Рис. 5.4. Иерархическая организация файловой структуры хранения
Рис. 5.3. Модель хранения информации на устройстве последовательного доступа
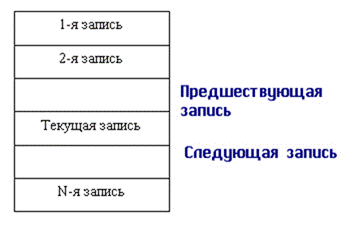
Рис. 5.2. Абстрактное представление файла
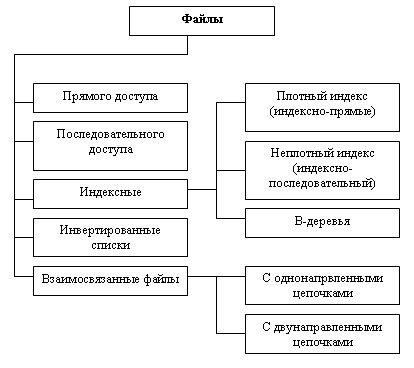
Рис. 5.1. Классификация файлов, используемых в системах баз данных
Основные понятия
В БД файлы и файловые структуры, которые используются для хранения информации во внешней памяти, можно классифицировать следующим образом (рис. 5.1).
С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на внешних носителях. На рис. 5.2 представлена такая условная последовательность записей. Так как файл – это линейная последовательность записей, то всегда в файле можно определить текущую запись, предшествующую ей и следующую за ней. Всегда существует понятие первой и последней записи файла. В соответствии с методами управления доступом различают устройства внешней памяти с произвольной адресацией (магнитные и оптические диски) и устройства с последовательной адресацией (магнитофоны, стримеры).
На устройствах с произвольной адресацией теоретически возможна установка головок чтения-записи в произвольное место мгновенно. Практически существует время позиционирования головки, которое весьма мало по сравнению со временем считывания-записи.В устройствах с последовательным доступом для получения доступа к некоторому элементу требуется «перемотать (пройти)» все предшествующие ему элементы информации. На устройствах с последовательным доступом вся память рассматривается как линейная последовательность информационных элементов (рис. 5.3).
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа, могут быть реализованы как файлы прямого доступа. В этих файлах физический адрес расположения нужной записи может быть вычислен по номеру записи (NZ).
Каждая файловая система, как правило, поддерживает некоторую иерархическую файловую структуру, которая включает чаще всего неограниченное количество уровней иерархии в представлении внешней памяти (рис. 5.4).
Для каждого файла в системе хранится следующая информация:
· имя файла;
· тип файла (например, расширение или другие характеристики);
· размер записи;
· количество занятых физических блоков;
· базовый начальный адрес;
· ссылка на сегмент расширения;
· способ доступа (код защиты).
Для файлов с постоянной длиной записи адрес размещения записи с номером К может быть вычислен по формуле:
ВА + (К - 1) * LZ + 1, где ВА –базовый адрес, LZ – длина записи.
На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа. Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Они могут быть организованы двумя способами:
Конец записи отличается специальным маркером.
Запись 1
X
Запись 2
X
ЗаписьЗ
X
В начале каждой записи записывается ее длина.
LZ1
Запись1
LZ2
Запись2
LZ3
ЗаписьЗ
Здесь LZN — длина N-й записи.
Файлы с прямым доступом обеспечивают наиболее быстрый способ доступа. Мы не всегда можем хранить информацию в виде файлов прямого доступа, но главное – это то, что доступ по номеру записи в базах данных весьма неэффективен. Чаще всего в базах данных необходим поиск по первичному или возможному ключам, иногда необходима выборка по внешним ключам, но во всех этих случаях мы знаем значение ключа, но не знаем номера записи, который соответствует этому ключу.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение функции, которая по значению ключа однозначно вычисляет адрес (номер записи файла).
NZ = F(K), где NZ – номер записи, К – значение ключа, F( ) – функция.
В этом случае не удается построить взаимнооднозначную функцию, либо эта функция будет иметь множество незадействованных значений, которые соответствуют недопустимым значениям ключа. В подобных случаях применяют различные методы хэширования (рандомизации) и создают специальные хэш- функции.
Суть методов хэширования состоит в том, что мы берем значения ключа ( или некоторые его характеристики) и используем его для начала поиска, то есть мы вычисляем некоторую хэш-функцию h(k) и полученное значение берем в качестве адреса начала поиска. То есть мы не требуем полного взаимно-однозначного соответствия, но, с другой стороны, для повышения скорости мы ограничиваем время этого поиска (количество дополнительных шагов) для окончательного получения адреса. Таким образом, мы допускаем, что нескольким разным ключам может соответствовать одно значение хэш-функции (то есть один адрес). Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хэш-функции, называются синонимами (рис. 5.5).