В этом случае в структуре http-канала будут находиться такие провайдеры (и соответствующие им приемники):
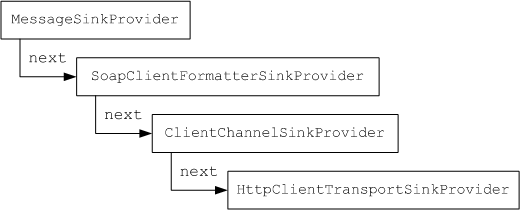
Рис. 9. Провайдеры в структуре http-канала
Обратите внимание: среди провайдеров имеется стандартный, отвечающий за SOAP-форматирование, а последний провайдер – это элемент http-канала. Подчеркнем, что порядок объявления провайдеров имеет значение.
Работу с канальными приемниками рассмотрим на нескольких примерах. В первом примере создадим серверный приемник для протоколирования сообщений. Начнем с рассмотрения интерфейса System.Runtime.Remoting.Channels.IServerChannelSink.
public interface IServerChannelSink {
IServerChannelSink NextChannelSink { get; }
ServerProcessing ProcessMessage(
IServerChannelSinkStack sinkStack,
IMessage requestMsg,
ITransportHeaders requestHeaders,
Stream requestStream,
out IMessage responseMsg,
out ITransportHeaders responseHeaders,
out Stream responseStream);
void AsyncProcessResponse(
IServerResponseChannelSinkStack sinkStack,
object state,
IMessage msg,
ITransportHeaders headers,
Stream stream);
Stream GetResponseStream(
IServerResponseChannelSinkStack sinkStack,
object state,
IMessage msg,
ITransportHeaders headers);
}
Свойство NextChannelSink содержит ссылку на следующий канальный приемник в цепочке. Оно устанавливается конструктором класса-приемника.
Метод ProcessMessage() – основной метод при синхронной обработке сообщений и потоков. Его параметры:
· requestHeaders – транспортные заголовки сообщения-запроса. Это таблица пар «ключ-значение». При помощи заголовка к сообщению можно присоединять дополнительную описательную информацию;
· requestStream – поток, который следует обработать и направить в десериализатор;
· responseMsg – после выполнения метода удаленного объекта этот параметр содержит возвращаемый IMessage;
· responseHeaders – после выполнения метода удаленного объекта этот параметр содержит транспортные заголовки возвращаемого сообщения (если они есть);
· responseStream – параметр содержит поток, направляемый клиенту после выполнения метода удаленного объекта.
При реализации тела метода ProcessMessage() нужно действовать по такой схеме. Вначале производится предварительная обработка сообщений или потоков[21]. После этого обработчик помещается в стек (sinkStack). Стек используется для асинхронной обработки. Затем следует вызвать метод обработки у следующего приемника в цепочке. Далее производится пост-обработка сообщений или потока.
Метод ProcessMessage() возвращает значение из перечисления ServerProcessing:
· Async – вызов обработан асинхронно, и приемник должен сохранить возвращаемые данные в стеке для дальнейшей обработки;
· Complete – сервер обработал сообщение в нормальном, синхронном режиме;
· OneWay – сообщение было обработано, ответ высылаться не будет.
Метод AsyncProcessResponse() возвращает ответ сервера при обработке асинхронного сообщения. Параметры метода:
public Stream GetResponseStream(...) { return null; }
public ServerProcessing ProcessMessage(. . .) {
IMethodCallMessage msg =
(IMethodCallMessage) requestMsg;
Console.WriteLine("[{0}]: {1}",
DateTime.Now.ToString(),
msg.MethodName);
foreach (DictionaryEntry de in requestHeaders) {
Console.WriteLine("KEY: {0} VALUE: {1}",
de.Key, de.Value);
}
sinkStack.Push(this,null);
ServerProcessing srvProc =
nextSink.ProcessMessage(sinkStack,
requestMsg,
requestHeaders,
requestStream,
out responseMsg,
out responseHeaders,
out responseStream);
IMethodReturnMessage msg_ret =
(IMethodReturnMessage) responseMsg;
Console.WriteLine("[{0}]: {1} - return {2}",
DateTime.Now.ToString(),
msg_ret.MethodName,
msg_ret.ReturnValue);
return srvProc;
}
}
}
Дадим комментарии по коду класса. Наш класс LogSink является наследникам класса BaseChannelSinkWithProperties. Дело в том, что интерфейс IServerChannelSink (как и IClientChannelSink) наследуется от интерфейса IChannelSinkBase, имеющего единственное свойство – словарь Properties. Абстрактный класс BaseChannelSinkWithProperties предоставляет реализацию данного свойства.
Конструктор класса LogSink не выполняет никаких особых действий. Он просто устанавливает указатель на следующий канальный приемник. Вызывать данный конструктор будет провайдер нашего приемника, который и передаст требуемое значение параметра.
Основная логика работы класса сосредоточена в методе ProcessMessage(). Получив сообщений, метод производит вывод на консоль информации о нем. Кроме этого, выводятся данные транспортных заголовков сообщения. Затем объект-приемник помещается в стек. После обработки сообщение передается в следующий канальный приемник. Если этот канальный приемник завершил свою работу, то это значит, что можно производит обработку возвращаемого клиенту сообщения. Об этом сообщении также выводится некоторая информация на консоль.
Метод AsyncProcessResponse() по сути содержит логику пост-обработки сообщения, а затем передает сообщение дальше по цепочке. Так как наш приемник не создает особого потока по сообщению, метод GetResponseStream() просто возвращает null.
Для установки серверного канального приемника необходимо написать класс, реализующий IServerChannelSinkProvider:
Свойство Next хранит ссылку на следующий провайдер в цепочке. В методе CreateSink() создается объект, соответствующий пользовательскому канальному приемнику. При этом в начале вызывается метод для создания стека приемников, а затем пользовательский приемник помещается на вершину стека. При помощи метода GetChannelData() можно получить различные характеристики того канала, с которым ассоциирован приемник.
Создадим провайдер приемника для нашего примера. Поместим его в ту же сборку, что и класс-приемник. Код провайдера приведен ниже:
namespace MySink {
public class LogSinkProvider: IServerChannelSinkProvider {
private IServerChannelSinkProvider nextProvider;
public LogSinkProvider(IDictionary properties,
ICollection providerData) { }
public IServerChannelSinkProvider Next {
get { return nextProvider; }
set { nextProvider = value; }
}
public IServerChannelSink CreateSink(
IChannelReceiver channel) {
IServerChannelSink next =
nextProvider.CreateSink(channel);
return new LogSink(next);
}
public void GetChannelData(
IChannelDataStore channelData) { }
}
}
В классе LogSinkProvider задан пустой конструктор. Наличие у провайдера конструктора с подобной сигнатурой является обязательным требованием. При помощи таких конструкторов можно извлечь данные для настройки провайдера, хранящиеся, например, в конфигурационном файле. Реализация остальных методов типична для провайдера.
Использование указанного канального приемника происходит при помощи следующего конфигурационного файла сервера. Для провайдера указывается его тип (включая имя пространства имен) и имя сборки.
Рассмотрим другой пример. Пусть требуется производить шифрование потока, передаваемого от сервера к клиенту и наоборот. Для этого требуется реализовать канальные приемники, работающие с потоком, на стороне клиента и на стороне сервера. В нашем учебном примере «шифрование» будет выполняться как применение к каждому байту потока побитовой операции XOR с некой константой.
Начнем с реализации клиентского канального приемника. Рассмотрим интерфейс IClientChannelSink.
Основное отличие этого интерфейса от интерфейса IServerChannelSink заключается в наличие отдельных методов для осуществления асинхронного запроса и получения асинхронного ответа. Кроме этого, метод ProcessMessage() не работает со стеком объектов-приемников. В остальном (включая схему использования) интерфейс практически аналогичен IServerChannelSink.
Код клиентского канального приемника EncClientSink представлен ниже (для краткости опущены формальные параметры методов):
using System;
using System.Runtime.Remoting.Channels;
using System.Runtime.Remoting.Messaging;
using System.IO;
using System.Collections;
namespace Encryption {
public class EncClientSink: BaseChannelSinkWithProperties,
Для осуществления шифрования и дешифровки клиентский канальный приемник (равно как и серверный) используют методы вспомогательного класса EncriptionHelper.
namespace Encryption {
public class EncriptionHelper {
public static Stream GetEncryptedStreamCopy(Stream inStream) {
Stream outStream = new MemoryStream();
byte[] buf = new byte[1000];
int cnt = inStream.Read(buf,0,1000);
while (cnt > 0) {
for (int i = 0; i < cnt; i++) { buf[i] ^= 123; }
outStream.Write(buf,0,cnt);
cnt = inStream.Read(buf,0,1000);
}
outStream.Position = 0;
return outStream;
}
public static Stream GetDecryptedStreamCopy(Stream inStream) {
// В нашем случае дешифровка и шифровка симметричны
return GetEncryptedStreamCopy(inStream);
}
}
}
Нам необходим клиентский канальный провайдер. Это должен быть класс, реализующий интерфейс IClientChannelSinkProvider:
Обратите внимание на порядок, в котором провайдеры размещены на клиенте и сервере.
Рассмотрим некоторые возможности расширения предыдущего примера. Представим ситуацию, согласно которой не все клиенты реализуют шифрование. Как на стороне сервера различать клиентов? Решение может быть следующим. Клиент с шифрованием внедряет в заголовок транспортного протокола некоторую служебную информацию, а сервер анализирует ее и либо выполняет дешифровку, либо нет.
Работа с заголовком транспортного протокола выполняется как с таблицей «ключ-значение». По соглашению имена пользовательских ключей в заголовке принято начинаться с "X". Вот как могут выглядеть измененные методы на клиенте:
В коде серверного приемника метод ProcessMessage() должен поместить информацию о том, является ли поток зашифрованным в стек обработчиков, чтобы она могла быть извлечена при асинхронной обработке:
В методе AsyncProcessResponse() на сервере анализируется значение параметра state. Если этот параметр указывает на то, что принятое сообщение было зашифровано, ответ шифруется и в транспортный заголовок помещается необходимая информация:
Практически в любом серьезном приложении возникает необходимость работы с базами данных (БД). Обычно для этого используются некие стандартные интерфейсы и библиотеки, вместе составляющие технологию работы с БД. Примерами таких технологий являются ODBC, JDBC, OLE DB, ADO. При создании платформы .NET фирма Microsoft представила новую технологию доступа к данным – ADO.NET. Особенностями ADO.NET являются интеграция с XML и ориентированность на рассоединенные данные. Последнее означает, что для обработки данных в приложении не требуется постоянное соединение с БД. Данные перемещаются в специальную структуру для хранения и соединение с базой разрывается. Данные обрабатываются в спецструктуре, далее устанавливается соединение, и обновленные данные «закачиваются» обратно в базу.
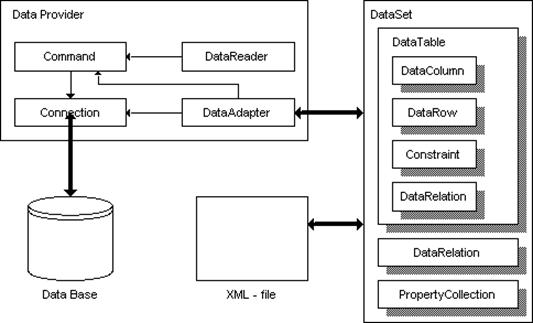
Рассмотрим общую схему архитектуры ADO.NET, показанную на рис. 10.
Рис. 10. Общая схема архитектуры ADO.NET
Одним из основных элементов архитектуры является поставщик (провайдер) данных (data provider). Поставщик данных – это совокупность классов, предназначенных для непосредственного взаимодействия с базой. Поставщики данных не универсальны, они специфичны для каждой СУБД: Oracle, MS SQL Server, MySQL и т. д. Унификация поставщиков достигается благодаря тому, что классы любого поставщика реализуют некие стандартные интерфейсы. С платформой .NET 1.0 инсталлируются два поставщика: поставщик OLE DB и поставщик для Microsoft SQL Server. Классы данных поставщиков находятся в пространствах имен System.Data.OleDb и System.Data.SqlClient соответственно. Кроме этого, пространство имен System.Data.SqlTypes содержит структуры для описания типов, используемых в СУБД SQL Server.
Любой поставщик данных содержит четыре основных класса[22]: Connection, Command, DataReader и DataAdapter. Назначение класса Connection – установка и поддержка соединения с базой данных. Класс Command служит для выполнения запросов и команд. Можно выполнить как команды, не возвращающие данных (например, создание таблицы в базе), так и запросы, возвращающие скалярное значение или набор данных (SELECT). В последнем случае для чтения данных, полученных командой, используется объект класса DataReader – ридер. Отличительной чертой ридера является то, что он представляет собой однонаправленный курсор данных в режиме «только-для-чтения». Класс DataAdapter служит своеобразным «мостом» между поставщиком данных и рассоединенным набором данных. Этот класс содержит четыре команды для выборки, обновления, вставки и удаления данных.
Вторым важным элементом ADO.NET является набор классов, представляющих рассоединенный набор данных из базы. Главным компонентом данного набора является класс DataSet, агрегирующий объекты остальных классов. Класс DataTable служит для описания таблиц базы. Класс DataRelation описывает связи между таблицами. Класс PropertyCollection представляет произвольный набор пользовательских свойств. Элементами класса DataTable являются объекты классов DataColumn (колонки таблицы), DataRow (строки таблицы) и Constraint (ограничения на значения элементов таблицы).
4.2. Учебная база CD Rent
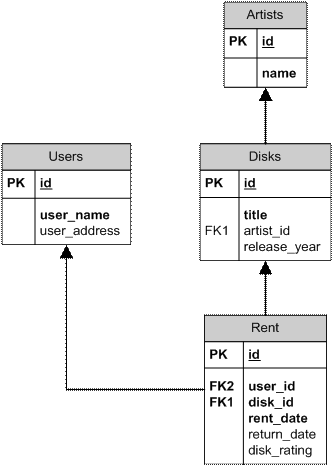
Опишем простую базу данных, которая будет использоваться в примерах. Назначение базы CD_Rent – хранить информацию о компакт-дисках и о том, кому и когда был предоставлен диск. База состоит из четырех таблиц:
1. Artists. Хранит информацию об исполнителях. Информация о колонках таблицы:
· id – первичный ключ, тип данных: int[23];
· name – имя исполнителя, тип данных: varchar(50).
2.Disks. Таблица содержит информацию о дисках:
· id – первичный ключ, тип данных: int;
· title – название альбома, тип данных: varchar(50);
· artist_id – идентификатор исполнителя, тип данных: int;
· release_year – год выпуска альбома, тип данных: char(4), допустимы пустые значения.
3. Users. Таблица с описанием пользователей (тех, кто берет диски):
· id – первичный ключ, тип данных: int;
· user_name – имя пользователя, тип данных: varchar(50);
· user_address – адрес пользователя, тип данных: varchar(50), допустимы пустые значения.
4. Rent. Данная рабочая таблица содержит информацию о том, какой диск кем был взят и когда был возвращен:
· id – первичный ключ, тип данных: int;
· user_id – идентификатор пользователя, тип данных: int;
· disk_id – идентификатор диска, тип данных: int;
· rent_date – дата, когда взяли диск, тип данных: datetime(8);
· return_date – дата, когда вернули диск, тип данных: datetime(8), допустимы пустые значения;
· disk_rate – рейтинг популярности диска, тип данных: float(8), допустимы пустые значения;
Схема связей между таблицами в базе представлена на диаграмме 11.
Рис. 11. Связи между таблицами в базе CD_Rent
4.3. Соединение с базой данных
Любое действие с базой данных начинается с подключения к базе. Аналогией может служить разговор по телефону. Прежде чем получить некую информацию, необходимо набрать номер, установить соединение, представиться, а лишь только затем обращаться с запросом. В ADO.NET поставщики данных предоставляют собственные классы для описания соединений с базой данных:
· Класс System.Data.SqlClient.SqlConnection используется для соединения с базами данных SQL Server (версии 7.0 или более поздней);
· Класс System.Data.OleDb.OleDbConnection позволяет подключиться к базам данных через интерфейс OLE DB.
Любой класс соединения реализует интерфейс System.Data.IDbConnection. Свойства и методы данного интерфейса перечислены в таблице 21. Наиболее важными являются свойство ConnectionString и методы Open() и Close(). Все свойства интерфейса IDbConnection – это свойства только для чтения, за исключением ConnectionString.
Таблица 21
Элементы интерфейса IDbConnection
Свойство или метод IDbConnection
Описание
ConnectionString
Строка, описывающая параметры подключения к базе данных
ConnectionTimeout
Время ожидания открытия подключения (в секундах) перед тем, как возникнет исключение «Невозможно подключиться к базе». По умолчанию – 15 секунд, ноль соответствует бесконечному ожиданию. Значение устанавливается строкой подключения
Database
Имя базы данных, к которой подключаемся. Значение устанавливается строкой подключения, но может быть изменено вызовом метода ChangeDatabase(). Не все поставщики поддерживают это свойство
State
Элемент перечисления ConnectionState. Поддерживаются ConnectionState.Open и ConnectionState.Closed
BeginTransaction()
Метод начинает транзакцию в базе данных
ChangeDatabase()
Устанавливает новую базу данных для использования. Является аналогом команды USE в SQL Server. Поставщики для СУБД Oracle не поддерживают этот метод
CreateCommand()
Возвращает объект, реализующий интерфейс IDbCommand (команду), но специфичный для конкретного поставщика данных
Open() и Close()
Попытка соединиться и разъединиться с источником данных
Конкретные поставщики данных могут добавлять дополнительные свойства и методы в класс Connection. Например, класс SqlConnection имеет свойство ServerVersion (строка с информацией о версии СУБД), свойство WorkstationId (строка, идентифицирующая подключившегося клиента), свойство PacketSize (размер пакета обмена с сервером в байтах). Также этот класс (как впрочем, и класс OleDbConnection) поддерживает событие StateChange, которое генерируется при открытии или закрытии соединения, и событие InfoMessage, возникающее, если сервер БД послал строку с предупреждением или ошибкой.
Строка подключения служит для указания параметров подключения к базе данных. В строке через точку с запятой перечислены пары вида «имя параметра=значение параметра». В таблице 22 перечислены некоторые возможные параметры подключения. Не все из них являются обязательными для указания, некоторые специфичны для определенных поставщиков данных. Через наклонную черту указаны возможные альтернативные названия параметров.
Таблица 22
Параметры строки подключения
Имя параметра
Описание параметра
AttachDBFilename /
Initial File Name
Используется при подключении к базе данных, представленной файлом (например, файл .mdf). Обычно вместо этого параметра используется параметр Initial Catalog
Connect Timeout /
Connection Timeout
Время ожидания подключения в секундах. Если подключение не осуществлено по истечении этого времени, генерируется исключение. Значение по умолчанию – 15 секунд
Data Source / Server/
Address / Addr /
Network Address
Имя или сетевой адрес сервера. Для локальных серверов используется значение localhost
Initial Catalog /
Database
Имя базы данных
Integrated Security/
Trusted_Connection
По умолчанию равно false. Если установлено в true или SSPI, поставщик данных пытается подключиться к серверу, используя имя и пароль пользователя в системе Windows
Persist Security Info
Если установлено в false (по умолчанию), критическая в плане безопасности информация (например, пароль) удаляется из свойства ConnectionString сразу после осуществления подключения
User ID
Идентификатор пользователя базы данных
Password/Pwd
Пароль пользователя базы данных
Строка подключения к SQL Server может иметь несколько дополнительных параметров, перечисленных в таблице 23.
Таблица 23
Дополнительные параметры строки подключения к MS SQL Server
Имя параметра
Описание параметра
Current Language
Язык, используемый SQL Server (при сортировке и т. п.)
Network Library / Net
Сетевая библиотека, которая используется для подключения к SQL Server. Поддерживаемые значения: dbnmpntw (именованные каналы), dbmsrpcn (мультипротокол), dbmsadsn (Apple Talk), dbmsgnet (VIA), dbmsipcn (Shared Memory), dbmsspxn (IPX/SPX) и dbmssocn (TCP/IP) (используется по умолчанию)
Packet Size
Размер в байтах сетевого пакета для обмена с сервером (по умолчанию – 8192 байт)
Workstation ID
Имя рабочей станции, подключающейся к серверу (по умолчанию – это имя компьютера клиента).
Параметры, специфичные для строк подключения других поставщиков данных, в данном курсе лекций не рассматриваются.
Как задать строку подключения? Это можно сделать, либо указав строку как параметр конструктора объекта соединения, либо при помощи свойства ConnectionString. Естественно, строка подключения задается до вызова у соединения метода Open().
Рассмотрим примеры кода, в которых создается соединение c БД. В случае поставщика данных SQL Server подключение может быть выполнено следующим образом:
SqlConnection con = new SqlConnection("Data Source=(local);" +
"Initial Catalog=Northwind;" +
"user id=userid;" +
"password=password");
con.Open();
Для SQL Server обязательным является задание в строке подключения источника данных (Data Source), имени базы (Initial Catalog) и способа аутентификации. Можно применять два способа аутентификации. Если база данных использует аутентификацию SQL Server (как в примере), то передается идентификатор пользователя и пароль. Сервер БД может использовать встроенную Windows-аутентификацию. Тогда в строке подключения указывается "Integrated Security=SSPI".
Еще два примера показывают подключение к базе при помощи провайдера OLE DB. Данный провайдер можно использовать для работы с SQL Server. В этом случае строка подключения выглядит так:
OleDbConnection con = new OleDbConnection(
"Data Source=(local);" +
"Initial Catalog=Northwind; " +
"user id=sa;password=secret;" +
"Provider=SQLOLEDB");
Как правило, провайдер OLE DB используют для работы с менее мощными СУБД. Следующий пример демонстрирует соединение с базой данных Access через поставщика Jet:
OleDbConnection con = new OleDbConnection(
"Data Source=localhost;" +
"Initial Catalog=c:\Nortwdind.mdb;"+
"Provider=Microsoft.Jet.OLEDB.4.0");
Приведем два совета, касающихся подключения к базам. Во-первых, строка подключения обычно не прописывается в коде программы, а берется из конфигурационного файла. Во-вторых, не забывайте закрывать подключения к базам, так как некоторые СУБД имеют лимит на количество одновременных подключений клиентов.
Для увеличения производительности приложений поставщики данных могут поддерживать пул соединений (connection pool). Сущность пула заключается в следующем. При вызове метода Close() соединение с базой не разрывается, а помещается в буфер. Если приложение захочет открыть соединение, аналогичное существующему в буфере, то система возвращает открытое подключение из пула[24]. Какие подключения считаются «аналогичным», зависит от поставщика данных. Например, провайдер для MS SQL Server требует буквального совпадения строк подключения с точностью до символа.
Настройка пула соединений выполняется при помощи параметров в строке подключения. Для поставщика SQL Server можно использовать параметры, перечисленные в таблице 24.
Булево выражение, определяет необходимость использования пула. Значение по умолчанию – true
Min Pool Size
Минимальное число соединений в пуле в любой момент времени (по умолчанию – 0)
Max Pool Size
Максимальное число соединений в пуле (по умолчанию – 100). Если достигнут лимит соединений, клиент ждет до тех пор, пока не появиться свободное соединение или пока не истечет таймаут установки соединения
Connection Lifetime
Время жизни открытого соединения в пуле (в секундах). Значение по умолчанию – 0, это означает, что Connection Lifetime = Connect Timeout
В заключение данного параграфа рассмотрим вопросы, связанные с обработкой ошибок при работе с базами данных. Управляемые поставщики обычно содержат специальные классы, описывающие исключения. В стандартных поставщиках SQL Server и OLE DB имеются классы SqlException и OleDbException. В каждом из этих классов есть свойство Errors, которое является набором объектов типа SqlError или OleDbError. В данных объектах содержится дополнительная информация об определенном исключении, полученная от базы данных. Использование обсуждаемых классов демонстрирует следующий код:
try {
. . .
}
catch (SqlException ex) {
string error = "";
error += ex.Message;
foreach (SqlError err in ex.Errors) {
error += "Message: " + err.Message + "\n" +
"LineNumber: " + err.LineNumber + "\n" +
"Source: " + err.Source + "\n" +
"Procedure: " + err.Procedure + "\n";
}
}
4.4. Выполнение команд и запросов к базе данных
Работа с базой данных основана на выполнении запросов. Запросы принято классифицировать по следующей схеме:
1. Запросы, не возвращающие данных. Такие запросы часто называют командным (action query). Основных видов командных запросов два:
· DML-запросы (Data Manipulation Language, язык управления данными). Они изменяют содержимое базы. Вот несколько примеров DML-запросов:
UPDATE Customers SET CompanyName = 'NewCompanyName'
WHERE CustomerID = 'ALF'
INSERT INTO Customers (CustomerID, CompanyName)
VALUES ('NewID', 'NewCustomer')
DELETE FROM Customers WHERE CustomerID = 'ALF'
· DDL-запросы (Data Definition Language, язык определения данных). Эти запросы изменяют структуру БД:
CREATE TABLE Disks ([id] [int] NOT NULL,
[title] [varchar] (50) NOT NULL,
[artist_id] [int] NULL)
DROP PROCEDURE StoredProc
2. Запросы, возвращающие данные (select query). Эти запросы производят выборку данных из базы либо путем выполнения SQL-оператора SELECT, либо при помощи вызова хранимой процедуры, возвращающей некий результат (возможно, набор данных).
Для выполнения запросов любых типов в ADO.NET используются объекты класса Command (конкретное имя класса специфично для поставщика данных). Класс команды реализует интерфейс IDbCommand.
Для создания объекта Command существуют два основных способа. Первый – использование конструктора. Класс SqlCommand содержит три перегруженных конструктора: конструктор без параметров; конструктор, которому передается как параметр текст команды; конструктор, принимающий как параметры текст команды и объект-соединение:
SqlCommand cmd = new SqlCommand();
SqlCommand cmd1 = new SqlCommand("SELECT * FROM Artists");
SqlConnection con = new SqlConnection("Data Source=(local);" +
"Initial Catalog=CD_Rent;" +
"Integrated Security=SSPI");
SqlCommand cmd = new SqlCommand("SELECT * FROM Artists", con);
Второй способ – это создание команды на основе объекта Connection:
SqlConnection c = new SqlConnection();
SqlCommand cmd3 = c.CreateCommand();
В последнем случае команда автоматически связывается с соединением. Связь с соединением должна быть установлена для любой команды перед выполнением. В общем случае для этого используется свойство Connection:
SqlConnection c = new SqlConnection();
SqlCommand cmd = new SqlCommand();
cmd.Connection = c;
Свойство CommandText содержит текст команды, а свойство CommandType определяет, как следует понимать этот текст. Это свойство может принимать следующие значения:
§ CommandType.Text. Текст команды – это SQL-инструкции. Обычно такие команды передаются в базу без предварительной обработки (за исключением случаев передачи параметров). Этот тип команды устанавливается по умолчанию.
§ CommandType.StoredProcedure. Текст команды – это имя хранимой процедуры, которая находится в базе данных.
§ CommandType.TableDirect. Команда предназначена для извлечения из БД полной таблицы. Имя таблицы указывается в CommandText. Данный тип команд поддерживает только поставщик OLE DB.
Еще одну возможность для настройки команд предоставляет свойство CommandTimeout. Это время в секундах, в течение которого ожидается начало выполнения команды (по умолчанию – 30 секунд). Следует учитывать, что после начала выполнения команды данное свойство никакой роли не играет. Выполнение команды не прервется, даже если она будет получать данные из базы на протяжении, к примеру, одной минуты.
За подготовкой команды следует ее выполнение. Естественно, до выполнения команда должна быть связана с соединением, и это соединение должно быть открыто. В ADO.NET существует несколько способов выполнения команд, которые отличаются лишь информацией, возвращаемой из БД. Ниже перечислены методы выполнения команд, поддерживаемые всеми поставщиками.
· ExecuteNonQuery(). Этот метод применяется для запросов, не возвращающих данные. Метод возвращает суммарное число строк, добавленных, измененных или удаленных в результате выполнения команды. Если выполнялся DDL-запрос, метод возвращает значение -1.
· ExecuteScalar(). Метод выполняет команду и возвращает первый столбец первой строки первого результирующего набора данных. Метод может быть полезен при выполнении запросов или хранимых процедур, возвращающих единственных результат.
· ExecuteReader(). Этот метод выполняет команду и возвращает объект DataReader. Тип возвращаемого ридера соответствует поставщику. Метод ExecuteReader() используется, когда требуется получить набор данных из базы (например, как результат выполнения команды SELECT).
В качестве примера использования метода ExecuteScalar() приведем код, при помощи которого подсчитывается число записей в таблице Artists:
new SqlCommand("SELECT COUNT(*) FROM Artists", con);
con.Open();
// Приведение типов необходимо, так как метод ExecuteScalar()
// возвращает значение типа object
int count = (int) cmd.ExecuteScalar();
con.Close();
Console.WriteLine(count);
Изменим в предыдущем примере единственную строку:
SqlCommand cmd = new SqlCommand("SELECT * FROM Artists", con);
Как видим, команда настроена на получение набора данных. Однако в результате выполнения кода примера получим на консоли число 1. Это первый элемент в первой колонке id.
Поставщик SQL Server поддерживает метод, возвращающий объект класса, производного от XmlReader. Это метод ExecuteXmlReader(). Метод поддерживается для SQL Server 2000 и более поздних версий и требует, чтобы возвращаемые запросом или хранимой процедурой данные были в формате XML:
SqlConnection con = new SqlConnection();
con.ConnectionString = . . .;
SqlCommand cmd = new SqlCommand();
cmd.Connection = con;
cmd.CommandText = "SELECT * FROM Artists FOR XML AUTO";
// Открыли соединение
con.Open();
// Получили XmlReader
XmlReader xml = cmd.ExecuteXmlReader();
// Здесь как-то читаем и обрабатываем XML-данные
. . .
// Закрываем соединение
con.Close();
4.5. Чтение данных и объект DataReader
Чтение данных из базы – одна из наиболее часто выполняемых операций. В том случае, когда необходимо прочитать набор данных, используется метод ExecuteReader(), возвращающий объект DataReader (далее для краткости – просто «ридер»). Каждый поставщик имеет собственный класс для ридера, однако любой такой класс реализует интерфейс IDataReader.
Использование ридеров имеет следующие особенности. Во-первых, ридеры не создаются при помощи вызова конструктора. Единственный способ создать ридер – это выполнить метод ExecuteReader(). Во-вторых, ридеры позволяют перемещаться по данным набора строго последовательно и в одном направлении – от начала к концу. Большинство СУБД выполняют подобную «навигацию» максимально быстро. В-третьих, данные, полученные при помощи ридера, доступны только для чтения. И, наконец, на время чтения данных соответствующее соединение с базой блокируется, то есть соединение не может быть использовано другими командами, пока чтение данных не завершено.
Рассмотрим работу с ридерами на примере класса SqlDataReader. Основным методом ридера является метод Read(), который перемещает указатель на следующую запись в наборе данных и возвращает false, если записей в наборе больше нет. После прочтения всех записей у ридера необходимо вызвать метод Close(). Этот метод освобождает соединение, которое было занято ридером.
Типичный код использования ридера выглядит следующим образом:
// Стандартные подготовительные действия
SqlConnection con = new SqlConnection();
con.ConnectionString = . . .
SqlCommand cmd = new SqlCommand("SELECT * FROM Artists", con);
// Открываем соединение и получаем ридер, выполняя команду
con.Open();
SqlDataReader r = cmd.ExecuteReader();
// В цикле читаем данные (пока кода в цикле нет!)
while(r.Read()) { . . . }
// Закрываем ридер; если необходимо, закрываем соединение
r.Close();
con.Close();
Как прочитать данные, получаемые ридером? Для этого существует несколько возможностей. Первая заключается в использовании индексатора ридера, в качестве индекса выступает строка с именем столбца. Возвращаемое значение имеет тип object, поэтому, как правило, необходимо выполнять приведение типов:
// Изменяем фрагмент кода из предыдущего примера
while(r.Read()) {
int id = (int) r["id"];
Console.WriteLine(id);
}
Поиск столбца по имени регистронезависим[25]. Если соответствующего столбца в наборе данных нет, то генерируется исключение IndexOutOfRangeException.
Выполнение поиска столбца по имени требует сравнения строк и происходит медленно. Альтернативой является использование в качестве индекса номера столбца. В этом случае производительность повышается:
while(r.Read()) {
int id = (int) r[0];
Console.WriteLine(id);
}
Теоретически, использование числовых индексов вместо имен столбцов означает снижение гибкости приложения. Однако порядок столбцов в наборе данных меняется, только если меняется строка запроса или структура объекта БД (таблицы, хранимой процедуры). В большинстве приложений можно без каких-либо проблем жестко задать порядковые номера всех столбцов. Тем не менее, в некоторых ситуациях известно только имя столбца, но не его порядковый номер. Метод ридера GetOrdinal() принимает строку, представляющую имя столбца, и возвращает целое значение, соответствующее порядковому номеру столбца[26]. Это позволяет достичь компромисса между гибкостью и производительностью:
// Получаем ридер
SqlDataReader r = cmd.ExecuteReader();
// Один раз находим номер столбца по имени (а не в цикле!)
Класс SqlDataReader (как и класс OleDBDataReader) имеет ряд методов вида Get<тип данных> (например, GetInt32()). Эти методы получают в качестве параметра индекс столбца, а возвращают значение в столбце, приведенное к соответствующему типу:
SqlDataReader r = cmd.ExecuteReader();
int name_index = r.GetOrdinal("name");
while(r.Read()) {
Console.WriteLine(r.GetString(name_index));
}
Отдельные поля записей набора данных могут иметь пустые (null) значения, то есть быть незаполненными. При попытке извлечь значения из null-поля (а точнее, при попытке преобразования null-поля в требуемый тип) будет сгенерировано исключение. Ридер имеет метод IsDBNull(), предназначенный для индикации пустых полей:
if (!r.IsDBNull(id_index))
Console.WriteLine(r.GetInt32(id_index);
Некоторые СУБД и соответствующие поставщики данных позволяют выполнить запрос к базе, возвращающий несколько наборов данных. Ридер такого поставщика реализует метод NextResult(), который выполняет переход к следующему набору или возвращает false, если такого набора нет. Рассмотрим пример для SqlDataReader (обратите внимание на место вызова метода NextResult()):
// Отсутствует код создания соединения и команды
// Запрос возвращает два набора данных
cmd.CommandText = "SELECT * FROM Disks;" +
"SELECT * FROM Artists";
con.Open();
SqlDataReader r = cmd.ExecuteReader();
// Вложенные циклы, внешний – по наборам данных
do {
while(r.Read())
Console.WriteLine(r[1]);
} while(r.NextResult());
r.Close();
con.Close();
Упомянем некоторые свойства и методы класса SqlDataReader. Свойство FieldCount возвращает целое число, соответствующее числу столбцов в наборе результатов. Свойство IsClosed возвращает логическое значение, указывающее, закрыт ли ридер. Свойство RecordsAffected позволяет определить число записей, измененных запросом[27].
Метод ридера GetValues() позволяет поместить содержимое записи набора данных в массив. Если нужно максимально быстро получить содержимое каждого поля, использование метода GetValues() обеспечит более высокую производительность, чем проверка значений отдельных полей.
SqlDataReader r = cmd.ExecuteReader();
object[] data = new object[r.FieldCount];
while(r.Read()) {
// на самом деле GetValues() – функция,
// которая возвращает количество полей прочитанной записи
r.GetValues(data);
Console.WriteLine(data[1].ToString());
}
Для исследования структуры возвращаемого набора данных можно применить метод GetSchemaTable(). Этот метод создает объект DataTable, строки которого описывают столбцы полученного набора данных. Колонки таблицы соответствуют атрибутам этих столбцов[28]. Следующий пример кода выводит для каждого столбца его имя и тип:
SqlDataReader r = cmd.ExecuteReader();
DataTable tbl = r.GetSchemaTable();
foreach (DataRow row in tbl.Rows)
Console.WriteLine(row["ColumnName"] + " - " +
((SqlDbType)row["ProviderType"]).ToString());
Для таблицы Artists код выводит на консоль следующее:
id - Int
name - VarChar
Вернемся к методу ExecuteReader(). Этот метод перегружен и может принимать значения из перечисления CommandBehavior , которые перечислены в таблице 25 (допустимо использовать побитовую комбинацию значений).
Таблица 25
Значения перечисления CommandBehavior
Имя
Значение
Описание
CloseConnection
При закрытии ридера закрывается и соединение
KeyInfo
Ридер получает сведения первичного ключа для столбцов, входящих в набор результатов
SchemaOnly
Ридер содержит только информацию о столбцах, запрос фактически не выполняется
SequentialAccess
Значения столбцов доступны только в последовательном порядке
SingleResult
Ридер содержит результаты только первого запроса, возвращающего записи
SingleRow
Ридер содержит только первую запись, возвращенную запросом
Если при вызове метода ExecuteReader() передать ему константу CloseConnection, то при вызове метода Close() ридера последний вызовет метод Close() связанного с ним объекта Connection.
При использовании в качестве параметра метода ExecuteReader() константы SequentialAccess строки считываются последовательно на уровне столбцов. Например, просмотрев содержимое третьего столбца, просмотреть содержимое первого и второго столбцов уже нельзя. Данное поведение оправдано при наличии в строках длинных двоичных данных. Если не применять константу SequentialAccess, то последние будут считаны в ридер вне зависимости от того, будут они использованы или нет. Таким образом, параметр SequentialAccess помогает более эффективно работать с запросами большого количества двоичных данных, когда реально работа ведется только с их частью.
Выше было описано, как с помощью метода ридера GetSchemaTable() можно получить метаданные о столбцах набора данных. Вызвав ExecuteReader() и указав в качестве параметра константу SchemaOnly, мы фактически получим информацию схемы о столбцах, не выполняя запроса. Если указать в параметре константу KeyInfo, ридер выберет из источника данных дополнительную информацию для схемы, чтобы показать, являются ли столбцы набора ключевыми столбцами таблиц источника данных. При использовании константы SchemaOnly дополнительно указывать константу KeyInfo не требуется.
Указав в качестве параметра константу KeyInfo, мы требуем выполнить чтение данных запроса без блокировки записей в таблице базы. Если не блокировать строки при работе с ридером, то любые из них (еще не извлеченные) могут быть изменены. Чтение с блокировкой происходит по умолчанию, чтение без блокировки способно выполняться быстрее, но применять его следует с осторожностью.
Если нужно просмотреть только первую запись или первый набор результатов, возвращаемый запросом, передайте при вызове метода ExecuteReader() константу SingieRow или SingleResult соответственно. При указании константы SingieRow создается ридер, содержащий не более одной записи данных. Все прочие записи отбрасываются. При использовании SingleResult аналогичным образом отбрасываются наборы результатов.
4.6. Параметризированные запросы
Запросы к базе данных могут содержать параметры. Рассмотрим запрос со следующим текстом:
SELECT name FROM Artists WHERE id = @id
В данном примере параметром является @id, а запрос означает следующее: получить из таблицы Artists все значения колонки name таких записей, у которых колонка id равна параметру @id. Вот пример предыдущего запроса для поставщика OLE DB (маркером параметра является символ «?»):
SELECT name FROM Artists WHERE id = ?
Для работы с параметрами поставщики данных определяют особые классы (например, SqlParameter). Некоторые свойства параметров перечислены ниже (не каждый параметр требует определения всех свойств):
· ParameterName. Имя параметра. У поставщика данных SQL Server имя любого параметра предваряется символом @. Другие поставщики могут не использовать специальных имен вовсе, а определять параметры по позиции.
· DbType. Тип хранящихся в параметре данных. Перечисление DbType содержит элементы, которые можно использовать как значения данного свойства. Кроме этого, каждый поставщик имеет перечисления либо классы, более точно отражающие реальный тип данных СУБД. Например, поставщик SQL Server содержит перечисление SqlDbType.
· Size. Свойство зависит от типа данных параметра и обычно используется для указания его максимальной длины. Например, для строковых типов (VarChar) свойство Size представляет максимальный размер строки. Значение по умолчанию определяется по свойству DbType. В случае числовых типов изменять это значение не требуется.
· Direction. Данное свойство определяет способ передачи параметра хранимой процедуры. Его возможные значения – Input, Output, InputOutput и ReturnValue – представлены перечислением ParameterDirection. По умолчанию используется значение Input.
· IsNullable. Это свойство определяет, может ли параметр принимать пустые значения. По умолчанию свойство установлено в false.
· Value. Значение параметра. Для параметров типа Input и InputOutput это свойство должно быть установлено до выполнения команды, для параметров типа Output, InputOutput и ReturnValue значение свойства устанавливается в результате выполнения команды. Чтобы передать пустой входной параметр, нужно либо не устанавливать значение свойства Value, либо установить его равным DBNull.
· Precision. Определяет число знаков после запятой, использующихся для представления значений параметра. По умолчанию имеет значение 0.
· Scale. Определяет общее число десятичных разрядов для представления параметра.
· SourceColumn и SourceVersion. Данные свойства определяют способ использования параметров с объектом DataAdapter и подробнее будут рассмотрены ниже.
Любой объект команды содержит свойство Parameters, представляющее коллекцию параметров. Для доступа к параметрам в коллекции используется строковый индекс (имя параметра) или целочисленный индекс (позиция параметра).
Чтобы создать параметр можно применить один из конструкторов типа, описывающего параметр. Имеется шесть перегруженных версий конструктора, позволяющих задать некоторые свойства параметра. После создания параметр помещается в коллекцию определенной команды:
SqlCommand cmd = new SqlCommand();
cmd.CommandText = "SELECT name FROM Artists WHERE id = @id";
. . .
SqlParameter p = new SqlParameter();
p.ParameterName = "@id";
p.Direction = ParameterDirection.Input;
p.DbType = DbType.Int32;
cmd.Parameters.Add(p);
Для создания и добавления параметра часто достаточно воспользоваться одной из перегруженных версий метода Add() коллекции параметров:
cmd.Parameters.Add("@id", DbType.Int32);
Следующий пример показывает выборку данных из таблицы с использованием параметризированного запроса:
string s = "SELECT name FROM Artists WHERE id = @id";
SqlCommand cmd = new SqlCommand(s, con);
cmd.Parameters.Add("@id", DbType.Int32);
while (true) {
Console.Write("Input id: ");
cmd.Parameters["@id"].Value =
Int32.Parse(Console.ReadLine());
con.Open();
string name = (string)cmd.ExecuteScalar();
Console.WriteLine(name);
con.Close();
}
Заметим, что параметризированные запросы зачастую удобнее сформировать, воспользовавшись функциями для работы со строками (и такой метод более быстрый, чем работа с объектами-параметрами). Однако без параметров не обойтись, если речь заходит о вызове хранимой процедуры на сервере БД.
Пусть на сервере MS SQL Server описана хранимая процедура get_id:
CREATE PROCEDURE get_id @sp_name varchar(50) AS
RETURN (SELECT id FROM Artists WHERE name = @sp_name)
GO
Данная процедура получает в качестве параметра строку с именем исполнителя и возвращает идентификатор данной строки в таблице Artists[29].
Следующий код работает с хранимой процедурой при помощи параметров:
Заметим, что для удобной работы с хранимыми процедурами в клиентском приложении часто описываются специальные методы-«оболочки». Создание подобного метода оставляем читателям в качестве упражнения.
4.7. Рассоединенный набор данных
ADO.NET предоставляет возможность работы с рассоединенным набором данных. Такой набор данных реализуется объектом класса DataSet (далее для краткости – просто DataSet). DataSet не зависит от поставщика данных, он универсален. Это реляционная структура, которая хранится в памяти. DataSet содержит набор таблиц (объектов класса DataTable) и связей между таблицами (объекты класса DataRelation). В свою очередь, отдельная таблица содержит набор столбцов (объекты класса DataColumn), строк (объекты класса DataRow) и ограничений (объекты наследников класса Constraint). Столбцы и ограничения описывают структуру отдельной таблицы, а строки хранят данные таблицы.
Рис. 12. Связи между классами набора данных
Технически, отдельные компоненты DataSet хранятся в специализированных коллекциях. Например, DataSet содержит коллекции Tables и Relations. Таблица имеет коллекции Columns (для колонок), Rows (для строк), Constraints (для ограничений), ParentRelations и ChildRelations (для связей таблицы). Любая подобная коллекция обладает набором сходных свойств и методов. Коллекции имеют перегруженные индексаторы для обращения к элементу по номеру и по имени, методы добавления, поиска и удаления элементов. Методы добавления перегружены и обеспечивают как добавление существующего объекта, так и автоматическое создание соответствующего объекта перед помещением в коллекцию.
Для набора данных DataSet введем понятие схемы данных. Под схемой будем понимать совокупность следующих элементов:
· Имена таблиц;
· Тип и имя отдельных столбцов таблицы;
· Ограничения на столбцы таблицы такие как уникальность, отсутствие пустых значений, первичные и внешние ключи;
· Связи между таблицами;
· События набора данных и таблицы, которые происходят при работе со строками (аналоги триггеров в базах данных).
Схема данных может быть задана определена способами:
§ Вручную, путем создания и настройки свойств столбцов, таблиц, связей;
§ Автоматически, при загрузке данных в набор из базы;
§ Загрузкой схемы, которая была создана и сохранена ранее в XSD-файле.
Правильно созданная схема обеспечивает контроль целостности данных в приложении перед их загрузкой в базу. К сожалению, при загрузке данных из базы в пустой набор генерируется только часть схемы данных (в схеме будут отсутствовать связи между таблицами и события). Рекомендуется подход, при котором в пустом наборе программно создается полная схема, и только затем в этот набор производится считывание данных.
4.8. заполнение Рассоединенного набора данных
Каждый поставщик данных содержит класс, описывающий адаптер данных (DataAdapter). В частности, поставщик для SQL Server имеет класс SqlDataAdapter. Адаптер данных является своеобразным мостом между базой данных и DataSet. Он позволяет записывать данные из базы в набор и производит обратную операцию. В принципе, подобные действия вполне осуществимы при помощи команд и ридеров. Использование адаптера данных – более унифицированный подход.
Основными свойствами адаптера являются SelectCommand, InsertCommand, DeleteCommand и UpdateCommand. Это объекты класса Command для выборки данных и обновления базы. При помощи метода адаптера Fill() происходит запись данных из базы в DataSet или таблицу, метод Update() выполняет перенос данных в базу.
В начале работы с адаптером его нужно создать и инициализировать свойства-команды[30]. Адаптер содержит несколько перегруженных конструкторов. Варианты вызова конструктора адаптера показаны в примере:
// 1. Обычный конструктор без параметров.
// Необходимо заполнить команды вручную
SqlDataAdapter da_1 = new SqlDataAdapter();
// 2. В качестве параметра конструктора – объект-команда
SqlCommand cmd = new SqlCommand("SELECT * FROM Disks");
SqlDataAdapter da_2 = new SqlDataAdapter(cmd);
// 3. Параметры: текст запроса для выборки и объект-соединение
SqlConnection con = new SqlConnection("Server=(local);" +
"Database=CD_Rent;Integrated Security=SSPI");
SqlDataAdapter da_3 = new SqlDataAdapter(
"SELECT * FROM Disks", con);
// 4. Параметры – строка запроса и строка соединения
string s = "SELECT * FROM Disks";
string c = "Server=(local);Database=CD_Rent;Integrated Security=SSPI";
SqlDataAdapter da_4 = new SqlDataAdapter(s, c);
Любой адаптер должен иметь ссылку на соединение с базой данных. Адаптер использует то соединение, которое задано в его объектах-коммандах.
Итак, адаптер создан. Теперь можно использовать его метод Fill() для заполнения некоторого набора данных:
DataSet ds = new DataSet();
// Строго говоря, метод Fill() - функция, возвращающая
// число строк (записей), добавленных в DataSet
da.Fill(ds);
Заметим, что вызов метода Fill() не нарушает состояние соединения с БД. Если соединение было открыто до вызова Fill(), то оно останется открытым и после вызова. Если соединение было не установлено, метод Fill() откроет соединение, произведет выборку данных и закроет соединение. Так же ведут себя и все остальные методы адаптера, работающие с базой.
Поведение адаптера при заполнении DataSet зависит от настроек адаптера и от наличия схемы в объекте DataSet. Пусть при помощи адаптера заполняется пустой DataSet. В этом случае адаптер создаст в DataSet минимальную схему, используя имена и тип столбцов из базы и стандартные имена для таблиц. В результате выполнения следующего кода в ds будет создана одна таблица с именем Table[31].
string con_str = ". . .";
string cmd_text = "SELECT * FROM Disks";
SqlDataAdapter da = new SqlDataAdapter(cmd_text, con_str);
DataSet ds = new DataSet();
da.Fill(ds);
Команда выборки данных может быть настроена на получение нескольких таблиц. В следующем примере в пустой DataSet помещаются две таблицы:
string con_str = ". . .";
string cmd_text = "SELECT * FROM Disks;" +
"SELECT * FROM Artists";
SqlDataAdapter da = new SqlDataAdapter(cmd_text, con_str);
DataSet ds = new DataSet();
da.Fill(ds);
В наборе данных ds окажутся две таблицы с именами Table и Table1. Адаптер имеет свойство-коллекцию TableMappings, которое позволяет сопоставить имена таблиц базы и таблиц DataSet:
string cmd_text = "SELECT * FROM Disks;SELECT * FROM Artists";
SqlDataAdapter da = new SqlDataAdapter(cmd_text, con_str);
// Первая таблица будет в наборе данных называться Disks
da.TableMappings.Add("Table", "Disks");
// Вторая таблица будет называться Performers
da.TableMappings.Add("Table1", "Performers");
Любой элемент коллекции TableMappings содержит свойство ColumnMappings, которое осуществляет отображение имен столбцов:
Предположим, что заполняемый набор данных уже обладает некой схемой. Адаптер содержит свойство MissingSchemaAction, значениями которого являются элементы одноименного перечисления. По умолчанию значение свойства – Add. Это означает добавление в схему новых столбцов, если они в ней не описаны. Возможными значениями являются также Ignore (игнорирование столбцов, не известных схеме) и Error (если столбцы не описаны в схеме, генерируется исключение).
Использование свойства MissingSchemaAction демонстрирует следующий код:
SqlDataAdapter da = new SqlDataAdapter("SELECT * FROM Disks",
con);
// Пустой набор данных без схемы
DataSet ds = new DataSet();
// После заполнения в наборе будет схема,
// полученная по таблице базы данных
da.Fill(ds);
// сейчас будем "запихивать" в непустой набор новую таблицу
da = new SqlDataAdapter("SELECT * FROM Artists", con_str);
// 1 вариант. В таблице Table будет 13 записей
// (8 из Disks, 5 из Artists) и колонки: id, title, artist_id,
// release_year (из Disks), name (из Artists)
da.MissingSchemaAction = MissingSchemaAction.Add;
da.Fill(ds);
// 2 вариант. Получим таблицу из 13 записей, но с 4 столбцами
Если многократно выполненить метод Fill() с идентичной командой и набором данных, то в случае отсутствия в таблице DataSet первичного ключа, в таблицу заносится дублирующая информация. Если в таблице задан первичный ключ, произойдет обновление данных таблицы:
SqlDataAdapter da = new SqlDataAdapter("SELECT * FROM Disks", con);
DataSet ds = new DataSet();
da.Fill(ds);
da.Fill(ds);
В результате выполнения этого кода в DataSet будет создана одна таблица, которая содержит два одинаковых множества записей. Важно понимать этот факт, так как таблица в наборе данных может содержать ограничения (первичный ключ, уникальные значения), которые будут нарушены.
Обсудим дополнительные возможности адаптера, связанные с заполнением DataSet. Существует перегруженный вариант метода Fill(), который возвращает диапазон записей:
// Первый параметр – целевой набор DataSet,
// второй – номер стартовой записи (нумерация с нуля),
// третий – количество записей,
// четвертый – имя таблицы в целевом наборе DataSet
da.Fill(ds, 3, 10, "Disks");
Адаптер имеет метод FillSchema(), который переносит схему таблиц запроса в DataSet. Метод FillSchema() получает из базы имена и типы всех задействованных в запросе столбцов. Кроме этого, данный метод получает сведения о допустимости для столбца значений Null и задает значение свойства AllowDBNull создаваемых им объектов DataColumn. Метод FillSchema() также пытается определить на объекте DataTable первичный ключ.
Метод FillSchema() принимает как параметр объект DataSet, или DataSet и имя таблицы, или объект DataTable. Однако у FillSchema() имеется дополнительный параметр. Он позволяет указать, нужно ли применить к информации схемы параметры набора TableMappings. Можно указать любое значение из перечисления SchemaType – Source или Mapped. При значении Mapped адаптер обратится к содержимому набора TableMappings точно так же, как сопоставляет столбцы при вызове метода Fill(). Вот пример вызова FillSchema():
SqlDataAdapter da = new SqlDataAdapter("SELECT * FROM Disks", con);
DataSet ds = new DataSet();
da.FillSchema(ds, SchemaType.Source, "Disks");
Адаптер данных имеет три события:
· FillError – событие наступает, если при заполнении DataSet или DataTable адаптер столкнулся с какой-либо ошибкой;
· RowUpdating – событие наступает перед передачей измененной строки в базу данных;
· RowUpdated – событие наступает после передачи измененной записи в базу данных.
4.9. Объект класса DataColumn – колонка таблицы
Структура любой таблицы описывается свойствами ее столбцов. Столбец таблицы представлен объектом класса DataColumn. Данный класс содержит следующий набор свойств, перечисленный в таблице 26.
Таблица 26
Свойства класса DataColumn
Имя свойства
Тип
Описание
AllowDBNull
boolean
Определяет, допустимы ли в столбце пустые значения
AutoIncrement
boolean
Генерируется ли для столбца новое значение автоинкремента
AutoIncrementSeed
int
Начальное значение автоинкремента
AutoIncrementStep
int
Шаг автоинкремента
Caption
string
Заголовок столбца, отображаемый в элементах управления
ColumnMapping
MappingType
Определяет, как будет записано содержимое столбца в XML-документ
ColumnName
string
Имя столбца в таблице
DataType
Type
Тип данных столбца
DefaultValue
object
Значение по умолчанию в столбце
Expression
string
Выражение для вычисляемых столбцов
ExtendedProperties
PropertyCollection
Набор динамических свойств столбца и их значений
MaxLength
int
Максимально допустимая длина строки данных для столбца
Namespace
string
Имя пространства имен XML, используемого при загрузке и чтении столбца из XML-файла
Ordinal
int
Порядковый номер столбца в таблице
Prefix
string
Префикс пространства имен XML; используется при загрузке и чтении столбца из XML-файла
ReadOnly
boolean
Указывает, что содержимое столбца доступно только для чтения
Table
DataTable
Таблица, в состав которой входит столбец
Unique
Boolean
Должно ли быть значение в столбце уникальным в пределах таблицы
«Ручное» создание объектов-столбцов используется при самостоятельном формировании схемы DataSet. Минимально допустимая настройка столбца заключается в указании его имени и типа данных[32]. После этого столбец может быть добавлен в таблицу (при этом заполнятся свойства Ordinal и Table).
DataColumn dc = new DataColumn();
dc.ColumnName = "New Column";
dc.DataType = typeof(int);
DataTable dt = new DataTable();
dt.Columns.Add(dc);
Класс DataColumn имеет несколько перегруженных конструкторов, один из которых позволяет указать имя и тип столбца как параметры:
DataColumn dc = new DataColumn("New Column", typeof(int));
Для строк таблицы можно указать значение по умолчанию в столбце – свойство столбца DefaultValue. Если свойство AllowDBNull установлено в true, то допустимы пустые значения столбца (столбец может содержать объект класса DBNull[33]).
Свойства AutoIncrement, AutoIncrementSeed и AutoIncrementStep используются для организации автоматического приращения значений столбца (по умолчанию автоприращение не активно). Тип свойства с автоприращением должен быть целочисленным. Автоприращение может быть полезно при организации первичного ключа таблицы[34].
При работе с набором данных существует возможность сохранить набор в виде XML-документа. Свойство ColumnMapping настраивает представление столбца при сохранении. Значениями свойства выступают элементы перечисления MappingType. Следующий код обеспечивает сохранение значений столбца id в виде атрибута:
id.ColumnMapping = MappingType.Attribute;
К свойствам для поддержки работы с XML относятся также свойства Namespace и Prefix.
В любой таблице существует возможность создать вычисляемый столбец. Для этого у столбца устанавливается свойство Expression. Это строка, содержащая специальное выражение, используемое для вычисления значений столбца. Подробнее о работе с вычисляемыми столбцами смотрите в документации MSDN.
Столбец имеет свойство ExtendedProperties, которое можно рассматривать как хэш-таблицу, связанную со столбцом. Ключами такой хэш-таблицы должны является строки. Вот пример использования свойства ExtendedProperties:
// Помещаем в ExtendedProperties некоторую информацию
Для хранения столбцов класс DataTable использует свойство Columns типа DataColumnCollection. Добавлять столбцы можно по одному (метод DataColumnCollection.Add()) или целым массивом (метод DataColumnCollection.AddRange()). Кроме этого, метод Add() имеет удобную перегруженную версию, которая позволяет неявно создать столбец, указав его имя и тип:
// Создали таблицу
DataTable Artists = new DataTable("Artists");
// Добавили столбцы, которые создали и настроили до этого
Artists.Columns.Add(id);
Artists.Columns.Add(name);
DataTable Users = new DataTable("Users");
// Столбцы можно создавать при добавлении в таблицу...
Строки содержат данные таблицы. Отдельная строка представлена объектом класса DataRow. Таблица содержит коллекцию Rows типа DataRowCollection для хранения своих строк. Каждая строка обладает свойством Table, в котором хранится ссылка на таблицу, владеющую строкой.
Для создания строки применяется метод таблицы NewRow(). Метод генерирует пустую строку согласно структуре столбцов таблицы, но не добавляет эту строку в таблицу. Для добавления строки необходимо заполнить ее данными, а затем воспользоваться методом DataTable.Rows.Add(). Существует перегруженный вариант этого метода, который принимает в качестве параметра массив объектов, являющихся значениями полей строки:
// Создали пустую строку с требуемой структурой
DataRow r = Artists.NewRow();
// Заполняем ее содержимым
r["name"] = "Depeche Mode";
// Добавляем в таблицу
Artists.Rows.Add(r);
// Вариант покороче, в котором совмещены сразу три действия
Artists.Rows.Add(new object[2]{null, "Nirvana"});
Рассмотрим вопросы, связанные с редактированием строки таблицы. Прежде всего, требуется получить из таблицы строку для редактирования. В простейшем случае это можно сделать по номеру строки. Если номер строки неизвестен, то можно использовать метод Find() коллекции Rows (подробнее о поиске строк в таблице будет рассказано ниже).
// Знаем номер строки, в данном случае – получаем вторую
DataRow row = Users.Rows[1];
// Можно найти строку по значению первичного ключа
DataRow row_2 = Users.Rows.Find(1);
Любая строка имеет несколько перегруженных индексаторов (свойство Item) для доступа к своим полям. В качестве индекса может использоваться имя столбца (как в предыдущем фрагменте кода), номер столбца или объект DataColumn, представляющий столбец:
// меняем содержимое определенных полей строки
row["user_name"] = "Alex Volosevich";
row["user_address"] = "Mars";
Второй способ редактирования строки аналогичен первому, за исключением того, что добавляются вызовы методов BeginEdit() и EndEdit() класса DataRow:
row.BeginEdit();
row["user_name"] = "Alex Volosevich";
row["user_address"] = "Mars";
row.EndEdit();
Методы BeginEdit() и EndEdit() позволяют буферизировать изменения строки. При вызове EndEdit() коррективы сохраняются в строке. Если вы решите отменить их, вызовите метод CancelEdit(), и строка вернется в состояние на момент вызова BeginEdit().
Есть еще одно отличие между этими двумя способами редактирования строки. Объект DataTable предоставляет события RowChanging, RowChanged, ColumnChanging и ColumnChanged, с помощью которых удается отслеживать изменения строки или поля. Порядок наступления этих событий зависит от того, как редактируется строка – с вызовом методов BeginEdit() и EndEdit() или без них. Если вызван метод BeginEdit(), наступление событий откладывается до вызова EndEdit() (если вызывается CancelEdit() никакие события не наступают).
Третий способ изменения строки – воспользоваться свойством строки ItemArray, Как и свойство Item, ItemArray позволяет просматривать и редактировать содержимое строки. Различие свойств в том, что Item рассчитано на работу с одним полем, а ItemArray принимает и возвращает массив, элементы которого соответствуют полям.
object[] data = new object[] {null, "A. Volosevich", "Mars"};
row.ItemArray = data;
Если необходимо с помощью свойства ItemArray отредактировать содержимое лишь отдельных полей строки, воспользуйтесь ключевым словом null. В предыдущем примере первое поле строки после редактирования осталось без изменений.
Поле строки может содержать пустое значение. Проверить это помогает метод IsNull(). Как и индексатор Item, IsNull() принимает в качестве параметра имя поля, его порядковый номер или объект DataColumn. Чтобы сделать значение поля пустым, требуется использовать специальный класс DBNull:
if (!row.IsNull("user_address"))
row["user_address"] = DBNull.Value;
Чтобы удалить строку, достаточно вызвать метод Delete() объекта DataRow. После вызова метода Delete() строка помечается как удаленная, из базы она будет удалена после «закачки» содержимого DataSet в базу. Можно удалить строку из коллекции Rows таблицы, воспользовавшись методами коллекции Remove() или RemoveAt(). Первый метод принимает как параметр объект DataRow, второй – порядковый номер строки. Если строка удалена подобным образом, то при синхронизации изменений с БД, строка из базы удалена не будет.
Пусть имеется некий рассоединенный набор данных, в который помещена информация из БД. Допустим, что информация была изменена (в таблице редактировались, добавлялись или удалялись строки), и необходимо переместить содержимое набора обратно в базу. Было бы не продуктивно «перекачивать» в базу набор целиком. Более эффективный вариант – отслеживание изменений, и внесение в базу только корректирующих поправок.
Для поддержки корректирующих изменений базы каждая строка имеет состояние и версию. Состояние строки хранится в свойстве RowState и принимает следующие значения из перечисления DataRowState:
· Unchanged – строка не менялась (совпадает со строкой в базе);
· Detached – строка не относится к объекту DataTable;
· Added – строка добавлена в объект DataTable, но не существует в БД;
· Modified – строка была изменена по сравнению со строкой из базы;
· Deleted – строка ожидает удаления из базы.
В таблице 27 показано, как может изменяться состояние отдельной строки.
Таблица 27
Изменение состояния строки DataRow
Действие
Код
Значение
RowState
Создание строки, не относящейся к объекту DataTable
С помощью свойства RowState можно найти в таблице измененные строки. Кроме этого, для любой строки существует возможность просмотреть, каким было значение ее полей до изменения. Свойство строки Item имеет перегруженный вариант, принимающий значение из перечисления DataRowVersion:
· Current – текущее значение поля;
· Original – оригинальное значение поля;
· Proposed – предполагаемое значение поля (действительно только при редактировании записи с использованием BeginEdit()).
Следующий фрагмент кода изменяет содержимое поля name первой строки таблицы Artists, а затем выводит оригинальное и текущее содержимое поля:
// Заполняем таблицу из базы, чтобы была "оригинальная" версия
string con = "Server=. . .";
SqlDataAdapter da = new SqlDataAdapter("SELECT * FROM Artists", con);
При редактировании строки с использованием методов BeginEdit() и EndEdit() доступна версия с «предполагаемым» содержимым строки. После вызова EndEdit() все изменения сохраняются в текущей версии строки. Тем не менее, до этого изменения считаются отложенными, поскольку их удается отменить вызовом метода CancelEdit(). Чтобы при редактировании строки просмотреть предполагаемое значение поля, воспользуйтесь свойством Item со вторым элементом DataRowVersion.Proposed:
Таблица 28 показывает возможные значения, возвращаемые свойством Item в зависимости от указанной версии ([Искл.] обозначает генерацию исключительной ситуации при попытке получить определенную версию).
Таблица 28
Значения свойства Item в зависимости от версии строки
Пример
Current
Original
Proposed
Только что созданная строка, не связанная с таблицей
row = tbl.NewRow();
row["id"] = 10;
[Искл.]
[Искл.]
В таблицу добавлена новая строка
tbl.Rows.Add(row);
[Искл.]
[Искл.]
Данные загружены из базы, из таблицы получена существующая строка
row = tbl.Rows[0];
1[35]
[Искл.]
Первое изменение существующего поля
row.BeginEdit();
row["id"] = 100;
После первого изменения
row.EndEdit();
[Искл.]
После второго изменения содержимого поля
row.BeginEdit();
row["id"] = 300;
row.EndEdit();
[Искл.]
После отмены изменений
row.BeginEdit();
row["id"] = 500;
row.CancelEdit()
[Искл.]
После удаления записи
DataRow row = Artists.Rows[0];
row.Delete();
[Искл.]
[Искл.]
Для контроля существования версии можно использовать метод HasVersion():
if(row.HasVersion(DataRowVersion.Current))
Console.WriteLine("Current version exists");
Любая строка предоставляет методы AcceptChanges() и RejectChanges(). Вызов первого метода закрепляет в строке все отложенные изменения, а вызов второго – отбрасывает отложенные изменения. Иными словами, вызов AcceptChanges() приводит к замене значений Original-версии строки значениями из Current-версии и установке у строки RowState = Unchanged. Вызов RejectChanges() устанавливает RowState= Unchanged, но значения Current-версии строки меняются на значения Original-версии. При загрузке изменений DataSet в базу у каждой строки неявно вызывается метод AcceptChanges(). Внимание: явное использование указанных методов может породить проблемы при синхронизации набора данных и базы.
Отдельная строка таблицы, а также отдельное поле строки позволяют задать текстовую метку при наличии ошибочных значений. Метка для поля устанавливается методом SetColumnError(), а читается методом GetColumnError(). Можно пометить всю строку, используя свойство строки RowError. Если метка была указана, то свойство строки HasErrors = true. Поля с метками ошибок могут быть получены при помощи вызова метода строки GetColumnsInErrors(). Метод ClearErrors() удаляет все метки ошибок в полях строки и очищает свойство RowError. Работу с описанными методами демонстрирует следующий пример:
// Получили строку таблицы
DataRow row = Artists.Rows[0];
// После продолжительного анализа решили, что с полем name
// что-то не так; поставим метку на это поле
// (можно было использовать номер поля)
row.SetColumnError("name", "Wrong Name");
// Заодно пометим всю строку как "бракованную"
row.RowError = "Row with Errors";
// Где-то в коде: проверим-ка мы строку на предмет ошибок...
// Пройдемся по массиву и выведем информацию об ошибках
foreach (DataColumn dc in err_Columns) {
Console.WriteLine(dc.ColumnName);
Console.WriteLine(row.GetColumnError(dc));
}
// Считаем, что с ошибками разобрались; очистим сообщения
row.ClearErrors();
}
4.11. Работа с объектом класса DataTable
Любой рассоединенный набор данных содержит одну или несколько таблиц. В данном параграфе рассматривается настройка отдельной таблицы, ее свойства и методы.
Наиболее важные свойства класса DataTable приведены в таблице 29.
Таблица 29
Свойства класса DataTable
Имя свойства
Описание
CaseSensitive
Определяет, учитывается ли регистр при поиске строк в таблице (по умолчанию false – не учитывается)
ChildRelations
Возвращает коллекцию подчиненных связей для таблицы
Columns
Набор столбцов таблицы
Constraints
Набор ограничений, заданных для таблицы
DataSet
Рассоединенный набор данных, включающий таблицу
DefaultView
Указывает на представление по умолчанию (view) для таблицы
ExtendedProperties
Коллекция пользовательских свойств таблицы
HasErrors
Указывает, содержит ли таблица ошибки
Locale
Свойство имеет тип CultureInfo и определяет региональные параметры, используемые таблицейпри сравнении строк
MinimumCapacity
Служит для получения или установки исходного количества строк таблицы (по умолчанию – 25 строк)
Если требуется вручную создать таблицу, то можно воспользоваться конструктором класса DataTable. Конструктор имеет перегруженную версию, которая позволяет установить имя таблицы – свойство TableName:
DataTable dt = new DataTable();
dt.TableName = "Main Table";
// аналогичный результат:
DataTable dt = new DataTable("Main Table");
Работа со свойствами Columns и Rows обсуждалась ранее. Свойства ChildRelations, ParentRelations, Constraints и PrimaryKey будут рассмотрены в следующем параграфе. При помощи свойства DataSet таблица связывается с определенным набором данных. Работа со свойством ExtendedProperties аналогична примерам, приводимым для класса DataColumn. Свойство таблицы HasErrors устанавливается в true, если хотя бы у одной из строк таблицы свойство HasErrors = true.
Кроме набора свойств, класс DataTable обладает следующими методами, перечисленными в таблице 30.
Таблица 30
Методы класса DataTable
Имя метода
Описание
AcceptChanges()
Метод фиксирует все изменения данных в строках таблицы, которые были проделаны с момента предыдущего вызова AcceptChanges()
BeginLoadData()
Отключает все ограничения при загрузке данных
Clear()
Уничтожаются все строки таблицы
Clone()
Метод клонирует структуру таблицы и возвращает таблицу без строк
Compute()
Метод применяет строку-выражение, заданную в качестве параметра, к диапазону строк таблицы
Copy()
Метод клонирует и структуру, и данные таблицы
EndLoadData()
Активирует ограничения после загрузки данных
GetChanges()
Метод возвращает таблицу с идентичной схемой, содержащую изменения, которые еще не зафиксированы методом AcceptChanges()
GetErrors()
Возвращает массив объектов DataRow, которые нарушают ограничения таблицы
ImportRow()
В таблицу вставляется строка, указанная в качестве параметра метода
LoadDataRow()
Добавляет или обновляет строку таблицы, основываясь на содержимом массива-параметра
NewRow()
Создается пустая строка по схеме столбцов таблицы
RejectChanges()
Метод отменяет изменения, которые еще не зафиксированы вызовом AcceptChanges()
Reset()
Восстанавливает оригинальное состояние объекта DataTable, в котором он находился до инициализации
Select()
Возвращает массив строк таблицы на основании заданного критерия поиска
Рассмотрим некоторые методы таблицы подробнее. Если в таблицу добавляется группа строк (объектов DataRow), то для повышения производительности кода следует применить методы BeginLoadData() и EndLoadData(). При вызове метода BeginLoadData() отключаются определенные на таблице ограничения. Активировать их можно, вызвав метод EndLoadData(). Если в таблице есть строки, нарушающие какие-либо ограничения, при вызове метода EndLoadData() генерируется исключение ConstraintException. Чтобы определить, какие именно строки нарушают ограничения, следует просмотреть массив, возвращаемый методом GetErrors().
Метод Clear() позволяет удалить из таблицы все строки. Вызвать его быстрее, чем освободить оригинальный и создать новый объект DataTable с идентичной структурой.
Метод Compute() позволяет выполнять агрегатные запросы к отдельным столбцам таблицы на основе заданных критериев поиска[36]. Метод принимает два строковых параметра. Первый содержит выражение для вычисления[37], второй является фильтром, отбирающим некий диапазон строк таблицы. Следующий пример кода загружает из базы CD_Rent таблицу Rent и вычисляет средний рейтинг диска с disk_id = 1:
SqlDataAdapter da = new SqlDataAdapter("SELECT * FROM Rent",
double r = (double) Rent.Compute("Avg(disk_rating)", "disk_id = 1");
Console.WriteLine(r);
Группа методов используется для добавления в таблицу новых строк. Метод таблицы ImportRow() принимает объект-строку и добавляет его в таблицу. Метод LoadDataRow() принимает в качестве первого аргумента массив, элементы которого соответствуют элементам коллекции Columns таблицы. Метод пытается найти в таблице строку, соответствующую своему первому аргументу и обновить ее. Если строка не найдена, она создается. Второй аргумент метода LoadDataRow() – это логическое значение, управляющее свойством RowState нового объекта DataRow. Чтобы задать свойству RowState значение Added, передайте в качестве второго аргумента false; если необходимо задать значение Unmodified, передайте true. Метод LoadDataRow() возвращает ссылку на созданную или найденную строку. Метод NewRow() возвращает для таблицы новую строку, но не добавляет его в коллекцию Rows таблицы. Добавление следует осуществить вручную, предварительно заполнив необходимые поля строки. Рекомендуется следующее:
· Для импорта строки из сторонней таблицы используйте метод ImportRow().
· Для одновременного импорта нескольких строк, например на основе содержимого файла, применяйте метод LoadDataRow(). Это позволит вам писать меньше кода, чем при работе с методом NewRow().
· Во всех остальных случаях вызывайте метод NewRow().
Любая таблица поддерживает следующий набор событий:
§ ColumnChanged – происходит после изменения содержимого поля некой строки;
§ ColumnChanging – перед изменением содержимого поля строки;
§ RowChanged – происходит после изменения содержимого строки;
§ RowChanging – генерируется перед изменением содержимого строки;
§ RowDeleted – происходит после удаления строки;
§ RowDeleting – происходит перед удалением строки.
События ColumnChanged и ColumnChanging наступают каждый раз, когда изменяется содержимое одного из полей строки. Они позволяют осуществлять проверку данных, активировать и деактивировать элементы управления, и т.д. У данных событий есть аргумент типа DataColumnChangeEventArgs, обладающий свойствами Row и Column, которые позволяют определить, какие именно поле и строка изменены. Помните: при использовании данных событий для редактирования содержимого строки иногда возникает замкнутый цикл.
События RowChanged и RowChanging наступают каждый раз, когда изменяется содержимое строки или значение свойства RowState строки. Чтобы определить, почему наступило событие, достаточно просмотреть значение свойства Action аргумента DataColumnChangeEventArgs этого события. Свойство Row указанного аргумента позволяет обращаться к изменяемой записи.
События RowDeleted и RowDeleting предоставляют такие же аргументы и свойства, как события RowChanged и RowChanging. Единственное отличие в том, что данные события наступают при удалении строки из таблицы.
4.12. DataSet и схема рассоединенного набора данных
Описав в предыдущих параграфах основные компоненты набора данных DataSet, рассмотрим этот класс более подробно. Начнем с таблицы свойств класса DataSet.
Таблица 31
Свойства класса DataSet
Имя свойства
Описание
CaseSensitive
Определяет, учитывается ли регистр при поиске строк
DataSetName
Строка с именем набора данных
EnforceConstraints
Определяет, обеспечивает ли DataSet выполнение определенных на нем ограничений
ExtendedProperties
Коллекция пользовательских свойств набора данных
HasErrors
Указывает, содержит ли набор данных ошибки
Locale
Свойство имеет тип CultureInfo и определяет региональные параметры, используемые набором данныхпри сравнении строк
Relations
Коллекция отношений, связывающих таблицы из набора данных
Tables
Возвращает коллекцию таблиц набора данных
Большинство свойств в особых пояснениях не нуждается, ибо, по сути, является аналогом свойств таблицы, но для всего набора данных. Свойство Relations содержит коллекцию связей между таблицами и является часть описания схемы данных. Если значение свойства EnforceConstraints установить в false, то при загрузке информации в DataSet данные не будут проверяться на соответствие ограничениям. Это повышает производительность.
В таблице 32 перечислены методы набора данных:
Таблица 32
Методы класса DataSet
Имя метода
Описание
AcceptChanges()
Метод фиксирует все изменения данных, которые были проделаны с момента предыдущего вызова AcceptChanges()
Clear()
Уничтожаются все строки всех таблиц набора данных
Clone()
Метод клонирует структуру набора и возвращает пустой набор
Copy()
Метод клонирует и структуру, и данные набора
GetChanges()
Возвращает новый DataSet с идентичной схемой, содержащий измененные строки и таблицы оригинального объекта DataSet
GetXml()
Возвращает содержимое объекта DataSet в виде XML-строки
GetXmlSchema()
Возвращает схему объекта DataSet в виде XML-строки
HasChanges()
Возвращает логическое значение, указывающее, содержат ли строки из состава DataSet отложенные изменения
Merge()
Осуществляет слияние данных из другого объекта DataSet, DataTable или массива объектов DataRow и данных текущего объекта DataSet
ReadXml()
Читает содержимое DataSet в XML-формате из файла, Stream, TextReader или XmlReader
ReadXmlSchema()
Работает как ReadXml(), но читает только схему DataSet
RejectChanges()
Метод отменяет изменения, которые еще не зафиксированы вызовом AcceptChanges()
Reset()
Восстанавливает оригинальное состояние DataSet
WriteXml()
Записывает содержимое DataSet в XML-формате в файл, Stream, TextWriter или XmlWriter
WriteXmlSchema()
Работает как WriteXml(), но записывает только схему DataSet
Рассмотрим, как вручную задать схему набора данных. Напомним, что правильная схема включает тип и имя отдельных столбцов таблицы, ограничения на столбцы и связи между таблицами. Будем создавать схему для таблиц Artists и Disks из базы CD_Rent.
Вначале создадим объекты, соответствующие столбцам и таблицам, и поместим столбцы в таблицы:
DataColumn id_artists = new DataColumn("id", typeof(int));
DataColumn name = new DataColumn("name", typeof(string));
DataTable Artists = new DataTable("Artists");
Artists.Columns.Add(id_artists);
Artists.Columns.Add(name);
DataColumn id_disks = new DataColumn("id", typeof(int));
DataColumn title = new DataColumn("title", typeof(string));
DataColumn artist_id = new DataColumn("artist_id",
Теперь можно выполнить дополнительную настройку отдельных столбцов – задать максимальную длину, отсутствие нулевых значений:
id_artists.AllowDBNull = false;
name.AllowDBNull = false;
id_disks.AllowDBNull = false;
title.AllowDBNull = false;
name.MaxLength = 50;
title.MaxLength = 50;
release_year.MaxLength = 4;
Перейдем к работе с таблицами. Как и в реляционных база данных, один или несколько столбцов таблицы DataTable могут исполнять роль первичного ключа. Первичный ключ должен быть уникальным в пределах таблицы. Свойство таблицы PrimaryKey служит для получения или установки массива столбцов, формирующих первичный ключ. Если столбец является частью первичного ключа, его свойство AllowDBNull автоматически устанавливается в false. Установим первичные ключи наших таблиц:
DataColumn[] Artists_PK = new DataColumn[1] {id_artists};
Artists.PrimaryKey = Artists_PK;
DataColumn[] Disks_PK = new DataColumn[1] {id_disks};
Disks.PrimaryKey = Disks_PK;
Таблица поддерживает свойство Constraints – набор ограничений таблицы. Значением данного свойства является коллекция объектов класса Constraint. Класс Constraint – абстрактный базовый класс, имеющий два производных класса: ForeignKeyConstraint и UniqueConstraint.
Класс UniqueConstraint – это класс, при помощи объектов которого реализуется концепция уникальности значений полей строки. Основными свойствами этого класса является массив столбцов Columns, имя ограничения ConstraintName и булево свойство IsPrimaryKey, которое показывает, представляет ли данное ограничение первичный ключ таблицы. Ограничение вида UniqueConstraint автоматически добавляется в таблицу при создании первичного ключа. Это же ограничение появляется, если в таблицу добавляется столбец с установленным свойством Unique.
Так как в нашем примере мы уже создали первичные ключи таблиц, то их коллекции Constraints не пусты. Изменим имя ограничения в одной из таблиц и добавим ограничение для столбца name таблицы Artists, полагая значения в этом столбце уникальными:
Управляет каскадированием изменений родительской строки в дочерние строки
Свойства AcceptRejectRule, DeleteRule и UpdateRule управляют порядком каскадирования изменений родительской строки в дочерние строки. Свойство AcceptRejectRule принимает значение из одноименного перечисления. Значение этого свойства по умолчанию – None: вызов метода AcceptChanges() или RejectChanges() объекта DataRow не сказывается на дочерних строках последнего. Если задать свойству AcceptRejectRule значение Cascade, изменения каскадируются в дочерние строки, определенные объектом ForeignKeyConstraint.
Свойства DeleteRule и UpdateRule функционируют аналогичным образом, но принимают значения из перечисления Rule. Значение этих свойств по умолчанию – Cascade, т. е. изменения родительской строки каскадируются в дочерние строки. Например, при вызове метода Delete() родительского объекта DataRow вы неявно вызываете и метод Delete() его дочерних строк. Точно так же, редактируя значение поля ключа родительского объекта DataRow, вы неявно изменяете содержимое соответствующих полей дочерних строк. Если каскадировать изменения не требуется, задайте свойствам DeleteRule и UpdateRule значение None. Можно также задать им значение SetNull или SetDefault. В первом случае при изменении или удалении содержимого родительской строки соответствующим полям дочерних строк задаются значения NULL, а во втором – их значения по умолчанию.
Обычно нет необходимости создавать объекты класса ForeignKeyConstraint вручную. Они генерируются автоматически при добавлении связи между таблицами.
Связь между таблицами представлена объектом класса DataRelation. Большинство свойств DataRelation доступно только для чтения. Задать их значение можно средствами конструкторов объекта DataRelation. В таблице 34 перечислены наиболее часто используемые свойства.
Таблица 34
Свойства класса DataRelation
Имя свойства
Описание
ChildColumns
Свойство возвращает массив, содержащий объекты DataColumn из дочернего объекта DataTable
ChildKeyConstraint
Указывает ограничение FOREIGN KEY в дочерней таблице
ChildTable
Указывает дочернюю таблицу связи
DataSet
Набор данных, в котором находится объект DataRelation
ExtendedProperties
Набор динамических свойств
Nested
Логическое значение. Указывает, нужно ли преобразовывать дочерние строки в дочерние элементы при записи содержимого DataSet в XML-файл
ParentColumns
Родительские столбцы, определяющие отношение
ParentKeyConstraint
Указывает ограничение UNIQUE в родительской таблице
ParentTable
Указывает родительскую таблицу
RelationName
Строка с именем отношения
При создании объекта DataRelation следует указать его имя, чтобы объект удалось найти в наборе; кроме этого, необходимо указать родительский и дочерний столбцы, на которых будет основано отношение. Чтобы упростить создание связей, класс DataRelation предоставляет отдельные конструкторы, принимающие как объекты DataColumn, так и массивы таких объектов.
Вернемся к нашему примеру. Создадим рассоединенный набор данных и поместим в него таблицы:
DataSet CD_Rent = new DataSet("CD_Rent_Part");
CD_Rent.Tables.Add(Artists);
CD_Rent.Tables.Add(Disks);
Между таблицами Artists и Disks существует связь по внешнему ключу. А именно, таблица Disks является дочерней для таблицы Artists, так как значения поля artist_id – это значения первичного ключа таблицы Artists. Создадим объект DataRelation, описывающий эту связь:
// Используем самый простой конструктор, который устанавливает
// имя отношения, родительский и дочерний столбцы отношения
DataRelation Artists_to_Disks = new DataRelation(
"Artists_to_Disks",
id_artists, artist_id);
// Добавим отношение в набор данных
CD_Rent.Relations.Add(Artists_to_Disks);
После выполнения данного кода коллекция Constraints объекта Artists будет содержать два отношения с именами Primary Key и Unique Artist Name (оба – класса UniqueConstraint). Коллекция Constraints объекта Disks будет также содержать два отношения. Одно – с именем Constraint1 типа UniqueConstraint, второе – с именем Artists_to_Disks типа ForeignKeyConstraint. Создание схемы данных можно считать завершенным. При желании можно добавить обработчики событий в наши таблицы.
При помощи метода адаптера WriteXmlSchema() созданную схему можно сохранить в XML-файле (правильным расширеним файла является *.xsd, так как схема сохраняется в виде XSD-описания).
4.13. Типизированные DataSet
В обычных объектах DataSet для доступа к отдельным элементам используются индексированные коллекции. Недостатком такого подхода является отсутствие контроля правильности имен таблиц и столбцов во время компиляции.
Платформа .NET поддерживает типизированные наборы данных. Типизированный набор данных – это класс, который является наследником класса DataSet. В отличие от DataSet, в типизированном наборе для доступа к отдельным компонентам служат свойства. Имя свойства – это имя элемента DataSet (например, имя таблицы), тип свойства – класс-наследник стандартного класса из DataSet.
Создать типизированный DataSet можно несколькими способами. В Visual Studio для этого используется специальный мастер (wizard). В состав .NET Framework SDK входит утилита xsd.exe, формирующая типизированные наборы данных на основании XSD-файла со схемой набора.
Разберем пример использования xsd.exe. Пусть есть набор данных со схемой, построенной в предыдущем параграфе и сохраненной в файле schema.xsd. Выполним команду[38]:
C:\TMP>xsd schema.xsd /d
В результате получим файл schema.cs, фрагмент которого приведен ниже:
public class ArtistsDataTable: DataTable,IEnumerable {...}
public class ArtistsRow : DataRow {. . .}
public class DisksDataTable : DataTable, IEnumerable {...}
public class DisksRow : DataRow {. . .}
}
Используя файл schema.cs и класс CD_Rent_Part, работать с набором данных можно следующим образом. Вместо кода, подобного следующему,
string s = (string) CD_Rent.Tables["Artists"].Rows[0]["name"];
можно писать такой код:
CD_Rent_Part cd = new CD_Rent_Part();
string s1 = cd.Artists[0].name;
Обратите внимание:
1.Таблица представлена свойством Artists (типа ArtistsDataTable).
2.Для доступа к определенной строке таблицы используется индексатор, примененный к свойству Artists.
3.Тип строки – ArtistsRow. Это позволяет обратиться к полю строки как к свойству и не выполнять приведение типов.
Подытожим: типизированные DataSet позволяют установить контроль правильности кода во время компиляции. Это способно упростить разработку приложений и сделать использование типов более безопасным.
4.14. Поиск и фильтрация данных В DataSet
В примерах данного параграфа предполагается, что имеется DataSet с заданной схемой (см. параграф 12), и в этот набор данных загружены две таблицы из базы CD_Rent:
da.SelectCommand.CommandText = "SELECT * FROM Disks";
da.Fill(CD_Rent, "Disks");
Наличие в схеме данных связей между таблицами позволяет осуществлять навигацию по набору данных. Для этого используются методы GetChildRows(), GetParentRow() и GetParentRows() класса DataRow.
Метод GetChildRows() возвращает массив дочерних строк той строки, у которой вызывается. Метод принимает в качестве параметра имя связи между таблицами либо объект, описывающий связь. В следующем фрагменте кода для каждого исполнителя выводится список его дисков:
foreach (DataRow row in Artists.Rows) {
Console.WriteLine(row["name"]);
DataRow[] childRows =
row.GetChildRows("Artists_to_Disks");
foreach (DataRow r in childRows)
Console.WriteLine("\t" + r["title"]);
}
Метод GetParentRow() позволяет получить родительскую строку. Как и предыдущий метод, GetParentRow() принимает в качестве параметра имя связи между таблицами либо объект, описывающий связь. В примере для каждого диска выводится его исполнитель:
Метод GetParentRows() возвращает все родительские строки определенной строки. Данный метод имеет смысл использовать, если задана такая связь, при которой колонка родительской таблицы не является первичным ключом (не уникальна).
Все три рассмотренных метода имеют перегруженные варианты, которые позволяют получить заданную версию строки. Версия указывается в качестве дополнительного параметра.
Достаточно часто возникает задача поиска информации в таблице или наборе данных. Для этого можно использовать два метода. Первый метод – Find() – позволяет искать строки по значениям первичного ключа. Второй – Select(), выступает в качестве фильтра, возвращая строки данных, удовлетворяющие критериям поиска.
Метод Find(), который предоставляет класс DataRowCollection ищет строки таблицы с определенным значением первичного ключа. Метод Find() принимает как параметр значение первичного ключа искомой строки. Поскольку значения первичного ключа уникальны, метод вернет не более одного объекта DataRow. Следующий фрагмент кода ищет данные в таблице Artists:
// В Artists определен первичный ключ.
// Find() принимает как параметр объект
// и сам приводит его к нужному типу
DataRow row = Artists.Rows.Find(1);
if (row != null) Console.WriteLine(row["name"]);
Метод Find() перегружен в расчете на случаи, когда первичный ключ DataTable состоит из нескольких объектов DataColumn. В этом случае в Find() передается массив объектов, представляющих значения первичного ключа.
Метод Select() класса DataTable позволяет искать ряды по определенному критерию. В простейшем случае методу передается строка, описывающая критерий поиска. Метод возвращает массив найденных строк. В следующем примере из таблицы Disks выбираются все диски, записанные в 2006 году:
DataRow[] result = Disks.Select("release_year = 2006");
foreach (DataRow row in result)
Console.WriteLine(row["title"]);
Несколько слов о построении строки-критерия. Строка может содержать слово LIKE, которое осуществляет поиск по частичному совпадению. В этом случае используется шаблон, содержащий метасимволы * или % для обозначения начальной или конечной части строки. Например, осуществим поиск всех дисков, название которых начинается с "U":
DataRow[] result = Disks.Select("title LIKE 'U*'");
Иногда требуется заключить в символы-разделители имена столбцов, используемые в критерии поиска. Например, когда имя содержит пробел или другой символ, не относящийся к алфавитно-цифровым, или похоже на зарезервированное слово типа LIKE или SUM. Так, если имя столбца – Space In Name и требуется выбрать все строки, значение поля Space In Name которых равно 3, воспользуйтесь следующим критерием поиска:
strCriteria = "[Space In Name] = 3"
Если имя столбца включает символ-разделитель, поставьте в критерии поиска перед закрывающим символом-разделителем (]) управляющий символ (\). Например, если имя столбца – Bad]Column[Name и требуется выбрать все строки, у которых значение этого поля равно 5, используйте такую строку поиска:
strCriteria = @"[Bad\]Colunin[Name] = 5";
Метод Select() перегружен. Вы можете просто передать строку запроса, а можете включить в нее порядок сортировки, а также параметр, определяющий состояние искомых строк (например, только добавленные строки или только измененные).
Управлять порядком строк, возвращаемых Select(), можно посредством одной из сигнатур перегруженного метода. Следующий фрагмент получает массив строк, отсортированных в убывающем порядке по полю title:
DataRow[] result = Disks.Select("release_year = 2005", "title DESC");
Если надо выполнить поиск только в измененных строках таблицы, воспользуйтесь перегруженным методом Select() и укажите значение из перечисления DataViewRowState. Можно считать, что это значение – фильтр, добавленный в критерий поиска. Предположим, требуется просмотреть только измененные и удаленные записи таблицы. Воспользуемся константами ModifiedOriginal и Deleted из перечисления DataViewRowState и укажем в качестве параметров фильтрации и сортировки пустые строки:
DataRow[] result = Disks.Select("", "",
DataViewRowState.ModifiedOriginal |
DataViewRowState.Deleted);
4.15. Класс DataView
Метод DataTable.Select() – очень мощный и гибкий, но не является оптимальным решением для всех ситуаций. У него есть два основных ограничения. Во-первых, метод принимает динамические критерии поиска и поэтому не может быть сверхэффективным. Во-вторых, Windows- и Web-формы не поддерживают связывание с возвращаемым значением метода Select() – массивом объектов DataRow. В ADO.NET предусмотрено решение, обходящее оба этих ограничения – объект класса DataView.
Объекты DataView позволяют фильтровать, сортировать и вести поиск в содержимом таблиц. Объекты DataView не являются SQL-запросами, в отличие от представлений (view) в базах данных. С помощью DataView нельзя объединить данные двух таблиц, равно как и просмотреть отдельные столбцы таблицы. Объекты DataView поддерживают фильтрацию запросов на основе динамических критериев, но разрешают обращаться только к одному объекту DataTable; кроме того, через DataView всегда доступны все столбцы таблицы. У объекта DataView нет собственной копии данных. При обращении через DataView к данным он возвращает записи, хранящиеся в соответствующем объекте DataTable.
Чтобы просмотреть с помощью объекта DataView данные некоторой таблицы, его следует связать с этой таблицей. Есть два способа сделать это: используя свойство Table объекта DataView или при помощи конструктора DataView. Следующие фрагменты эквивалентны:
DataTable dt = CD_Rent.Tables["Disks"];
// Первый вариант
DataView dv = new DataView();
dv.Table = dt;
// Второй вариант
DataView dv = new DataView(dt);
У DataView также есть конструктор, сигнатура которого более точно соответствует методу DataTable.Select(). Этот конструктор задает значения свойств Table, RowFilter, Sort и RowStateFilter объекта DataView в одной строке кода. Следующие варианты кода эквивалентны:
DataView dv = new DataView(dt, "release_year = 2005",
"title DESC",
DataViewRowState.ModifiedOriginal);
Свойство RowStateFilter принимает значения из перечисления DataViewRowState. Это перечисление можно рассматривать как комбинацию свойства RowState объекта DataRow и перечисления DataRowVersion.
· Added – отображаются добавленные строки;
· CurrentRows – отображаются строки, которые не были удалены (значение по умолчанию);
· Deleted – отображаются удаленные строки;
· ModifiedCurrent – отображаются измененные строки с их текущими значениями;
· ModifiedOriginal – отображаются измененные строки с их оригинальными значениями;
· None – строки не отображаются;
· OriginalRows – отображаются удаленные, измененные и не изменявшиеся строки с их оригинальными значениями;
· Unchanged – отображаются строки, которые не изменялись.
Свойство RowStateFilter работает в качестве двойного фильтра. Например, если задать ему значение ModifiedOriginal, через объект DataView окажутся доступны только измененные записи, и вы будете видеть их оригинальные значения.
Объект DataView возвращает данные с помощью собственного специализированного объекта – DataRowView. Функциональность DataRowView в целом аналогична функциональности DataRow. DataRowView обладает свойством Item, позволяющим обращаться к содержимому поля как по имени, так и по порядковому номеру. И хотя свойство Item разрешает просматривать и изменять содержимое поля, через DataRowView доступна только одна версия данных строки – та, которая указана при помощи свойства DataRowVersion. Если объект DataRowView не обеспечивает требуемых возможностей, обратитесь при помощи свойства Row этого объекта к соответствующему объекту DataRow из таблицы.
Доступ к данным объекта DataTable при помощи DataView осуществляется иначе, чем непосредственный доступ к объекту DataTable. Таблица предоставляет свои строки через свойство Rows. У DataView нет похожего, допускающего простое перечисление, набора. DataView имеет свойство Count, возвращающее число строк, и индексатор Item с целым индексом. Используя эти свойства, можно создать простой цикл для просмотра всех строк:
DataView dv = new DataView(dt, "release_year = 2005",
"title DESC",
DataViewRowState.CurrentRows);
for (int i = 0; i < dv.Count; i++) {
DataRowView drv = dv[i];
Console.WriteLine(drv["title"]);
}
Класс DataView предоставляет методы Find() и FindRows(), позволяющие искать в нем данные. Эти методы аналогичны методу Find() коллекции Rows таблицы. Задав значение свойства Sort объекта DataView, вы получите возможность с помощью метода Find() искать строки по значениям столбцов, перечисленных в свойстве Sort. Как и в случае с методом DataRowCollection.Find(), одноименному методу DataView разрешено передавать одно значение или массив значений. Тем не менее, метод DataView.Find() возвращает не объект DataRow или DataRowView, а значение целого типа, соответствующее порядковому номеру нужной строки в объекте DataView. Если искомая строка не найдена, метод вернет -1:
DataTable dt = CD_Rent.Tables["Disks"];
DataView dv = new DataView(dt);
dv.RowFilter = "release_year = 2005";
dv.Sort = "title";
int findIndex = dv.Find("Mezmerize");
if (findIndex != -1)
Console.WriteLine(dv[findIndex]["artist_id"]);
Метод DataView.Find() осуществляет поиск по столбцам, указанным в свойстве Sort. У многих строк могут быть одинаковые значения полей, используемых для сортировки данных. Например, при сортировке дисков по полю release_year это поле может иметь значение "2005" для нескольких строк. Тем не менее, найти посредством метода Find() все диски, выпущенные в 2005 году нельзя, поскольку он возвращает только целочисленное значение. К счастью, класс DataView предоставляет метод FindRows(). Его вызывают так же, как и метод Find(), но метод FindRows() возвращает массив объектов DataRowView, содержащих строки, которые удовлетворяют критериям поиска.
DataTable dt = CD_Rent.Tables["Disks"];
DataView dv = new DataView(dt);
dv.RowFilter = "release_year = 2005";
dv.Sort = "release_year";
DataRowView[] res = dv.FindRows("2005");
if (res.Length != 0)
Console.WriteLine("Find {0} rows", res.Length);
Строка данных модифицируется с помощью объекта DataRowView аналогично изменению содержимого объекта DataRow. Объект DataRowView, как и DataRow, предоставляет методы BeginEdit(), EndEdit(), CancelEdit() и Delete(). Создание новой строки данных при помощи объекта DataRowView несколько отличается от создания нового объекта DataRow. У класса DataView есть метод AddNew(), возвращающий новый объект DataRowView. В действительности же новая строка добавляется в базовый объект DataTable только при вызове метода EndEdit() объекта DataRowView. Ниже показано, как средствами объекта DataRowView создать, изменить и удалить строку данных:
// Создание новой строки с использованием DataView
DataRowView drv = dv.AddNew();
drv[0] = 10;
drv[1] = "Hipnotize";
drv.EndEdit();
// Получение и редактирование строки
drv = dv[1];
drv.BeginEdit();
drv[1] = "H";
drv.EndEdit();
// Получение и удаление строки
drv = dv[0];
drv.Delete();
В таблице 35 приведено краткое описание основных свойств и методов класса DataView.
Таблица 35
Свойства и методы класса DataView
Имя свойства
или метода
Описание
AddNew()
Создает новый объект DataRowView
AllowDelete
AllowEdit
AllowNew
Булевы свойства; указывают, допустимо ли удаление, изменение или добавление записей в объект DataView
ApplyDefaultSort
Если задать свойству значение true, содержимое DataView сортируется по первичному ключу таблицы, связанной с DataView. Кроме того, если изменить значение свойства на true, свойству Sort будут заданы столбцы, составляющие первичный ключ связанной таблицы
BeginInit()
Временно кэширует изменения содержимого DataView
CopyTo()
Позволяет копировать объекты DataRowView, доступные через DataView, в массив
Count
Возвращает число записей в DataView (доступно только для чтения)
Delete()
Метод принимает порядковый номер строки в объекте DataView и удаляет эту строку из базового объекта DataTable
EndInit()
Подтверждает внесение кэшированных изменений в DataView
Find()
Выполняет в DataView поиск отдельной строки данных
FindRows()
Выполняет в DataView поиск нескольких строк данных
GetEnumerator()
Возвращает экземпляр объекта IEnumerator для просмотра строк DataView
Item
Индексатор, возвращает объекты DataRowView, доступные через DataView
RowFilter
Свойство аналогично разделу WHERE SQL-запроса. Через DataView доступны только строки, удовлетворяющие заданному в свойстве критерию. Значение свойства по умолчанию – пустая строка
RowStateFilter
Указывает, какие строки доступны через объект DataView, а также версию этих строк
Sort
Свойство определяет порядок сортировки данных, доступных через DataView, и функционирует аналогично разделу ORDER BY SQL-запроса
Table
Таблица, с которой связан объект DataView
4.16. СИНхронизация набора данных и базы
Пусть в набор данных заносится информация из БД при помощи адаптера:
SqlDataAdapter da = new SqlDataAdapter(. . .);
DataSet CD_Rent = new DataSet("CD_Rent");
da.Fill(CD_Rent, "Artists");
Для переноса изменений из набора в базу используется метод адаптера Update(). Данный метод обновляет в базе одну таблицу набора (всегда!), которая, как правило, задается через параметр метода. Однако попытка выполнения следующего кода вызовет исключительную ситуацию:
System.InvalidOperationException: Update requires a valid
UpdateCommand when passed DataRow collection with modified rows.
Дело в том, что при создании адаптера формируется только SelectCommand – команда для выборки данных. Остальные свойства-команды адаптера не инициализированы.
Программист может настроить необходимые команды вручную. Вначале рассмотрим SQL-синтаксис возможных команд для обновления информации в нашем примере:
INSERT INTO Artists(id ,name) VALUES (@p1, @p2)
DELETE FROM Artists WHERE (id = @p1) AND (name = @p2)
UPDATE Artists SET id = @p1, name= @p2
WHERE (id= @p3) AND (name= @p4)
В принципе, этот текст можно скопировать в свойство CommandText команд, которые будут созданы. Отдельного пояснения требует настройка параметров. Параметр, кроме установки таких свойств как имя и тип, должен быть связан со столбцом таблицы из набора данных, а в случае с командой UPDATE – еще и с определенной версией информации в столбце. Для этого используются свойства параметра SourceColumn и SourceVersion. Приведем полный текст создания и настройки команд:
// Создали соединение, которое будут использовать наши команды
SqlConnection con = newSqlConnection(. . .);
// Создали три объекта-команды
SqlCommand ins_cmd = con.CreateCommand();
SqlCommand del_cmd = con.CreateCommand();
SqlCommand upd_cmd = con.CreateCommand();
// Настраиваем текст команд
ins_cmd.CommandText = "INSERT INTO Artists(id,name) VALUES (@p1,@p2)";
del_cmd.CommandText = "DELETE FROM Artists" +
"WHERE (id=@p1) AND (name=@p2)";
upd_cmd.CommandText = "UPDATE Artists SET id=@p1, name= @p2" +
"WHERE (id= @p3) AND (name= @p4)";
// Займемся параметрами
// Создадим два параметра и поместим их в коллекцию
ins_cmd.Parameters.Add("@p1", DbType.Int32);
ins_cmd.Parameters.Add("@p2", DbType.String);
// Дополнительная настройка – укажем столбец, из которого
// берется значение параметра
ins_cmd.Parameters[0].SourceColumn = "id";
ins_cmd.Parameters[1].SourceColumn = "name";
// В случае с командой удаления – аналогичные действия
del_cmd.Parameters.Add("@p1", DbType.Int32);
del_cmd.Parameters.Add("@p2", DbType.String);
del_cmd.Parameters[0].SourceColumn = "id";
del_cmd.Parameters[1].SourceColumn = "name";
// Для команды обновления число параметров в два раза больше
upd_cmd.Parameters.Add("@p1", DbType.Int32);
upd_cmd.Parameters.Add("@p2", DbType.String);
upd_cmd.Parameters.Add("@p3", DbType.Int32);
upd_cmd.Parameters.Add("@p4", DbType.String);
upd_cmd.Parameters[0].SourceColumn = "id";
upd_cmd.Parameters[1].SourceColumn = "name";
upd_cmd.Parameters[2].SourceColumn = "id";
upd_cmd.Parameters[3].SourceColumn = "name";
// Требуется настройка – указать версию поля таблицы
После того, как в адаптере определены все команды, можно свободно изменять данные в рассоединенном наборе, а затем обновить их в базе вызовом Update():
DataTable dt = CD_Rent.Tables["Artists"];
DataRow row = dt.NewRow();
row["id"] = 100;
row["name"] = "Uma Thurman";
dt.Rows.Add(row);
row = dt.Rows[1];
row["name"] = "Alex";
da.Update(CD_Rent, "Artists");
Как показывает пример, ручное создание команд для адаптера даже в случае простого набора данных выглядит громоздким (хотя это очень гибкое решение). ADO.NET предоставляет класс для автоматической генерации команд адаптера. Это класс CommandBuilder (класс зависит от поставщика данных, поэтому приведено его «обобщенное» имя).
Работа с классом CommandBuilder происходит следующим образом. Создается объект класса и связывается с определенным адаптером данных, у которого уже задана команда SelectCommand. После установки подобной связи CommandBuilder отслеживает событие обновления строки данных, которое происходит при вызове метода Update(), и генерирует и выполняет необходимые SQL-команды на основе текста команды SELECT.
Приведем пример кода, использующего CommandBuilder. Вот как могла бы выглядеть «генерация» команд для адаптера, с которым мы работали:
// Создаем объект CommandBuilder и связываем его с адаптером
SqlCommandBuilder cb = new SqlCommandBuilder(da);
// И, собственно, все! Можем работать с методом Update()
. . .
da.Update(CD_Rent, "Artists");
Конечно, класс CommandBuilder не «всемогущ». Он генерирует правильные команды обновления, если выполняются все следующие условия:
· запрос возвращает данные только из одной таблицы;
· на таблице в базе определен первичный ключ;
· первичный ключ есть в результатах вашего запроса.
Кроме этого, объект CommandBuilder не предоставляет максимальной производительности периода времени выполнения. Вы можете написать и добавить в код собственную логику обновления за время, меньшее, чем объекту CommandBuilder потребуется, чтобы выбрать и обработать необходимые для создания аналогичного кода метаданные таблицы из БД. CommandBuilder не позволяет управлять генерацией логики. Нельзя указать нужный способ оптимистического управления параллелизмом. Нельзя передавать обновления средствами хранимых процедур.
В таблице 36 приведены свойства и методы класса SqlCommandBuilder.
Таблица 36
Свойства и методы класса SqlCommandBuilder
Имя свойства
или метода
Описание
DataAdapter
Свойство позволяет просмотреть или изменить объект DataAdapter, сопоставленный с объектом CommandBuilder. Значение этого свойства можно задать в конструкторе объекта CommandBuilder
DeriveParameters()
Статический метод. Получает в качестве параметра объект-команду для вызова хранимой процедуры. На основании информации из БД, заполняет коллекцию Parameters команды-параметра
GetDeleteCommand()
Возвращает объект Command с логикой для свойства DeleteCommand объекта DataAdapter
GetInsertCommand()
Возвращает объект Command с логикой для свойства InsertCommand объекта DataAdapter
GetUpdateCommand()
Возвращает объект Command с логикой для свойства UpdateCommand объекта DataAdapter
QuotePrefix
Содержит префикс, используемый CommandBuilder для имен таблиц и столбцов в генерируемых им запросах
QuoteSuffix
Содержит суффикс, используемый CommandBuilder для имен таблиц и столбцов в генерируемых им запросах
RefreshScbema()
Указывает объекту CommandBuilder создать логику обновления заново