· решение задач прогнозирования на основе отобранной модели.
Уяснение цели и задач прогнозирования. На этом этапе проводится детальное логическое изучение системы и процессов в ней: зависимости показателей (критериев, параметров) от подсистем (компонент процесса); определение характера, объема и способа получения необходимых исходных данных.
Подготовка исходных данных. На этом этапе собираются и проверяются исходные данные. В частности: устанавливается полнота временного ряда, доопределяются (например, путем интерполяции) необходимые исходные данные.
Фильтрация исходного временного ряда. На этом этапе устраняются случайные возмущения ("выбросы") в данных и проводится их статистическое сглаживание. Сглаживание выполняют с помощью многочленов. Например, формулыдляскользящего сглаживания по трем точкам имеют вид:
y*0=(1/3)∙(y-1 +y0+y+1); (3.4)
y*-1= (1/6)∙(5∙y-1+ 2∙y0-y+1); (3.5)
y*+1= (1/6)∙(-y-1+2∙y0+y+1), (3.6)
где: y0, y*0 - значения исходной и сглаженной функций в средней точке группы;
y-1, y*-1 - значения исходной и сглаженной функций в левой точке группы;
y+1, y*+1 - значения исходной и сглаженной функций в правой точке группы.
Примечание. Формулы (3.5) и (3.6) применяются для сглаживания крайних точек ряда, а (3.4) - для промежуточных точек ряда.
Логический отбор вида аппроксимирующей функции. На этом этапе из заданного массива функций (например, таблица 3.4) отбираются наиболее приемлемые. При этом находят ответы на следующие вопросы:
· является ли исследуемый показатель монотонно возрастающим (убывающим), стабильным (периодическим), имеет ли экстремумы;
· ограничен ли показатель сверху или снизу каким-либо пределом;
· имеет ли функция, определяющая процесс, точку перегиба;
· симметрична ли анализируемая функция;
· имеет ли процесс ограничение развития во времени.
Примечание. Перечисленные вопросы могут быть успешно решены при наглядном (графическом) сопоставлении функции, построенной по исходным данным с графиками типовых аппроксимирующих функций.
Оценка математической модели прогнозирования. На этом этапе определяются параметры (коэффициенты) отобранных аппроксимирующих функций. Наиболее известным методом оценки параметров являются: МНК и его модификации, метод экспоненциального сглаживания.
МНК состоит в определении параметров такой модели тренда, которая минимизирует ее отклонение от точек исходного временного ряда:
n
S= ∑ (y*i-y i)2 → min,
i = 1
где: y*i - расчетные значения исходного ряда;
y i - фактические значения исходного ряда;
n - число наблюдений.
Классический МНК предполагает равноценность информации в исходном ряде, однако в прогнозных моделях должно быть учтено следующее: будущее поведение процесса в большей степени определяется поздними наблюдениями, чем ранними. То есть, МНК для прогнозных моделей должен предполагать дисконтирование (уменьшение ценности более ранней информации).
Дисконтирование учитывают путем введения в вариационный ряд весовых коэффициентов βi< 1. Тогда модифицированный вариант МНК будет иметь вид:
n
S = ∑ [βi∙(y*i-y i)2]→ min.
i = 1
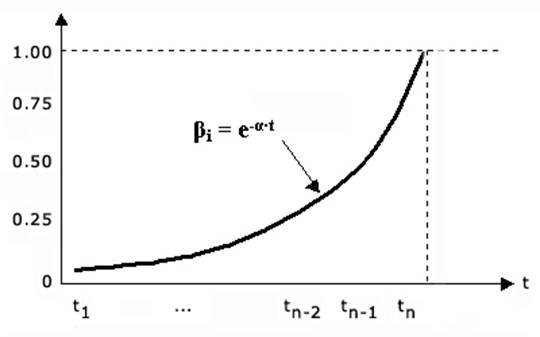
Коэффициенты βi могут быть заданы в числовом виде или в виде функциональной зависимости таким образом, чтобы по мере продвижения по ряду в прошлое веса убывали. Задание функциональной зависимости коэффициентам βi может быть обеспечено при использовании метода экспоненциального сглаживания,обеспечивающего "сглаживание" исходного ряда посредством весовых коэффициентов, подчиняющихся экспоненциальному закону (рис. 3.2).
Для данного метода весьма важно грамотно выбрать значение параметра экспоненциального сглаживания α (чем больше α, тем больше вклад последних наблюдений в формирование тренда. При малом α - большее число членов ряда реально "участвуют" в формировании тренда). В первом приближениирациональная величинаα может быть определена из соотношения Брауна:
α= 2 / (n+ 1),
или из соотношения Мейера
α=σм/σр,
где: n - число наблюдений;
σм-СКО модели;
σр - СКО исходного ряда наблюдений.
Выбор математической модели прогнозирования. На этом этапе из предварительно отобранных моделей выбирается окончательный вариант прогнозной модели. При этом качество моделей определяется на основе использования свойств остаточной компоненты: (yi-yτi),i= 1,…,n, то есть величины расхождений на участке аппроксимации между фактическими уровнями и их расчетными значениями.
Качество модели определяется адекватностью исследуемому процессу и точностью (по существу - степенью близости к фактическим данным).
Проверки моделей на адекватность выполняют с использованием:
· критерия Дарбина-Уотсона d;
· коэффициента автокорреляции ra;
· критерия поворотных точек ("пиков" и "впадин") К;
· коэффициентов ассиметрии А и эксцесса Э;
· RS-критерия.
Эти проверки достаточно сложны, поэтому далее они не рассматриваются.
При оценке точности прогнозных моделей широко используют следующие показатели:
где в (3.7), (3.8) и (3.9):n - число наблюдений в ряде;
p - число коэффициентов в модели;
y i - фактические значения исходного ряда;
f(xi)- расчетные значения исходного ряда;
· ширина доверительного интервала в точке прогнозаΔY вычисляется последовательно, в несколько шагов. Так, на первом шаге задаются величиной доверительной вероятности p (из ряда 0.9, 0.95, 0.975, 0.99), а на втором шаге - рассчитывают число степеней свободы по формуле:
V=n-m- 1,
где: n - число наблюдений в ряде;
m - число коэффициентов в модели.
На третьем шаге для каждого h-го коэффициента прогнозной модели рассчитывают верхнюю a hв и нижнюю а hн доверительные границы по формулам:
a hв=a h+t т; a hн =a h-t т,
где: a h - точечная оценка h-го коэффициента прогнозной модели;
t т- теоретическое значение t-критерия Стьюдента для доверительной вероятности p и числа степеней свободы V (определяется по таблице квантилей t-распределения).
На четвертом шаге дважды рассчитывается значение прогноза Y (вначале, со значениями нижних доверительных границ коэффициентов модели, определяется Yн, а затем, со значениями верхних доверительных границ коэффициентов модели, определяется Yв).
На пятом шаге рассчитывается ширина доверительного интервала прогноза по формуле:
ΔY=Yв-Yн.
По совокупности всех оценок точности выбирают окончательный вариант прогнозной модели. Наилучшим по точности будет тот вариант модели, у которого все перечисленные выше показатели (S1,f(x), mα, B, ΔY) будут наименьшими.
Решение задач прогнозирования. На этом этапе с помощью сформированной модели решаются конкретные задачи прогнозирования. При этом необходимо помнить, что корректное прогнозирование возможно лишь при умеренной глубине прогноза (краткосрочный прогноз). Среднесрочные и долгосрочные прогнозы выполняются при использовании сложных моделей, которые здесь не были рассмотрены.
Примечание. К краткосрочным прогнозам относят прогнозы с глубиной не более 5…10 % от интервала времени, охваченном временным рядом, использованным при формировании прогнозной модели.