійсний відсоток лівшів серед дітей з розладами мови знаходиться у діапазоні 8 – 22 відсотків.
15% + 7%). Таким чином, з імовірністю у 95% можна бути впевненим, що дійсний відсоток лівшів серед дітей з розладами мови знаходиться у діапазоні 8 – 22 відсотків.
■ Зауваження. Якщо припустити, що спостерігалося не 100, а 400 випадково відібраних дітей з тими ж дефектами мови, і що 60 з них виявилися лівшами, то відсоток лівшів також буде 15, але інтервал, у межах якого знаходиться дійсний їх відсоток, зменшиться вдвічі. Виконаємо розрахунки.
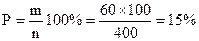

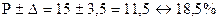
Отже, із збільшенням числа спостережень, величина допущеної неточності зменшується.
У зв’язку з цим виникає запитання: як знаходити оптимальне число спостережень при обчисленні альтернативних статистичних показників – відносних величин?