В ряде случаев математические модели формируются на результатах наблюдений (опытов, измерений). При этом, возникает очевидная необходимость установить закон распределения накопленных данных.
Простейшим способом установления закона распределения является графический способ, по которому:
· строится график распределения;
· график сравнивается с эталонными графиками известных законов распределения;
· путем визуального сравнения выдвигается гипотеза о виде закона распределения;
· эта гипотеза проверяется с использованием специальных критериев.
Такой подход требует умения строить графические модели вариационных числовых рядов, в частности, - гистограмму и статистическую функцию распределения. Эти модели являются статистическими (эмпирическими) аналогами интегральной F(x) и дифференциальной f(x) функций распределения случайной величины X.
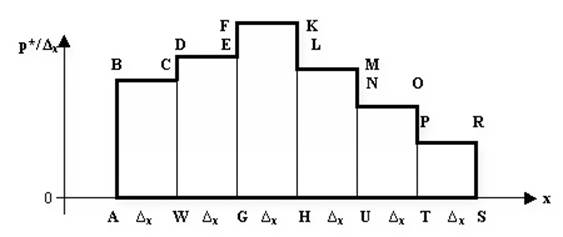
Гистограмма распределения - представляет собой многоугольник, построенный с помощью смежных прямоугольников. В случае непрерывных и равных интервалов шириной Дx гистограмма строится следующим образом (рис. 2.1). В выбранных масштабах на оси абсцисс наносится шкала для реализаций случайной величины X, а на оси ординат - величины p* / Дx. Пользуясь этими шкалами, строят прямоугольники ABCD,DEFG,…, основания которых соответствуют ширине интервала Дx, а высоты равны отношениям
p*1 /Дx, p*2 / Дx,…,p*k /Дx. Многоугольник ABCEF … ORTJA и является искомой гистограммой распределения.
Рис. 2.1. Гистограмма распределения случайной величины X
При уменьшении величины каждого интервала гистограмма будет приближаться к некоторой плавной кривой, соответствующей графику функции плотности распределения f(x) случайной величины X. Следовательно, строя гистограмму можно получить представление о дифференциальной функции распределения случайной величины X.
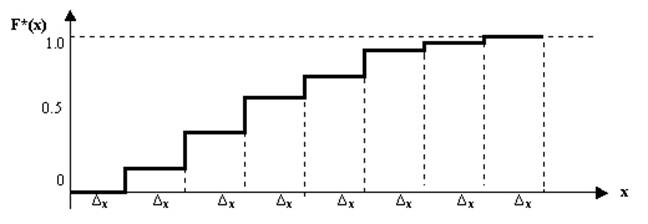
Статистическая функция распределения-представляет собой частоту событий X < x в данной выборке (вариационном ряде):
F*(x) =P*(X<x) =∑ p*(X<xi),
xi < x
где: x - текущая переменная;
p*- частота (статистическая вероятность) события.
Неравенство X<xiпод знаком суммы указывает, что суммирование распространяется на все те значения xi, которые меньше Х. Значение F*(x) при данном значении xi определяется по формуле:
F*(x) = ni / n,
где ni - число опытов (наблюдений), при которых X<xi.
При неограниченном увеличении числа опытов (наблюдений) n частота события p*(X<xi) приближается (сходится по вероятности) к вероятности этого события. Следовательно, если X - непрерывная величина, то при увеличении n график функции F*(x) приближается к плавной кривой F(x) - интегральной функции распределения случайной величины X.
Статистическая функция F*(x) строится следующим образом (рис. 2.2). На каждом отрезке оси абсцисс (Дx), изображающем расстояние между концами интервалов, проводится отрезок горизонтальной прямой на уровне ординаты, равной величине накопленной (нарастающим итогом) частоты; концы горизонтальных отрезков соединяются вертикальными линиями.
Рис. 2.2. Статистическая функция распределения величины X
При построении графических аналогов вариационных рядов важным является выбор оптимальной длины интервалов Дxи числа интервалов k. Эти параметры могут быть определены по формулам:
Дx= (xmax-xmin) / (1 + 3.21∙lg n),
k= (xmax-xmin) /Дx,
где xmax - xmin -размах вариации случайной величины X.
Исходные данные, необходимые для построения графиков вариационных рядов непрерывных (интервальных) величин удобно представлять в виде таблицы 2.2, в которой в верхней строке, вместо дискретных значений xi, указываются интервалы наблюдений.
Таблица 2.2
t1…t2
…
t i…ti+1
…
tk…tk+1
p*1
…
p*i
…
p*n
Примечание. Частоты попадания случайной величины X в i-ый интервал определяются по формуле:
p*i = mi/n,
где: mi - количество значений случайной величины X, приходящихся на i-ый интервал;
n - общее число опытов (наблюдений).
Характер протекания интегральной и дифференциальной функций в наиболее употребительных (при моделировании) законах распределения рассмотрен ниже.